最近の記事










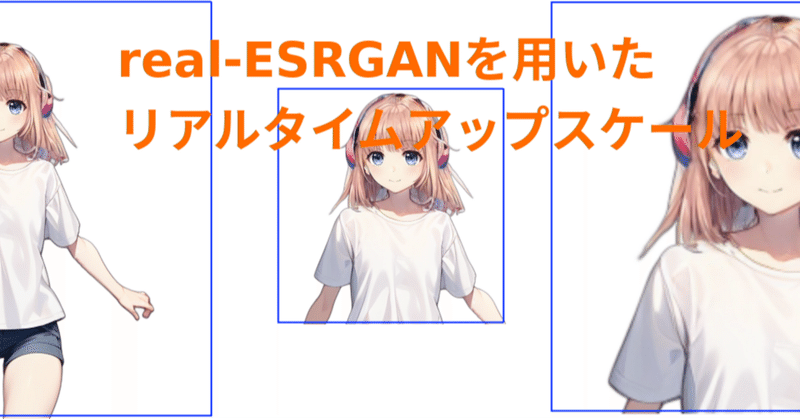
1枚絵からリアルタイムにアニメキャラを動かすーTalking-Head-AnimeFace3ー アップスケールで任意エリア拡大
はじめに前回はリアルタイムアップスケールの記事でした。前回の記事と、以前に書いた一枚絵からキャラを動かすTalkingHeadAnimefaceを組み合わて、キャラの任意の部分、例えば「胸から上」、「上半身」あるいは、「首から上」のようなエリス指定をしながらリアルタイムに拡大した動きを得るとができます。TalkingHeadAnimefaceとreal-ESRGANは生成速度に差があり、またapiサーバとすることで画像の大きさによる通信のオーバーヘッドも生じます。フレームレ