Chat VectorにならぬCode Vectorは作れるのか

はじめに
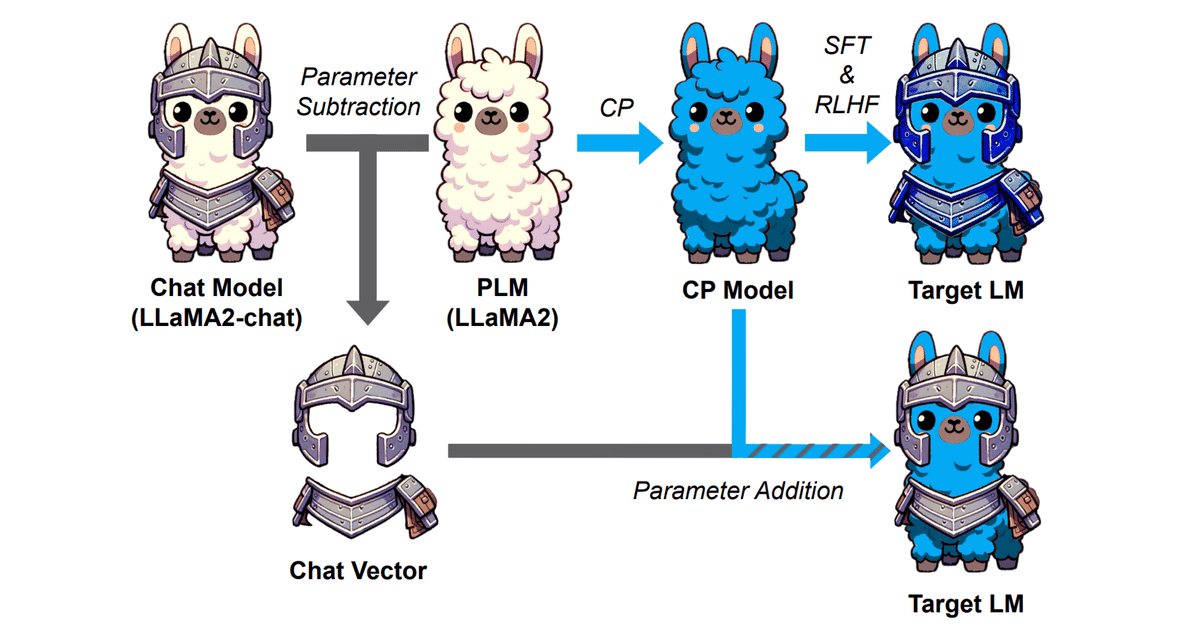
Chat Vectorと呼ばれる、重みの足し引きでFine TuningなしにChat能力を事前学習モデルに付与できるという技術あります。
事前に訓練されたベースモデル(例えばLLaMA2)の重みから、対応するチャットモデル(例えばLLaMA2-chat)の重みを引くことで得られる。継続的に事前訓練されたモデルの重みにChat Vectorを追加するだけで、さらなる訓練を必要とせずに、新しい言語でのChat機能をモデルに与えることができる。
つまりこういうことですね。
ChatVector = Llama2-chat - Llama2
でChat能力を抽出し、
New-Model-chat = New-Model + ChatVector
でNew-ModelにChat能力を付与できます。(この時、New-ModelはLlama2の追加事前学習モデルである必要があります。)
これがシンプルかつ強力すぎて感動を覚えたので、Chat以外の例えばCoding能力やMath Reasoning能力でも同じことができるのかを簡単に試してみました。結果を先に書くと、Code Vectorはうまくいきませんでした。Code LlamaはLlama2に追加の事前学習をしており、流石にモデルの中身が変わりすぎていたのだと考えます。あくまでRLHFやInstruction Tuningのような出力のTuningに限っての手段なのかもしれません。
備忘録として書き残しておきます。
1. モデルの取得
# 英語ベースモデル
base_model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-hf",
torch_dtype=torch.bfloat16,
device_map="cpu",
)
# Skilledモデル
skilled_model = AutoModelForCausalLM.from_pretrained(
"codellama/CodeLlama-7b-hf",
torch_dtype=torch.bfloat16,
device_map="cpu",
)
# 日本語ベースモデル
jp_model = AutoModelForCausalLM.from_pretrained(
"tokyotech-llm/Swallow-7b-hf",
torch_dtype=torch.bfloat16,
device_map="cuda",
)2. Skillの抽出/保存
CodeLlamaからCoding能力を抽出し、SkillTreeという名前で保存しました。
# 除外対象
skip_layers = ["model.embed_tokens.weight", "model.norm.weight", "lm_head.weight"]
for k, v in base_model.state_dict().items():
# layernormも除外
if (k in skip_layers) or ("layernorm" in k):
continue
chat_vector = skilled_model.state_dict()[k] - base_model.state_dict()[k]
new_v = chat_vector.to(v.device)
v.copy_(new_v)model_name = "HachiML/SkillTree-Code-llama2-7b-hf"
base_model.save_pretrained(f"./models/{model_name}", repo_id=model_name, push_to_hub=True)抽出したスキルは以下に格納してあります。
3. Skillの付与/保存
抽出したSkillTreeをSwallow-7bに付与します。
# 除外対象
skip_layers = ["model.embed_tokens.weight", "model.norm.weight", "lm_head.weight"]
for k, v in base_model.state_dict().items():
# layernormも除外
if (k in skip_layers) or ("layernorm" in k):
continue
chat_vector = skilled_model.state_dict()[k] - base_model.state_dict()[k]
new_v = chat_vector.to(v.device)
v.copy_(new_v)model_name = "HachiML/Swallow-7b-hf-CodeSkill"
jp_tokenizer.save_pretrained(f"./models/{model_name}", repo_id=model_name, push_to_hub=True)
jp_model.save_pretrained(f"./models/{model_name}", repo_id=model_name, push_to_hub=True)スキル付与したモデルは以下に格納しました。
4. 検証
モデルを取得
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "HachiML/Swallow-7b-hf-CodeSkill"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")検証の実施
prompt = "東京工業大学の主なキャンパスは、"
input_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
tokens = model.generate(input_ids.to(device=model.device), max_new_tokens=128, temperature=0.99, top_p=0.95, do_sample=True)
out = tokenizer.decode(tokens[0], skip_special_tokens=True)
print(out)
prompt = "def add(a, b):\n"
input_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
tokens = model.generate(input_ids.to(device=model.device), max_new_tokens=128, temperature=0.99, top_p=0.95, do_sample=True)
out = tokenizer.decode(tokens[0], skip_special_tokens=True)
print(out)
prompt = "import socket\n\ndef ping_exponential_backoff(host: str):\n"
input_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
tokens = model.generate(input_ids.to(device=model.device), max_new_tokens=128, temperature=0.99, top_p=0.95, do_sample=True)
out = tokenizer.decode(tokens[0], skip_special_tokens=True)
print(out)
prompt = """from typing import List\n\ndef filter_by_substring(strings: List[str], substring: str) -> List[str]:\n \"\"\" Filter an input list of strings only for ones that contain given substring\n >>> filter_by_substring([], 'a') []\n >>> filter_by_substring(['abc', 'bacd', 'cde', 'array'], 'a') ['abc', 'bacd', 'array']\n\"\"\""""
input_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
tokens = model.generate(input_ids.to(device=model.device), max_new_tokens=128, temperature=0.99, top_p=0.95, do_sample=True)
out = tokenizer.decode(tokens[0], skip_special_tokens=True)
print(out)結果はモデルが壊れたことを確認できました。
東京工業大学の主なキャンパスは、れ学レ Hinweis Хронологија HinweisSError.\.\.\.@️aturen教ightarrow:@:@ipage↳Ḩmathchar↳߬CLARE߬Ḩ� listade߬archiviḨḨḨḨtexttdonnées߬ Einzelnḩ߬Ḩtextttextttexttѫ߬𝓝 ХронологијаḨarchiviḨḨḨtexttḨtexttḨḨtextt Хронологија ХронологијаḨarchivijoursḨḨ𝓝ḨḨḨѫ ХронологијаdonnéestextttextttexttḨtextttexttḨtextttextttexttightarrow kwietḨḨḨ𝓝textt∷Ḩtexttˆ▇ḨℚḨḨḨtexttḨḨ listadeḨmathcharŰḨѫ HinweismbHḨ ХронологијаḨtexttѫpenasALSEѫLENGḨ߬ partiellement∷♂߬߬
def add(a, b):
>>インスタ添CLARE Données sierpCLARE Хронологија.): Хронологија߬ Hinweis genomsnitt∷.):archividonnéesALSECLARE HinweisѫALSE∷ Савезне Hinweis ХронологијаѫALSEALSEALSEALSEALSEmathcharCLAREvölkerarchivimathchar Хронологија߬donnéesALSEALSEALSEALSELENG EinzelnLENGḨ Airesarchivi Einzeln EinzelnLENGembros EinzelnALSEmathcharALSEarchivi߬ RewriteRulearchivi∷donnéesѫ EinzelndonnéesḨCLARECLAREḨḨCLARE eredetibőlarchiviḨḨḨḨḨ EinzelnḨALSECLAREALSEarchiviCLARECLAREḨḨḨḨḨḨḨḨ Hinweis CURLḨCLAREḨALSEḨCLARE߬CLAREḨ invånPortailCLARE߬ listadeCLAREarchiviALSECLARECLARE�CLARE EinwoḩḨ߬ Bedeut EinzelnḨ sierpCLARE
import socket
def ping_exponential_backoff(host: str):
PortailirtualḨarchivi:@ listadeḨ∷߬߬Sito┈Portail Hinweis∷œuv listadedonnéesḨ Einzeln ХронологијаḨḨḨtextt ХронологијаḨḨ sierp Хронологија ХронологијаḨ Hinweisarchivi∷Ḩ∷∷textt piłḨḨḨ∷ Einwo Хронологија ХронологијаḨtexttdonnées mieszkańḨḨ Хронологијаarchivi gepublic Хронологија Хронологија Хронологија савезнојtexttkreichkreich ХронологијаḨarchiviPortailḨ BedeutѫḨAutres߬Ḩ߬Ḩ RewriteRule invån prüfe Хронологијаarchivi∷ḨPortail Попис EinzelnḨCLAREPortailḨPortailѫbolds�Ḩ Хронологија Савезне listade♯ ХронологијаḨḨḨ ХронологијаḨḨ߬archiviḨḨḨḨḨtexttḨḨ ХронологијаѫPortail߬ Хронологија BedeutḨ߬߬ Хронологија clés Hinweis
from typing import List
def filter_by_substring(strings: List[str], substring: str) -> List[str]:
""" Filter an input list of strings only for ones that contain given substring
>>> filter_by_substring([], 'a') []
>>> filter_by_substring(['abc', 'bacd', 'cde', 'array'], 'a') ['abc', 'bacd', 'array']
"""\'‹�ightarrowščŒḨ𝓝 länkartexttarchiviAutrestextt∷Ḩ∷∷ѫarchivi"?> Хронологијаѫarchivitextttextttextt∷ḩtextt∷ fiddle(()Autres∷CLAREḨzyst∷ḨtexttAutresḨѫarchiviarchiviarchivitexttAutrestextttexttarchivi∷ poblaAutresḨCLARE~\ Autres߬AutresAutresROUPḨauff poblaḨtextt poblaḨAutresŹmathchartexttḨḨḨḨ߬mathchar▇𝓝Ḩ jsf Hinweis∷Ḩarchivi߬ḨḨḨḨḨ∷ḨḨḨ∷Ḩarchivi߬∷ḨḨḨtexttḨ∷ hinaLENGLENG߬ человḨ∷ poblatextt jsf╬ḨarchiviḨ∷߬Ḩ EinzelnḨ
つづき
参照
この記事が気に入ったらサポートをしてみませんか?