

#Llama2




MetaのLlama3を眺めてみる
Hugging FaceにおけるLlama3の紹介2024年4月18日に、MetaよりFacebookの会社より、Llama3がリリースされました。オープン系の大規模言語モデルでは、Meta社のLlama2をベースにファインチューニングされているLLMが性能評価でも結果を残しているので、Llama2の後継のLlama3は期待度が高いです。
Hugging FaceにおけるLlama3の情報を眺

Chat VectorとMath Vectorは併用できるのか
はじめにこの記事は以下記事の続きになります。
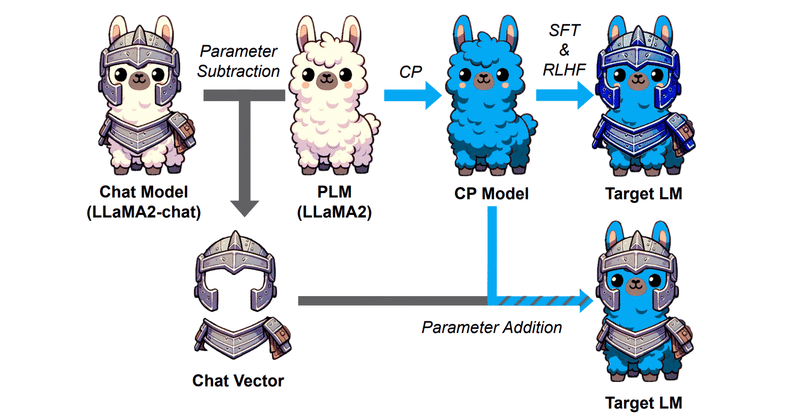
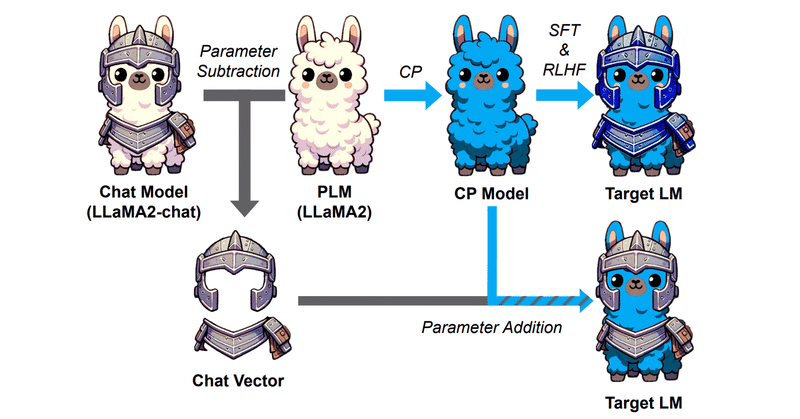
Chat Vectorと呼ばれる、重みの足し引きでFine TuningなしにChat能力を事前学習モデルに付与できるという技術あります。
この発想から、Chat能力以外にも能力の切り貼りはできるのかという検証が前記事までの趣旨となります。
結果以下の通りです。
⭕️ Chat(論文)
× Code
⭕️ Math Reasoning
なので
Chat VectorにならぬCode Vectorは作れるのか
はじめにChat Vectorと呼ばれる、重みの足し引きでFine TuningなしにChat能力を事前学習モデルに付与できるという技術あります。
つまりこういうことですね。
ChatVector = Llama2-chat - Llama2
でChat能力を抽出し、
New-Model-chat = New-Model + ChatVector
でNew-ModelにChat能力を付与でき


LoRAよりいいらしいLISA
LISAという手法がLoRAより高性能らしく、場合によってはフルパラメータチューニングに匹敵するという
https://arxiv.org/pdf/2403.17919.pdf 以下、図版は全てこの論文から
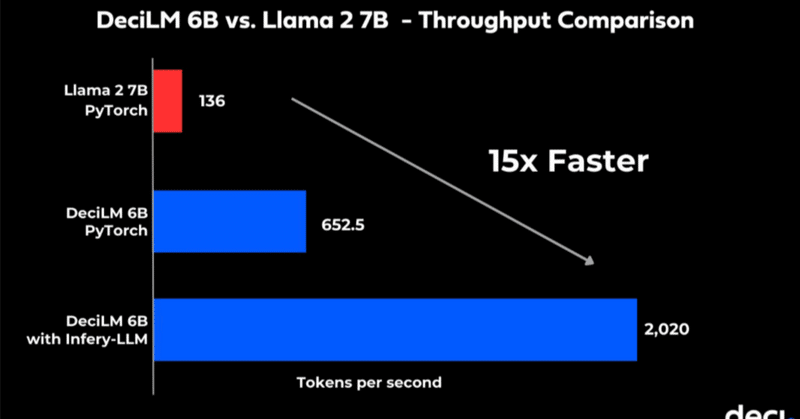
Llama2-70Bにおける比較
確かに、Llama2-70B-FT(フルパラメータチューニング)よりもLISAの方が成績が良くなっている。
その上、メモリー消費量はLoRAより低い


700億パラメータの日本語LLM「ELYZA-japanese-Llama-2-70b」を開発し、デモを公開しました
はじめにこの度 ELYZA は、新たに開発した700億パラメータの大規模言語モデル (LLM) である「ELYZA-japanese-Llama-2-70b」のデモを公開しました。「ELYZA-japanese-Llama-2-70b」は、前回までに引き続き、英語の言語能力に優れた Meta 社の「Llama 2」シリーズに日本語能力を拡張するプロジェクトの一環で得られた成果物です。
ELYZ



メモリをスワッピングしながら大規模言語モデル(LLama2)をフルパラメータでファインチューニングできるかどうか?
背景大規模言語モデルの学習には、大量のメモリ容量が必要になります。
例えば700億パラメータ(70b)のモデルを16bit変数で読み込むだけでも70 GB程度の容量が必要で、学習にはその10倍程度の容量くらいはあると安心です。
ただし、学習に必要なGPUは高額(A100の80GBモデルは200万円超)なので、多額の資金が必要になります。
打開策として、有名なQLoRAのほか、学習に必要なメモリ
LLama2の訓練可能な全層をQLoRAで学習する
はじめにLLama2はMetaが23年7月に公開した、GPT-3に匹敵するレベルのオープンソース大規模言語モデル(LLM)です。
最近はFalcon 180bのような、より大きなモデルも出ていますが、デファクトスタンダードとして定着している感があります
LLMに新たな情報を加える手法として、ファインチューニング、特にQLoRAが注目されています。
しかしQLoRA、特に初期設定では一部のパラ

ELYZA-japanese-Llama-2-7b で LlamaIndex を 試す
「ELYZA-japanese-Llama-2-7b」で「LlamaIndex」を試したのでまとめました。
1. 使用モデル今回は、「ELYZA-japanese-Llama-2-7b-instruct」と埋め込みモデル「multilingual-e5-large」を使います。
2. ドキュメントの準備今回は、マンガペディアの「ぼっち・ざ・ろっく!」のあらすじのドキュメントを用意しました。

Google Colab で ELYZA-japanese-Llama-2-7b を試す
「Google Colab」で「ELYZA-japanese-Llama-2-7b」を試したので、まとめました。
1. ELYZA-japanese-Llama-2-7b「ELYZA-japanese-Llama-2-7b」は、東京大学松尾研究室発・AIスタートアップの「ELYZA」が開発した、日本語LLMです。Metaの「Llama 2」に対して日本語による追加事前学習を行なっています。
2

Metaの「Llama 2」をベースとした商用利用可能な日本語LLM「ELYZA-japanese-Llama-2-7b」を公開しました
本記事のサマリーELYZAが「Llama 2」ベースの商用利用可能な日本語LLM「ELYZA-japanese-Llama-2-7b」を一般公開
性能は「GPT-3.5 (text-davinci-003)」に匹敵、日本語の公開モデルのなかでは最高水準
Chat形式のデモや評価用データセットも合わせて公開
既に社内では、130億、700億パラメータのモデルの開発も進行中
はじめにこんにちは

