
Metaの「Llama 2」をベースとした商用利用可能な日本語LLM「ELYZA-japanese-Llama-2-7b」を公開しました

本記事のサマリー
ELYZAが「Llama 2」ベースの商用利用可能な日本語LLM「ELYZA-japanese-Llama-2-7b」を一般公開
性能は「GPT-3.5 (text-davinci-003)」に匹敵、日本語の公開モデルのなかでは最高水準
Chat形式のデモや評価用データセットも合わせて公開
既に社内では、130億、700億パラメータのモデルの開発も進行中
はじめに
こんにちは。ELYZAの研究開発チームの佐々木、中村、平川、堀江です。
この度ELYZAは、Metaの「Llama 2」をベースに、日本語による追加事前学習を行なった日本語言語モデル「ELYZA-japanese-Llama-2-7b」と、そこにELYZA独自の事後学習を施した「ELYZA-japanese-Llama-2-7b-instruct」、日本語の語彙追加により高速化を行った「ELYZA-japanese-Llama-2-7b-fast / ELYZA-japanese-Llama-2-7b-fast-instruct」を一般公開しました。いずれも70億パラメータのモデルで、公開されている日本語のLLMとしては最大級の規模です。
ライセンスはLlama 2 Community License に準拠しており、Acceptable Use Policy に従う限りにおいては、研究および商業目的での利用が可能です。
以下のリンクからデモを利用いただけます。ぜひ触ってみてください。
● ELYZA-japanese-Llama-2-7b-instruct デモ
● ELYZA-japanese-Llama-2-7b-fast-instruct デモ
※デモの公開は 2024年4月4日(木) を持って終了させていただきました。モデル自体は引き続きHuggingface Hubにて公開しております。
Llama 2とは
Llama 2とは、2023年7月18日にMeta社が公開した英語ベースの大規模言語モデルです。先に公開された「LLaMA」が研究用途に限定されていたのに対し、Llama 2は商用利用も可能となっています。公開されているモデルとしてはとても性能が高いことから、OpenAIのGPT-4やGoogleのPaLMなどのクローズドなLLMと競合する形で、英語圏では既にオープンモデルのデファクトスタンダードとなりつつあります。
サイズは70億、130億、700億の3種類となっており、いずれのモデルも教師ありファインチューニング(Supervised Fine-Tuning、SFT)及び、人間からのフィードバックに基づいた強化学習(Reinforcement Learning from Human Feedback、RLHF)を施したchatモデルも同時に公開しています。
今回のモデル公開に込める願い
現在日本では、複数の企業が独自に日本語LLMの開発に取り組んでいますが、2兆トークンものテキストで学習されたMetaのLlama 2などと比較すると、まだまだ小規模なものに留まっているのが現状です。その背景には、計算リソースの不足や、日本語で利用できるテキストデータの少なさなどがあります。また、一からLLMの事前学習を行うには膨大なコストがかかるため、研究を行うことができるのは一部の大企業や研究機関のみとなっています。
そのようななかELYZAでは、英語を始めとした他の言語で学習されたLLMの能力を日本語に引き継ぎ、日本語で必要な学習量を減らすことで、日本語LLMの研究開発を加速させることができるのではないかと考え、多言語LLMの日本語化に注目してきました。
今回はそのプロジェクトの成果の一つとして、MetaのLlama 2をベースに日本語の能力を向上させたモデルの開発に成功したため、その一部を公開することとしました。また、近日中に公開予定の技術ブログでは、Llama 2を日本語化するなかで得られた知見やノウハウについての詳細を共有する予定です。
既に130億、700億パラメータのモデルの開発にも着手しており、それらのモデルについても公開を検討しています。ELYZAでは、モデルやノウハウの公開を通して、研究室やスタートアップ、個人などでも日本語LLMの研究開発に取り組める土壌を整えることで、日本語LLMの研究を加速させることを目指しています。
公開したモデル
ELYZA-japanese-Llama-2-7b
MetaのLlama-2-7b-chatに対して、約180億トークンの日本語テキストで追加事前学習を行ったモデルです。学習に用いたのは、OSCARやWikipedia等に含まれる日本語テキストデータです。
ELYZA-japanese-Llama-2-7b-instruct
ユーザーからの指示に従い様々なタスクを解くことを目的として、ELYZA-japanese-Llama-2-7bに対して事後学習を行ったモデルです。事後学習には、ELYZA独自の高品質な指示データセットを用いており、複数ターンの対話にも対応することが可能です。なお、ELYZAでの事後学習においては、GPT-4やGPT-3.5-turboなどの出力は一切含まれていません。
ELYZA-japanese-Llama-2-7b-fast / ELYZA-japanese-Llama-2-7b-fast-instruct
Llama 2に日本語の語彙を追加して事前学習を行ったモデルです。元のLlama 2は日本語の語彙が少ないため、日本語の文章を表すのに要するトークン数が英語と比べて多く、入出力できる文章量が短くなってしまうとともに、推論速度が遅いという問題を抱えていました。
そこで今回新たに13,042個の日本語の語彙を追加し、結果として同じ日本語の文章を表すのに必要なトークン数を、約55%まで削減することができました。推論速度に換算すると約1.82倍となっており、大幅な効率化に成功しています。また、ELYZA-japanese-Llama-2-7b-fastに対して事後学習を行った「ELYZA-japanese-Llama-2-7b-fast-instruct」も同時に公開しています。
性能評価
ELYZA Tasks 100
ELYZAでは、社内で開発している日本語LLMの性能評価を行うために、多様な日本語タスクからなるデータセットを独自に作成して利用しています。なぜそのようなことをしているかと言うと、既存の評価用データセットでは、タスクの多様性や複雑さが不足しており、ChatGPTのような汎用的な言語能力を十分に測ることができないと考えているからです。また、自動評価指標では生成AIの性能を正確に評価することができないため、最終的には人間による評価を行う必要があります。そのためELYZAでは、人間による評価を行うことが可能な件数(100件)に絞り、代わりに多様で複雑なタスクを含むデータセットを人手で作成しました。
今回このデータセットを「ELYZA Tasks 100」と名付け、モデルと同時に一般公開することとなりました。詳細な評価基準や、各モデルで推論した際のコードも公開しているため、ぜひご活用ください。
「ELYZA Tasks 100」はこちらのリポジトリから利用いただけます。
実際にELYZA Tasks 100を用いて、5段階の人手評価を行った結果を以下に示します。なお評価の際は、モデル名を隠してシャッフルした状態でのブラインドテストを3人で行い、スコアを平均して算出しています。
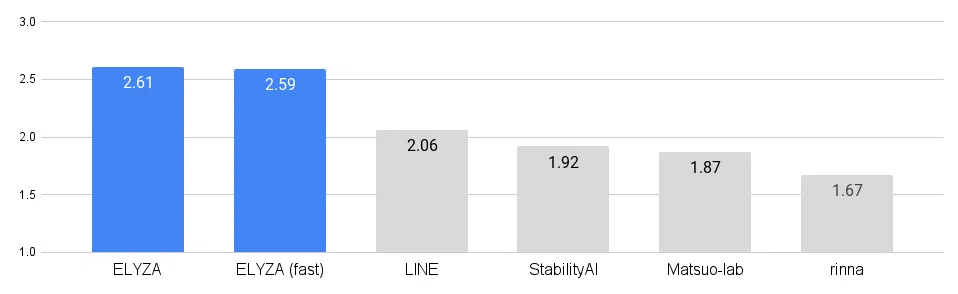
人手評価の結果、ELYZA-japanese-Llama-2-7b-instructは、他の公開されている日本語モデルと比較して最も高いスコアを獲得しました。また、ELYZA-japanese-Llama-2-7b-fast-instructも同程度のスコアを獲得しており、速度を重視したい用途においては十分に選択肢に入るモデルとなっています。
以下に、ELYZA-japanese-Llama-2-7b-instructの実際の出力の例をいくつかお見せします。
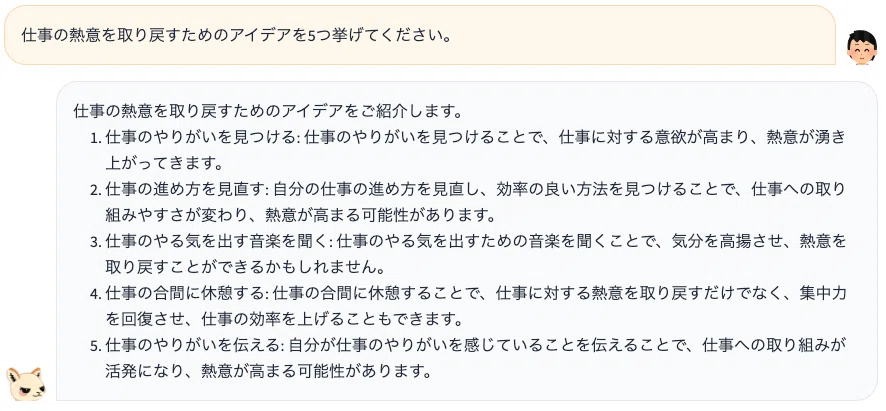
1つ目の例は、ブレインストーミングのタスクで、指示の通り5つの異なるアイデアをユーザーに提供することができています。また出力のフォーマットに関しても、連番 + 見出し + 説明文の形式になっており、ユーザーが読みやすいように工夫されています。

2つ目の例は、2つの文章が言い換え可能かを判定するタスクで、指示の仕方も実際のユーザーに近いものとなっています。これに対してELYZAモデルは、1の文と2の文の意味を正確に解釈した上で、それらが異なっていることを正しく判定できています。
また参考までに、OpenAIのGPT-4やGPT-3.5-turbo、GoogleのPaLMなどのクローズドなLLMのスコアも併せたものを以下に示します。
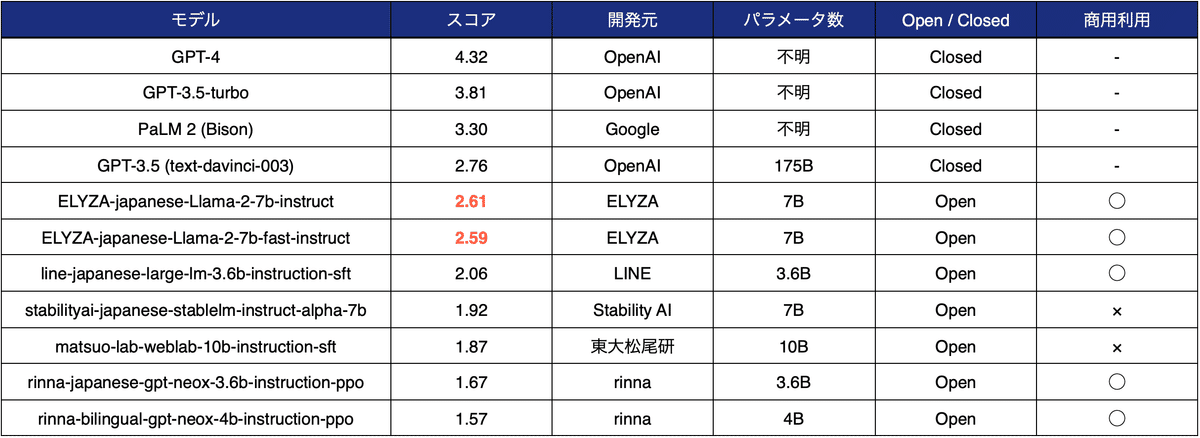
ELYZA-japanese-Llama-2-7b-instructは、まだクローズドなLLMには及ばないものの、オープンな日本語モデルとしては最も高いスコアを獲得しています。ELYZAでは今後もさらなる性能向上を目指し、研究開発を進めてまいります。
なお、ELYZAのモデルの学習には、ELYZA Tasks 100のデータセットを一切用いていないものの、モデル選定にはELYZA Tasks 100のスコアを一部参考にしているため、ELYZAモデルにとってやや有利に働いている可能性があります。
各モデルの具体的な出力と評価結果については、こちらのスプレッドシートで公開しています。
lm-evaluation-harness
また、日本語モデルの性能評価によく用いられるlm-evaluation-harnessによる評価結果も以下に示します。
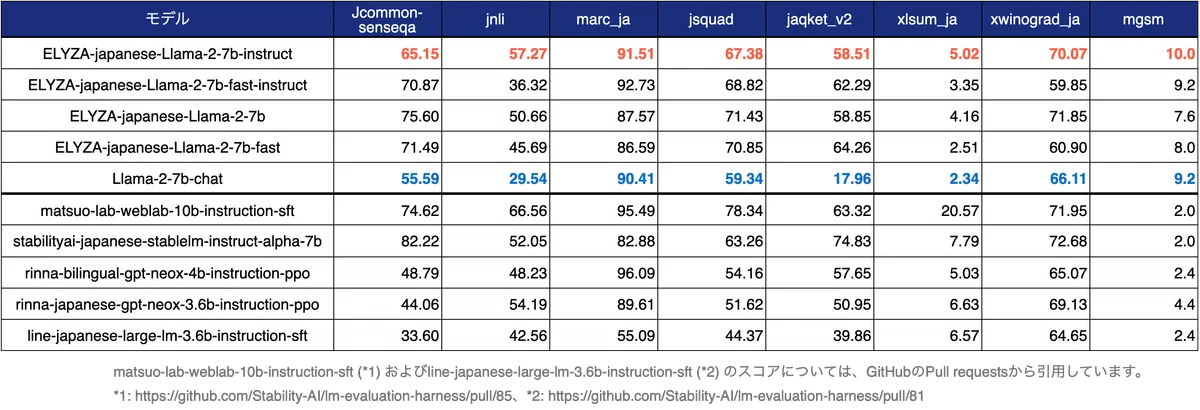
ELYZA-japanese-Llama-2-7b-instructは、全ての項目において元のLlama-2-7b-chatを上回るスコアとなっています。このことから、日本語の追加事前学習と事後学習によって、確かに日本語の能力を獲得していることが確認できます。また、今回ELYZAで追加事前学習を行ったモデルは、他の日本語モデルと比較すると学習している日本語のトークン数が少ないにも関わらず、それらと遜色ないスコアを獲得していることがわかります。
一方で、このような一般データセットでは、日本語の知識や簡単な読解能力を測ることはできるものの、ユーザーからの指示に従う能力を測るには不向きであることが社内の検証でわかっています。実際に、事後学習を行ったELYZA-japanese-Llama-2-7b-instructと、行っていないELYZA-japanese-Llama-2-7bでは、指示に従う能力に大きな差があるにも関わらず、lm-evaluation-harnessの評価結果では同程度のスコアとなっています。
使用方法
今回公開した4つのモデルは、いずれもHugging Face Hubにて公開しており、transformersライブラリから利用可能です。詳しい使用方法は、以下のリンク先のREADMEをご覧ください。
https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7b
https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7b-instruct
https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7b-fast
https://huggingface.co/elyza/ELYZA-japanese-Llama-2-7b-fast-instruct
今後の展望
今回公開した「ELYZA-japanese-Llama-2-7b」シリーズは、Llama 2の最も小さいサイズである70億パラメータのモデルをベースに開発したものです。Llama 2には130億、700億パラメータのモデルも存在しており、ELYZAではそれらのモデルの日本語化にも既に着手しています。近いうちによりパワーアップしたモデルをお届けできるよう、開発を進めてまいります。さらにLlama 2での取り組みに限らず、海外のオープンなモデルの日本語化や、自社独自の大規模言語モデルの開発に継続して投資をしてまいります。
今後もELYZAは、国内の言語生成AI開発をリードすべく、国内の言語生成AIのリーディングカンパニーとして、日本全体のLLM活用やLLMの技術力向上を加速する目的で、得られた成果について商用利用可能なかたちでの公開、または企業案件を通じて社会に還元してまいります。
今回の取り組みの内容は、8月30、31日開催の「NLP若手の会(YANS)第18回シンポジウム(2023)」でも発表されました。
関連記事
弊社エンジニアによる「ELYZA-japanese-Llama-2-7b」に関する技術解説ブログを順次公開しています。ぜひこちらも併せてご覧ください。
●2023年9月12日公開 (1) 事前学習編
●2023年9月26日公開(2)評価編
●2024年1月16日公開(3)英語での性能評価編
最後に
株式会社ELYZAは、「未踏の領域で、あたりまえを創る」という理念のもと、日本語の大規模言語モデルに焦点を当て、企業との共同研究やクラウドサービスの開発を行なっております。先端技術の研究開発とコンサルティングによって、企業成長に貢献する形で言語生成AIの導入実装を推進します。

ここまでお読みいただき、ありがとうございました。
ELYZAではAIエンジニア、AIコンサルタントなど、様々な職種で一緒に事業を前に進めてくれる仲間を募集しています。少しでも興味を持っていただけた方は、ぜひカジュアル面談にお越しください。
日本語Llama2をはじめとするLLM開発について話しませんか?
https://chillout.elyza.ai/
この記事が気に入ったらサポートをしてみませんか?