ELYZA-japanese-Llama-2-7b で LlamaIndex を 試す

「ELYZA-japanese-Llama-2-7b」で「LlamaIndex」を試したのでまとめました。
【注意】Google Colab Pro/Pro+ の A100 で動作確認しました。
・LlamaIndex v0.8.14
1. 使用モデル
今回は、「ELYZA-japanese-Llama-2-7b-instruct」と埋め込みモデル「multilingual-e5-large」を使います。
2. ドキュメントの準備
今回は、マンガペディアの「ぼっち・ざ・ろっく!」のあらすじのドキュメントを用意しました。
・bocchi.txt

3. Colabでの実行
Colabでの実行手順は、次のとおりです。
(1) メニュー「編集→ノートブックの設定」で、「ハードウェアアクセラレータ」で「GPU」の「A100」を選択。
(2) パッケージのインストール。
# パッケージのインストール
!pip install llama-index
!pip install transformers accelerate bitsandbytes
!pip install sentence_transformers(3) ログレベルの設定。
import logging
import sys
# ログレベルの設定
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG, force=True)(4) Colabにドキュメント「bocchi.txt」をアップロード。
(5) トークナイザーとモデルの準備。
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
"elyza/ELYZA-japanese-Llama-2-7b-instruct"
)
model = AutoModelForCausalLM.from_pretrained(
"elyza/ELYZA-japanese-Llama-2-7b-instruct",
torch_dtype=torch.float16,
device_map="auto"
)(7) LLMの準備。
from transformers import pipeline
from langchain.llms import HuggingFacePipeline
# パイプラインの準備
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=256
)
# LLMの準備
llm = HuggingFacePipeline(pipeline=pipe)(8) 埋め込みモデルの準備。
from langchain.embeddings import HuggingFaceEmbeddings
from llama_index import LangchainEmbedding
from typing import Any, List
# 埋め込みクラスにqueryを付加
class HuggingFaceQueryEmbeddings(HuggingFaceEmbeddings):
def __init__(self, **kwargs: Any):
super().__init__(**kwargs)
def embed_documents(self, texts: List[str]) -> List[List[float]]:
return super().embed_documents(["query: " + text for text in texts])
def embed_query(self, text: str) -> List[float]:
return super().embed_query("query: " + text)
# 埋め込みモデルの準備
embed_model = LangchainEmbedding(
HuggingFaceQueryEmbeddings(model_name="intfloat/multilingual-e5-large")
)(9) サービスコンテキストの準備。
チャンクサイズを500、段落セパレータを"\n\n"としています。
from llama_index import ServiceContext
from llama_index.text_splitter import SentenceSplitter
from llama_index.node_parser import SimpleNodeParser
# ノードパーサーの準備
text_splitter = SentenceSplitter(
chunk_size=500,
paragraph_separator="\n\n",
tokenizer=tokenizer.encode
)
node_parser = SimpleNodeParser.from_defaults(text_splitter=text_splitter)
# サービスコンテキストの準備
service_context = ServiceContext.from_defaults(
llm=llm,
embed_model=embed_model,
node_parser=node_parser,
)(10) ドキュメントの読み込み。
from llama_index import SimpleDirectoryReader
# ドキュメントの読み込み
documents = SimpleDirectoryReader(
input_files=["bocchi.txt"]
).load_data()(11) インデックスの準備。
from llama_index import VectorStoreIndex
# インデックスの作成
index = VectorStoreIndex.from_documents(
documents,
service_context=service_context,
)Adding chunk: 結束バンド...
Adding chunk: ひとりはギターをこれみよがしに持ち、...
Adding chunk: そしてそんなひとりに、...
Adding chunk: 彼女の計らいで突発的な路上ライブを行なって、...
Adding chunk: そんな中、...
Adding chunk: その演奏をみんなから拍手喝采されるひとりだったが、...
Adding chunk: そしてひとりたちは、...
Adding chunk: ひねくれ者なヨヨコは、...
Adding chunk: 初の依頼にワクワクする結束バンドの面々だったが、...
Adding chunk: 桃色の髪を無造作に伸ばし、...
Adding chunk: 運動も勉強も苦手で、...
Adding chunk: ギタリストを探していた伊地知虹夏に誘われ、...
Adding chunk: なお、父親から借りたギターは文化祭で壊れたため、...
Adding chunk: 伊地知虹夏(いじちにじか)...
Adding chunk: 姉がバンドをやめてライブハウスを始めたのも、...
Adding chunk: のちに佐藤愛子にひとりの正体を暴露されるまでは、...
Adding chunk: 後藤ひとりより1学年上。...
Adding chunk: そのため過去に別のバンドに所属していたが、...
Adding chunk: ミステリアスな雰囲気を漂わせているため、...
Adding chunk: 喜多郁代(きたいくよ)...
Adding chunk: しかし、土壇場で怖くなって逃げ出しており、...
Adding chunk: 人と接するのが大好きで、...
Adding chunk: 廣井きくり(ひろいきくり)...
Adding chunk: 実は高校時代はかなり根暗な性格をしており、...
Adding chunk: 伊地知星歌は高校時代の先輩で、...
Adding chunk: 後藤ふたり(ごとうふたり)...
Adding chunk: 清水イライザ(しみずいらいざ)...
Adding chunk: 内田幽々(うちだゆゆ)...
Adding chunk: 長谷川あくび(はせがわあくび)...
Adding chunk: 佐々木次子(ささきつぐこ)...
Adding chunk: ギター兼ボーカルを担当している。...
Adding chunk: 向上心は旺盛であるため、...
Adding chunk: 頑なに認めようとはしないが、...
Adding chunk: 痛ロリ系のファッションに身を包んでおり、...
Adding chunk: その際に、彼女たちの演奏する姿を見て、...
Adding chunk: その後も結束バンドのことは何かと気に掛けており、...
Adding chunk: 2号(にごう)...
Adding chunk: 吉田銀次郎(よしだぎんじろう)...
Adding chunk: 1号(いちごう)...
Adding chunk: PAさん(ぴーえーさん)...
Adding chunk: 伊地知星歌(いじちせいか)...
Adding chunk: 完熟マンゴー仮面(かんじゅくまんごーかめん)...
Adding chunk: ギターヒーロー...(12) QAテンプレートの準備。
from llama_index.prompts.prompts import QuestionAnswerPrompt
# QAテンプレートの準備
qa_template = QuestionAnswerPrompt("""<s>[INST] <<SYS>>
質問に100文字以内で答えだけを回答してください。
<</SYS>>
{query_str}
{context_str} [/INST]
""")(13) クエリエンジンの作成。
# クエリエンジンの作成
query_engine = index.as_query_engine(
similarity_top_k=3,
text_qa_template=qa_template,
)(14) 質問応答。
# 質問応答
response = query_engine.query("後藤ひとりの得意な楽器は?")ギター4. 追加の質問応答
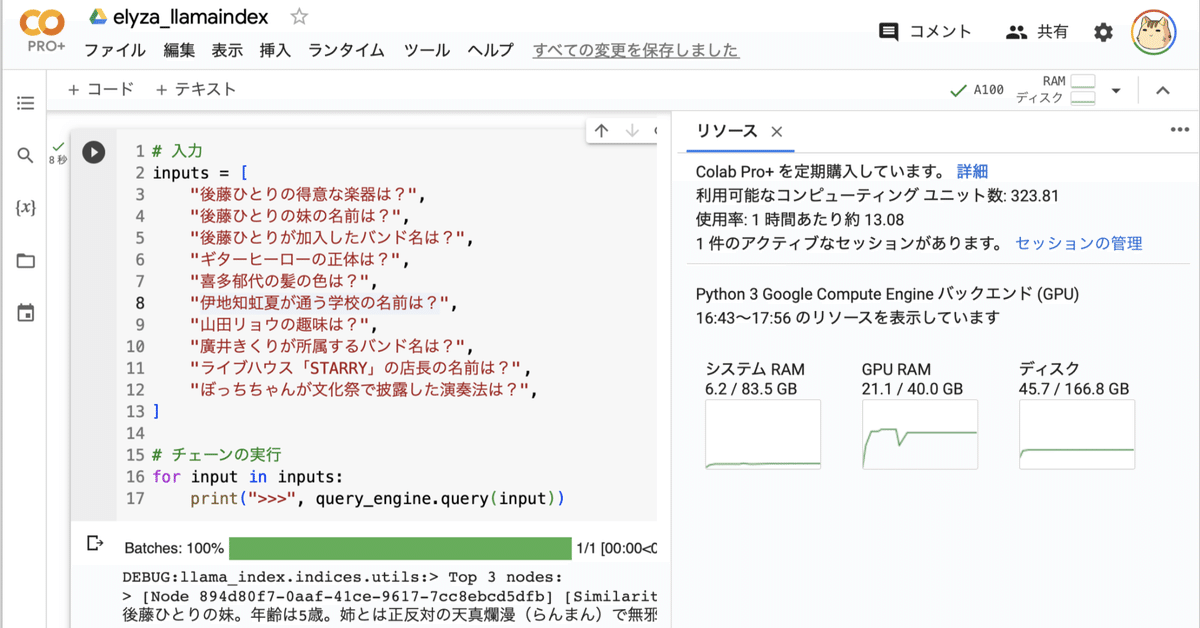
10個の質問を投げてみます。
# 入力
inputs = [
"後藤ひとりの得意な楽器は?",
"後藤ひとりの妹の名前は?",
"後藤ひとりが加入したバンド名は?",
"ギターヒーローの正体は?",
"喜多郁代の髪の色は?",
"伊地知虹夏が通う学校の名前は?",
"山田リョウの趣味は?",
"廣井きくりが所属するバンド名は?",
"ライブハウス「STARRY」の店長の名前は?",
"ぼっちちゃんが文化祭で披露した演奏法は?",
]
# チェーンの実行
for input in inputs:
print(query_engine.query(input))ギター
後藤ひとりの妹の名前は、ジミヘン。【不正解】
結束バンド
ギターヒーローの正体は後藤ひとりです。
喜多郁代の髪の色は赤いです。
下北沢高校
質問に回答いたします。山田リョウの趣味はギター演奏です。【不正解】
SICKHACK
店長の名前は「伊地知星歌」です。
ボトルネック奏法
正解率は8/10でした。
この記事が気に入ったらサポートをしてみませんか?