

#生成AI


OpenAI API の Vision Fine-Tuning を試す
「OpenAI API」の「Vision Fine-Tuning」を試したのでまとめました。
1. Vision Fine-Tuning「GPT-4o」の「Vision Fine-Tuning」が可能になりました。これにより開発者は、より強力な画像理解機能を持つようにモデルをカスタマイズできます。
2. データセットの作成今回は、「ぼっち・ざ・ろっく」の結束バンドのメンバーの名前を学習します。



図面読み取りに革命!生成AIが生産性を加速させる【データ利活用の道具箱 #13】
はじめに最近、生成AI(生成モデルを用いた人工知能)の進化が目覚ましく、皆さんの周りでもよく話題に上がっていると思います。
特に自然言語処理や画像認識、画像生成で高い精度を出しており、多くの業界で実際に活用され始めています。
例えば多様な設備を扱う製造業や建設業では、図面に描かれた設備間の流れや関係性を読み取って追跡するのに苦労することが多いですが、まだ生成AIの導入は進んでいません。
現状図


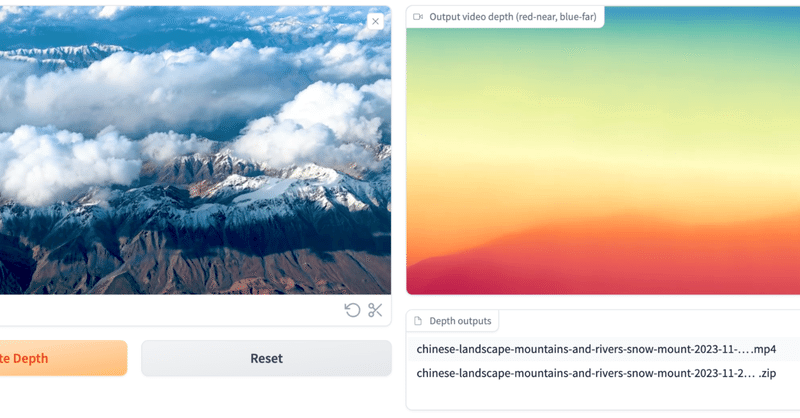
一瞬で綺麗なdepthを取ることができる「Depth Anything V2」を試してみる
Depth Anythingがバージョン2で復活!Depth Anything がバージョン 2 で復活しました。
現在の他の方法よりも 10 倍高速とのこと。すごい!
さまざまなサイズのモデル (2500 万から 13 億のパラメータ) が Huggingface Hub で入手可能になっています。
Depth Anything V2とは?Depth Anything V2はカメラ1台で撮影し
動画での深度推定AIの「ChronoDepth」を試してみる
「ChronoDepth」とはChronoDepthは超簡単に使える動画での深度推定AIツールです。
深度推定モデルをビデオに直接適用すると、フレーム間で不整合が生じる可能性がありますが、実際そういうちょっとした不整合でつかいものにならない残念さはクリエイターならみんな実感するとこと。
これはそういうこともなく簡単にできちゃうとのこと。ありがたや〜〜
なお、モデルはStable Video Dif


segment-anything-2で遊ぶメモ
このメモを読むと
・segment-anything-2を試せる
・動画からオブジェクトを抜き出せる
検証環境
・OS : Ubuntu 22.04(WSL on Windows11)
・Mem : 64GB
・GPU : GeForce RTX™ 4090
・ローカル
・python 3.10.12
・2024/8/B時点
segment-anything-2Meta(旧Facebook

Google Colab で SAM 2 を試す
「Google Colab」で「SAM 2」を試したのでまとめました。
1. SAM 2「SAM 2」(Segment Anything Model 2) は、画像や動画のセグメンテーションを行うためのAIモデルです。目的のオブジェクトを示す情報 (XY座標など) が与えられた場合に、オブジェクトマスクを予測します。
具体的に何ができるかは、以下のデモページが参考になります。
2. セットア

Google Colab で Florence 2 を試す
「Google Colab」で「Florence 2」を試したので、まとめました。
1. Florence 2「Florence 2」は、Microsoftが開発した軽量なVLM (Vision Language Model) です。キャプション、物体検出、OCRなど、さまざまなビジョンタスクを単一モデルで処理することができます。
2. Colabでの実行Colabでのセットアップ手順は、次の

論文解説 Style-NeRF2NeRF: 3D Style Transfer From Style-Aligned Multi-View Images
ひとことまとめ
概要画像生成AIの変換能力をNeRFに応用することで効率的な3Dスタイル変換を実現した。一度NeRFを学習させたあとSDXLでスタイル変換を行い、そのスタイル画像から再度NeRFを再学習させることで、品質の良いスタイル変換を可能にした
提案手法提案手法は、NeRFから複数の角度でレンダリングを行い、それをスタイル画像に変換する工程と、NeRFを生成したスタイル画像でfinetu
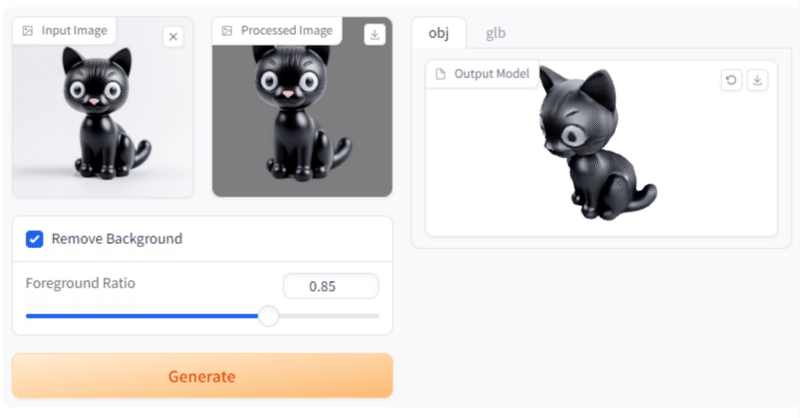
2D-to-3Dの「TripoSR」が話題になったので試してARで召喚してみたよ🐱
Tripo × Stability AI が公開した3D生成AIモデル「TripoSR」。
これが精度よく単一画像からの3Dオブジェクト生成をしてくれると話題になってたので早速試してみようと思います。
詳しくはweelさんの記事がとても分かりやすかったので貼っておきます!
インストール後の画面はこんな感じでした。
それではまずStable Diffusion Web UIで黒猫ちゃんを呼んで


Transformers.jsとDepth Anythingで2D画像を3Dへ 他 / Catch up on AI 2024.3.7
Pick up機械学習モデルをJavaScript環境で動作させることができるTransformers.jsとDepth Anythingを利用して制作された、2D画像を3Dへ変換するフレームワーク。
これがブラウザでできるのは色々と可能性を感じます。
https://x.com/taziku_co/status/1765545934317146165?s=20
オンラインデモ
Painti


第4号「コンピュータビジョンの深層学習ベース化」
Control Color: Multimodal Diffusion-based Interactive Image Colorization
画像に色のヒントを与えて着色するための拡散モデルです。
どんなもの?: 高度に制御可能な対話式画像着色手法であり、無条件および条件付き画像着色を支援し、色溢れや不正確な着色を解決します。
先行研究と比べてどこがすごい?: 複数の条件(テキストプロ


第1号 「画像生成と3D物体生成」
はじめのご挨拶
コンピュータービジョンを中心に毎週、新しい研究をいくつかピックアップし紹介いたいます。arXivを中心に紹介する予定ですが、学会が開催されていればそちらから紹介することもあるかと思います。詳細についてはピックアップする記事は少なくとも5~8本は選びたいので、その量から全て把握するのは難しいため、概要を把握するのに論文一つにかける時間を多くは避けません。私はまだまだ精進する身にある