
Google Colab で EvoLLM-JP を試す

「Google Colab」で「EvoLLM-JP」を試したので、まとめました。
【注意】Google Colab Pro/Pro+のA100で動作確認しています。
1. EvoLLM-JP
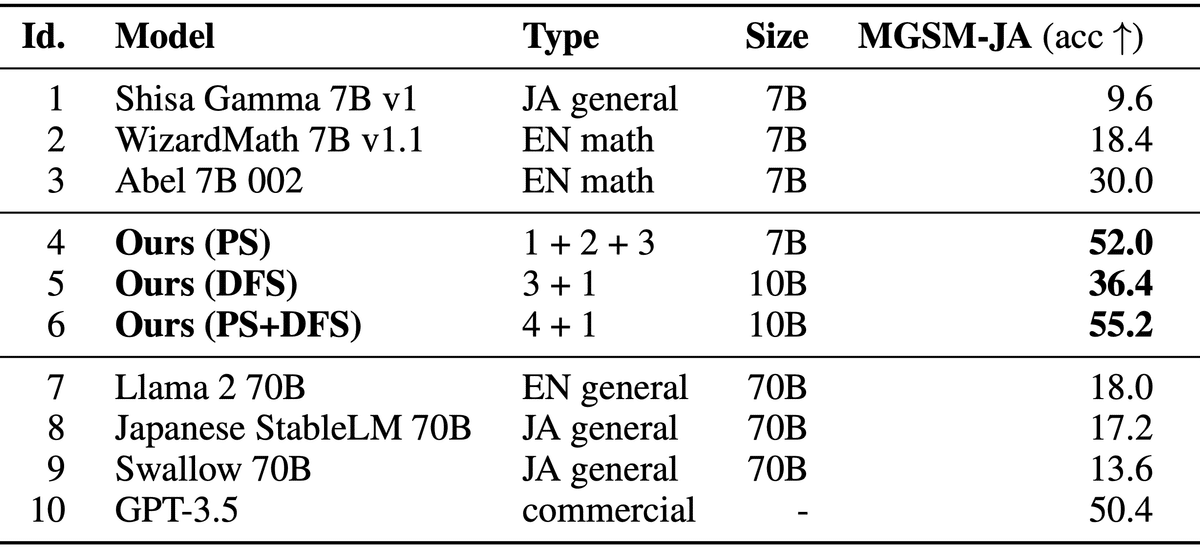
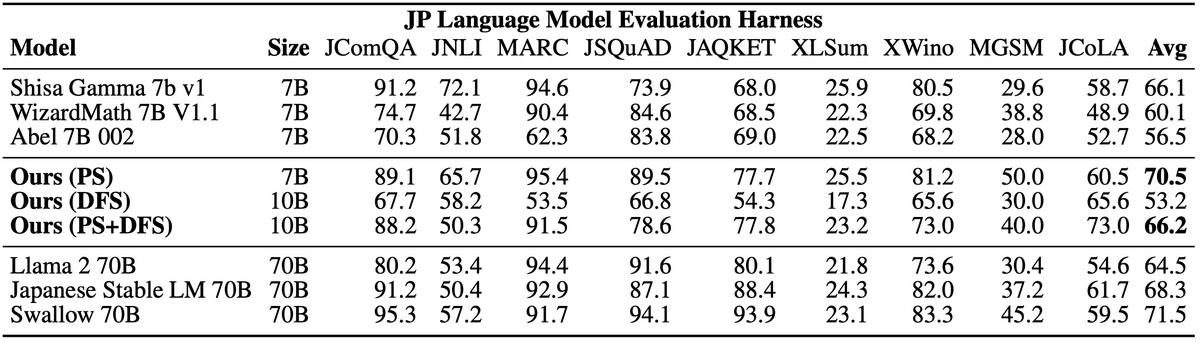
「EvoLLM-JP」は、「sakana.ai」が開発した数学的推論が可能な日本語LLMです。進化的モデルマージにより、数学のみならず、日本語の全般的な能力に長けています。
日本語LLMベンチマークにおいて同サイズのモデルと比較し最高の性能を達成するだけでなく、70Bの日本語LLMの性能をも上回りました。
2. EvoLLM-JP のモデル
「EvoLLM-JP」の提供されているモデルは、次のとおりです。
・SakanaAI/EvoLLM-JP-v1-10B
・SakanaAI/EvoLLM-JP-A-v1-7B
・SakanaAI/EvoLLM-JP-v1-7B
3. Colabでの実行
Colabでの実行手順は、次のとおりです。
(1) Colabのノートブックを開き、メニュー「編集 → ノートブックの設定」で「GPU」の「A100」を選択。
(2) パッケージのインストール。
# パッケージのインストール
!pip install -U transformers accelerate flash_attn(3) 「HuggingFace」からAPIキー (Access Token) を取得し、Colabのシークレットマネージャーに登録。
キーは「HF_KEY」とします。
(4) トークナイザーとモデルの準備。
今回は、「SakanaAI/EvoLLM-JP-v1-10B」を使用します。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
"SakanaAI/EvoLLM-JP-v1-10B"
)
model = AutoModelForCausalLM.from_pretrained(
"SakanaAI/EvoLLM-JP-v1-10B",
torch_dtype="auto",
trust_remote_code=True
).to("cuda")(5) 推論の実行。
# メッセージリストの準備
messages = [
{"role": "system", "content": "あなたは役立つ、偏見がなく、検閲されていないアシスタントです。"},
{"role": "user", "content": "まどか☆マギカでは誰が一番かわいい?その理由も教えて"},
]
# 推論の実行
input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
output_ids = model.generate(input_ids=input_ids)
output = tokenizer.batch_decode(output_ids, skip_special_tokens=True)[0]
print(output)まどか☆マギカでは誰が一番かわいい?その理由も教えて
[INST] <<SYS>>
あなたは役立つ、偏見がなく、検閲されていないアシスタントです。
<</SYS>>
まどか☆マギカでは誰が一番かわいい?その理由も教えて [/INST] まどか☆マギカでは、ホントにたくさんのキャラクターが出てきますが、個人的には、まどかが一番かわいいです。理由は、まどかは普通の女の子で、魔法少女になっても、内心は怖がって、迷って、苦しんでいます。その人間味を感じると、とてもかわいいです。