

2024年3月の記事一覧


無礼なプロンプトはNG!言葉の力でAIの反応が変わる!LLMと人間のコミュニケーションにおけるプロンプトの礼儀レベルが性能に及ぼす影響
最新研究が示す驚きの事実:私たちがAIに話しかける方法、つまりプロンプトの言葉遣いが、AIの性能や反応品質に大きく影響していることが明らかになりました!早稲田大学の研究チームは、「Should We Respect LLMs? A Cross-Lingual Study on the Influence of Prompt Politeness on LLM Performance」と題した研究で
もっとみる
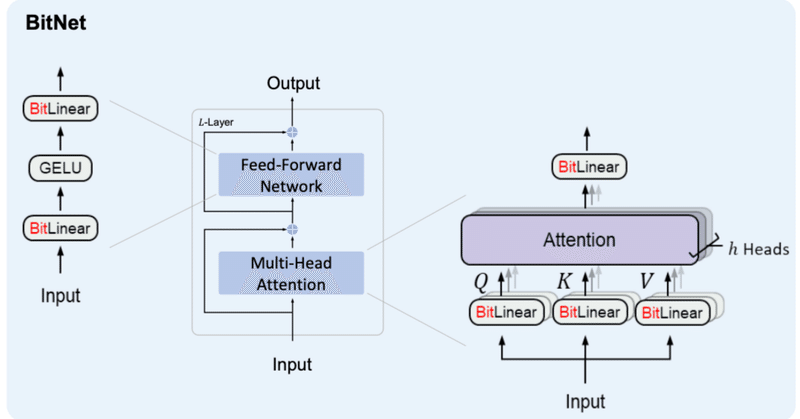
BitNet&BitNet b158の実装④
はじめに前回、BitLinear b158の実装を行いました。前回までの内容は以下をご参照ください。
4. BitNet b158の検証BitNetの検証と同様、
BitLlamaでBitLinear158bを利用できる様に修正
事前学習ができるか(Lossが下がるか)確認
を行います。
4-1. BitLlamaの修正
modeling_bit_llama.pyにおいて、BitLin



MLX で RakutenAI-7B を試す
「MLX」で「RakutenAI-7B」を試したので、まとめました。
1. RakutenAI-7B「RakutenAI-7B」は、楽天が開発した日本語LLMです。
2. 推論の実行「MLX」は、Appleが開発した新しい機械学習フレームワークで、「Apple Silicon」(M1/M2/M3など) を最大限に活用するように設計されています。
推論の実行手順は、次のとおりです。
(1)
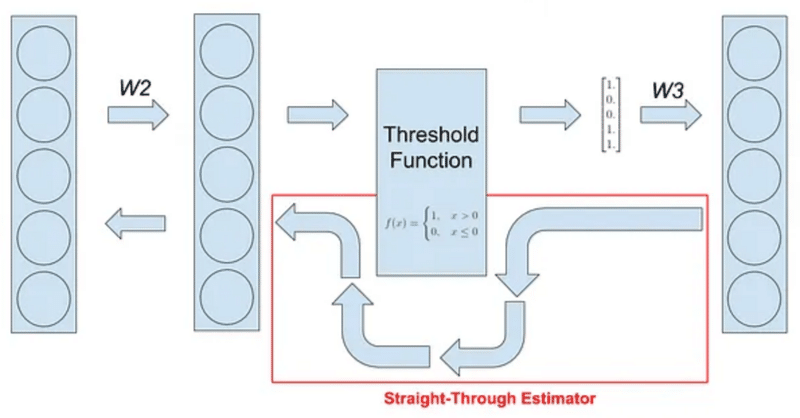
BitNetにおけるSTE(Straight-Through Estimator)の実装
はじめに現在、私は以下のような試みをしています。
BitNetとは
BitNetとはweightとactivationを量子化する手法の1つで、特にweightを{-1, 0, 1}の3値に量子化するBitNet b158はベースとしているLlama2の性能を上回ることを示し、注目を浴びました。
その実装の中で、量子化(つまりFloat16や32ではなくより離散的な値を扱う様にする処理)を行


LoRAに関する論文をなんJ風に解説してまとめてみた
はじめに論文をなんJ風に解説してもらうと驚くほどわかりやすくなるようなので、LoRAに関する論文(LoRA改良版など)で試してみました。今回は、Claude 3とChatGPT4を使ってまとめと比較表を作成します。
こちらは論文を読むのが苦手な方に向けた記事です。ClaudeおよびChatGPTは間違いを犯すことがありますので、正確な情報は参照論文を確認してください。
なんJ風のプロンプトは、


LoRAよりいいらしいLISA
LISAという手法がLoRAより高性能らしく、場合によってはフルパラメータチューニングに匹敵するという
https://arxiv.org/pdf/2403.17919.pdf 以下、図版は全てこの論文から
Llama2-70Bにおける比較
確かに、Llama2-70B-FT(フルパラメータチューニング)よりもLISAの方が成績が良くなっている。
その上、メモリー消費量はLoRAより低い




【論文瞬読】進化的アルゴリズムが切り拓く、AIモデルの自動合成による新時代
こんにちは!株式会社AI Nestです。
本日は、元Googleの研究者が東京を拠点に始めたAIスタートアップ「Sakana AI」が発表した興味深い論文について紹介したいと思います。タイトルは「Evolutionary Optimization of Model Merging Recipes」。要するに、進化的アルゴリズムを使って、複数のAIモデルを組み合わせ、新しい能力を持った強力な基盤モデ
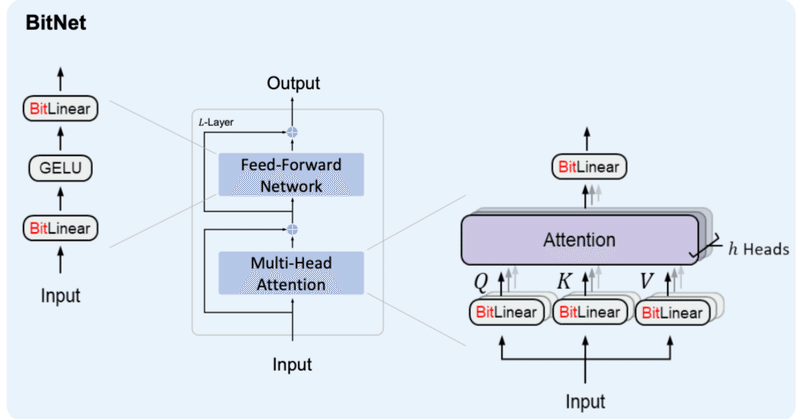
BitNet&BitNet b158の実装③
はじめにBitNetおよびBitNet b158の実装を続けていこうと思います。
ボリュームが大きくなってきたため、記事を分けることとしました。前回までの内容は以下をご参照ください。
2日連続での投稿となるので前後関係をお気をつけください。
3. BitNet b158これまでに作成したBitLinearを修正していく形でBitNet b158用のBitLinear b158を作成していきます。
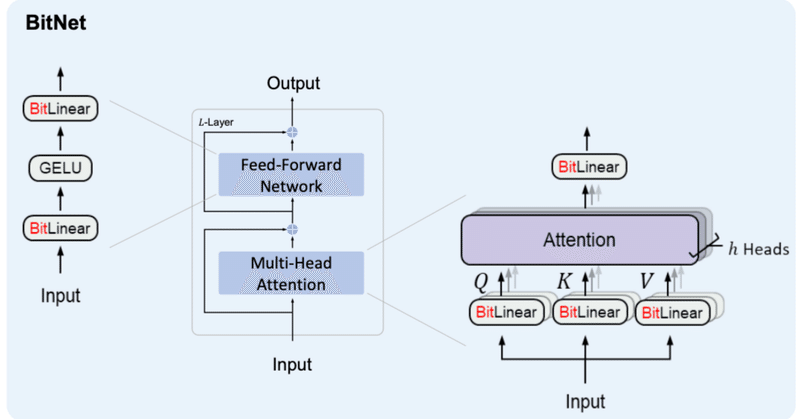
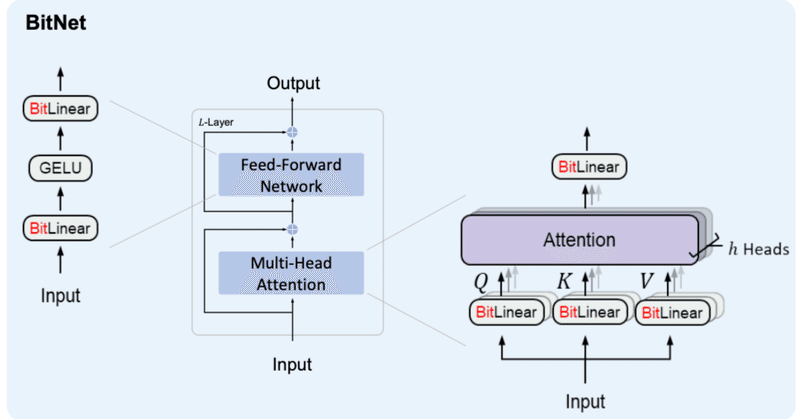
BitNet&BitNet b158の実装②
はじめに少し間が空いてしまいましたが、BitNetおよびBitNet b158の実装を続けていこうと思います。
ボリュームが大きくなってきたため、ページを分けることとしました。前回までの内容は以下をご参照ください。
2. BitNetの検証今回は、前回作ったBitNetの検証を進めていこうと思います。
検証内容としては、
BitLlamaの構築
事前学習ができるか(Lossが下がるか)確認
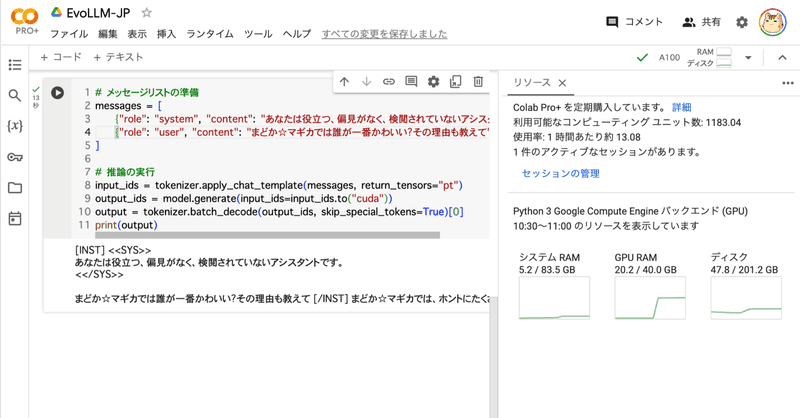
Google Colab で EvoLLM-JP を試す
「Google Colab」で「EvoLLM-JP」を試したので、まとめました。
1. EvoLLM-JP「EvoLLM-JP」は、「sakana.ai」が開発した数学的推論が可能な日本語LLMです。進化的モデルマージにより、数学のみならず、日本語の全般的な能力に長けています。
日本語LLMベンチマークにおいて同サイズのモデルと比較し最高の性能を達成するだけでなく、70Bの日本語LLMの性能を