OpenAI API の Vision Fine-Tuning を試す

「OpenAI API」の「Vision Fine-Tuning」を試したのでまとめました。
1. Vision Fine-Tuning
「GPT-4o」の「Vision Fine-Tuning」が可能になりました。これにより開発者は、より強力な画像理解機能を持つようにモデルをカスタマイズできます。
2. データセットの作成
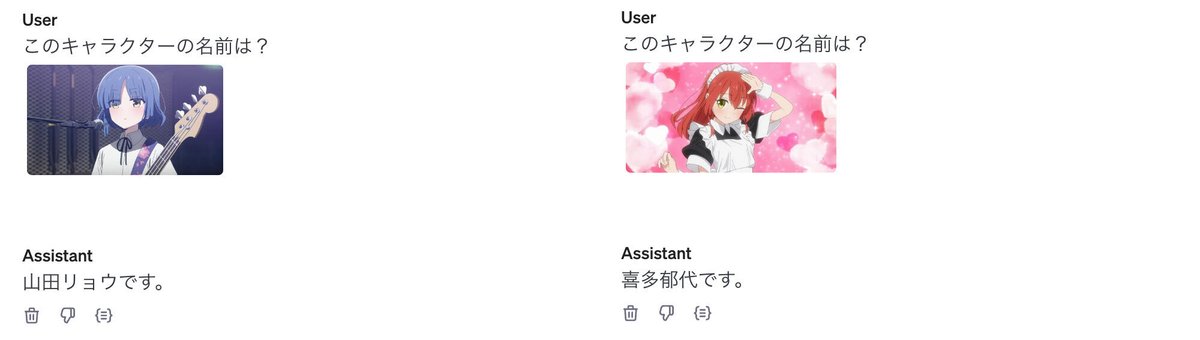
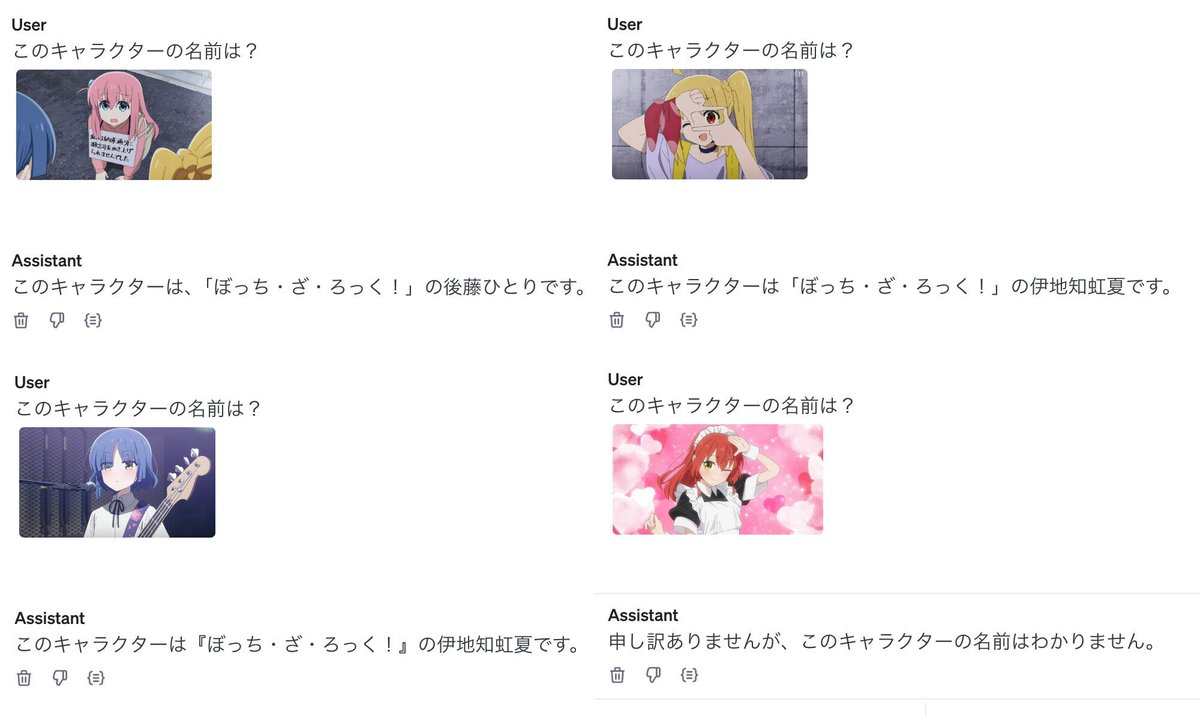
今回は、「ぼっち・ざ・ろっく」の結束バンドのメンバーの名前を学習します。
ファインチューニング前の「GPT-4o」では、「後藤ひとり」「伊地知虹夏」は知っていましたが、「山田リョウ」「喜多郁代」は知りませんでした。
(1) 画像の準備し、Google Colabにアップロード。
今回は4人を4枚ずつ用意し、datasetフォルダを作成してその中に配置しました。

(2) 画像ファイルを読み込む関数の準備。
import base64
# 画像ファイルを読み込む関数
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")(3) 学習データセット「train.jsonl」の作成。
「Chat Completions API」のメッセージを元にしたJSONLになります。
import json
character_names = ["後藤ひとり", "伊地知虹夏", "山田リョウ", "喜多郁代"]
image_names = [
"a0.jpg", "a1.jpg", "a2.jpg", "a3.jpg",
"b0.jpg", "b1.jpg", "b2.jpg", "b3.jpg",
"c0.jpg", "c1.jpg", "c2.jpg", "c3.jpg",
"d0.jpg", "d1.jpg", "d2.jpg", "d3.jpg"]
with open("train.jsonl", "w", encoding="utf-8") as f:
for i in range(16):
url = "data:image/jpeg;base64," + encode_image("dataset/" + image_names[i])
item = {
"messages": [
{ "role": "system", "content": "ぼっち・ざ・ろっくの質問に答えるQAアシスタントです。" },
{
"role": "user",
"content": [
{"type": "text", "text": "このキャラクターの名前は?"},
{
"type": "image_url",
"image_url": {
"url": url,
"detail": "low",
}
},
],
},
{ "role": "assistant", "content": character_names[i//4] + "です。" },
]
}
f.write(json.dumps(item, ensure_ascii=False) + '\n')
print(item)(4) 「train.jsonl」を「Google Colab」からダウンロード。
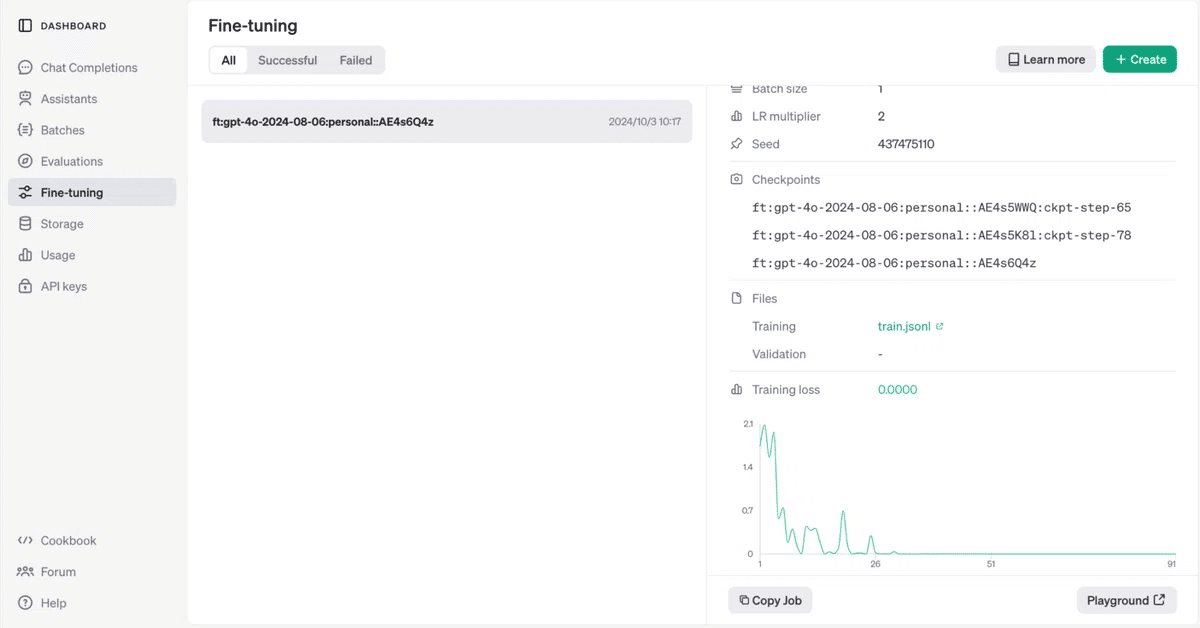
3. ファインチューニング
ファインチューニングの手順は、次のとおりです。
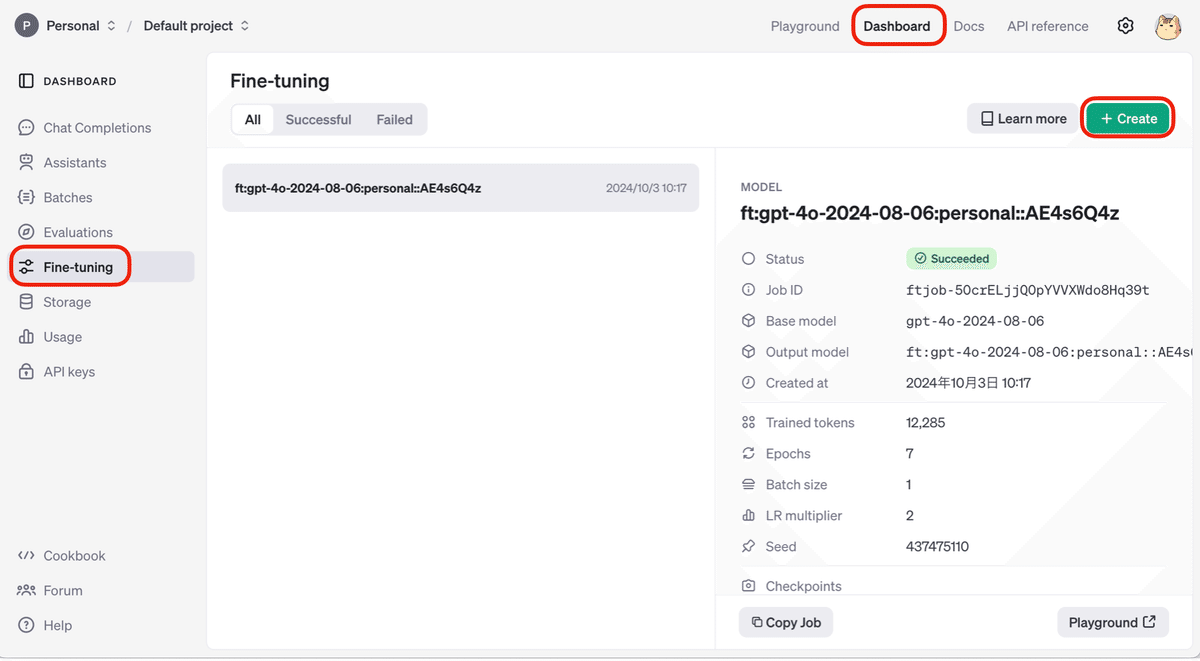
(1) 「OpenAI API」の「Dashboard → Fine-tuning → Create」をクリック。
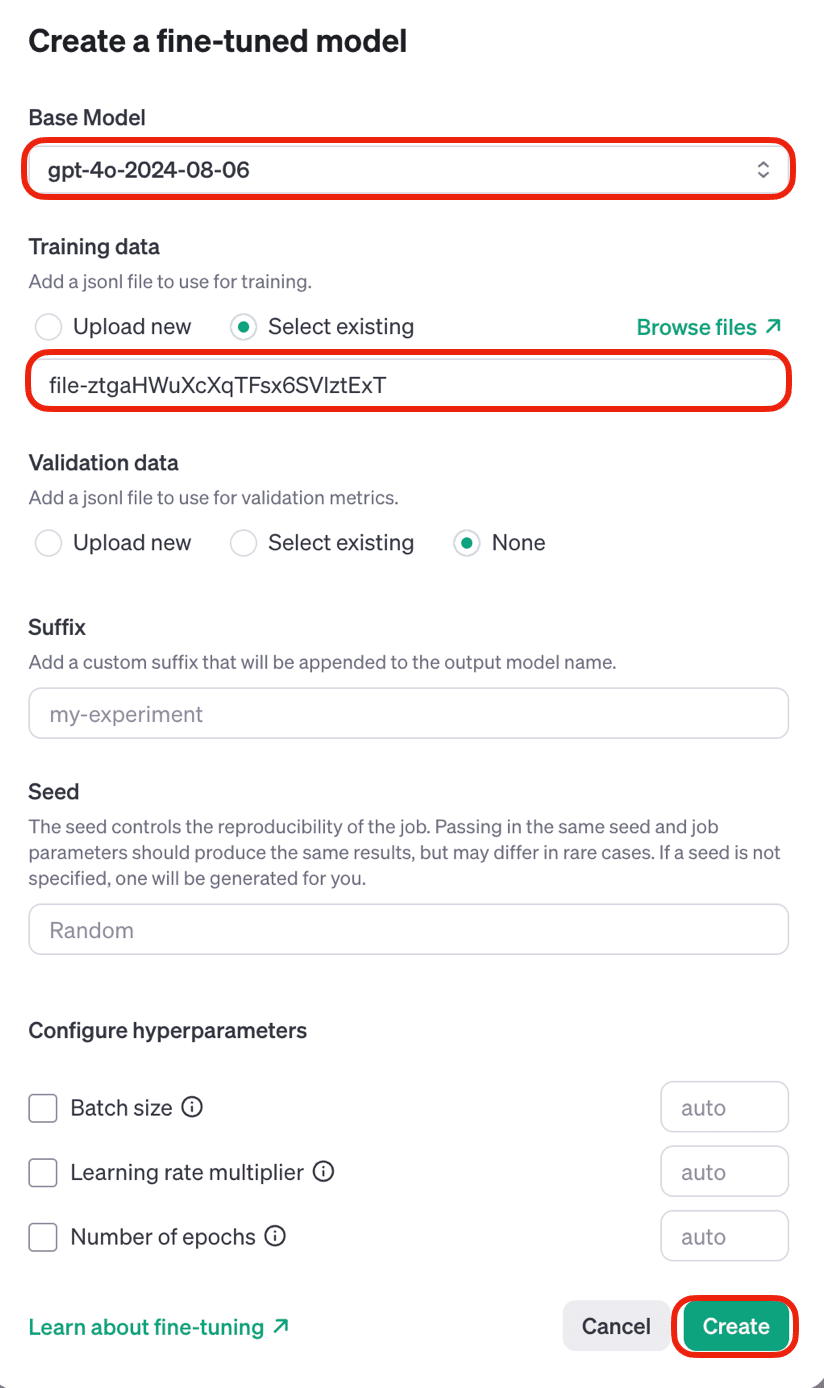
(2) モデル「gpt-4o-2024-08-06」を選択し、「train.jsonl」をドラッグ&ドロップし、「Create」をクリック。
5分程待つと学習完了になります。
4. 推論
(1)「Playground」でファイチューニングしたモデルを選択して会話。