

#StableDiffusion


【今旬の画像生成AIの比較】特徴と使用感の所感【Midjourney,FLUX-1,StableDiffusion,SeaArt,DALL-E3】
画像生成AIはどれを選べばいいかわからない?
この記事では、主要な画像生成AIの特徴と使い心地について、実際に使ってみた経験と偏見も交えながら比較してみようとおもいます。
あらかじめ言っておきます。
月額払うなら私はMidjourney・Niji journey派です。
MidJourney(ミッドジャーニー)
特徴: アート風や幻想的な画像作りが得意です。クリエイティブな仕事をする人におす


立体視出来るステレオ動画をComfyUIで生成する(mp4変換フロー):Xreal Air用
今回は表題通り、生成したAI動画をxreal airで立体視で見ることが出来るステレオ動画に変換する方法になります。
基本は、前回記事で取り上げたDepth anything2とNegitoolsを使用した方法を使います。
試しに、以前生成したAI動画をステレオ動画化してみたいと思います。
プロパティで、FPS、フレーム数を予め確認しておきます。
この動画だと、10FPSで60フレームでした


そうだ!AI画像生成をちゃんと勉強しよう💡17章:背景が透過された画像を作る
(20241013 更新)
※勉強するのはStable Diffusion、SeaArt系になります。
AIで生成したかわいい女の子を素材として使いたいって思ったことある人もいるかと思いますが、背景があるため素材としては使いにくいと思います。
そこで今日はローカル環境のStable Diffusionでも背景透過ができる拡張機能を勉強して、AI画像を素材として使うスキルを身につけていきたいと


【Krita】ImageFXをアップスケール実験【ai-diffusion】
GoogleのImageFXで生成すると1024x1024解像度の画像を生成できます。それをKrita-ai-diffusionを利用して手動アップスケールしてみます。
まずはImageFXで生成します。
手順は
① 「画像拡大」で2x(SD1.5利用)
② 面倒ですが、解像感の悪い顔をそれぞれ再生成(SD1.5利用)
③ 指はFlux.1でインペイント修正
写真のアップスケールはアイ


【SD Pony】 プロンプト比較 体型編
キャラクターの体型を決定するプロンプトの比較です。
体型は胸の大きさにも強く依存し、一緒に考えた方が良いですが、お胸については別に分けて解説します。
前提条件StableDifussionの基礎がわかっている人向け
使用モデルはPony系です。Pony系の特性を理解していること。ここでは独自マージモデルを使用
手書きによる修正無し(一部の画像に人体の破綻が残っていますが修正していません)


SimpleTuner v0.9.8.1でFluxモデル微調整が進化 - StableDiffusion界隈に朗報
はじめにStableDiffusionユーザーの皆さん、お待たせしました!SimpleTunerの最新バージョンv0.9.8.1がついにリリースされ、Fluxモデルの微調整において画期的な進歩を遂げました。本記事では、この重要なアップデートの詳細と、StableDiffusionコミュニティにもたらす影響について深掘りしていきます。
SimpleTuner v0.9.8.1の主な特徴互換性の向上


【StableDiffusion】VRoidからつくる衣装LoRA制作メモ【データセット付き】
■記事の対象ユーザ
1.SDXLのLoRAを作っている(=つよつよグラボを持っている)
2.衣装LoRAを作ってみたが上手く行かない
3.データセットとキャプションをどうしたら良いか判らない
■ようするに?
はじめにちょっと前に「コピー機学習法」による差分LoRA作りの記事で書いたことで
「おで、LoRA、すこしわかる」程度になった気でいたんだけど、調子に乗って同じ感覚で服LoRAにも挑戦した

論文解説 Ada-adapter:Fast Few-shot Style Personlization ofDiffusion Model with Pre-trained Image Encoder
ひとことまとめ
概要StableDiffusionなどのText-to-Imageモデルを特定のスタイルに最適化する研究は複数行われている。例えばDreamBooth、LoRA、Textual Inversionなどがあげられる。しかしながら品質を上げるためには大量の画像が必要である。そこでIP-Adapterなどの事前学習済みモデルを使用し効率的にstyleのみを学習する手法を提案する。提案手


【SDWebUI】Extrasで画像をアップスケールする方法
初心者の方やExtrasを使ったことがない方に向けて、Stable Diffusion Web UI(以下SDWebUI)のExtrasタブを使った画像アップスケール方法をご紹介します。
※A1111・forgeどちらでも操作方法は一緒です。
■プロフィール
自サークル「AI愛create」でAIコンテンツの販売・生成をしています。
クラウドソーシングなどで個人や他サークル様からの生成依頼を多数

Prompt_injection/ComfyUIを試してみた話
今回は、この拡張機能を使って画像生成への効果について試してみました。
本家のものは別でフォーク版です。理由は不明ですが、こちらだとうまく動いたため、こちらを使用しています。
きっかけは、上の記事になります。
この記事では、「prompt_injection」を使用して、画像生成における階層の影響について検討していました。
いまだに十分は理解していませんが、モデルの階層別にプロンプトに対する反応の

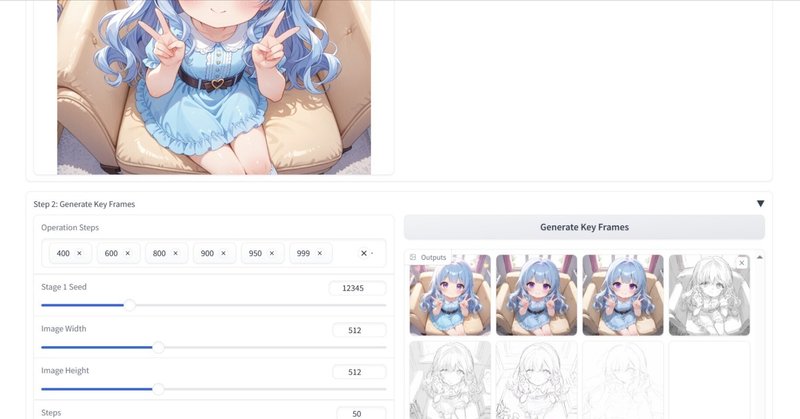
WindowsでPaints-Undoを試す(VRAM 12GB以上)
Last update 7-14-2024
※(7-14) Paints-Undoをベースに、線画とスケッチの生成に特化したSketch-Genの記事を書きました。
※利用前に、リポジトリの最後に書いてある免責事項を必ず確認してください。
▼ 0. 本記事について0-1. 概要
本記事では、Paints-UNDOをインストールして実行する手順を紹介します。こちらの作者は、ControlNet


【画像生成AI】 自然な文章で思い通りの画像生成を実現する最先端モデル『Kolors』を試してみた
Stable Diffusionでの画像生成の欠点は、生成したい画像の情景をカンマ区切りのタグで入力するので、思った通りの画像を生成できないことでした。
この問題の解決に繋がる研究成果がKuaishou Technologyよりもたらされました。Kuaishouは、GML (General Language Model)を用いて、英語と中国語の理解力が強化されたモデル『Kolors』を発表しました


自作背景LoRAを作ってみた話
こんにちは、Cyphiaです。今回は自分の絵で背景LoRAを作ってみたのでそれを紹介します。
作成方法 学習にはCivitai.comのをLoRA作成サービスを利用しました。自分のPCの計算能力が不足しているのが主な理由です。
このサービスの使い方は、まず作りたいLoRAのモデルタイプをCharactter, Style, Concept の中から選びます。今回はStyleを選択しました。次

ComfyUIでモデルとLoraのマージをしてみた。直感的で取っ付きやすい!
モデルのマージについては初心者なのですが、ComfyUIで簡単に出来たので記事にしました。
モデルのマージについては、多くの方が記事を書かれていますのでそちらを参照して下さい。
今回は初心者の自分の備忘録的にやった内容を記載する感じになります。
この記事はLoraのマージになります。
やってみた印象としては、モデルのマージよりははるかに簡単なものだと感じましたので、ここからマージ系に入るのが良