

#GPT4


OpenAIの新しいマルチエージェント用フレームワークSwarmを試す
Google ColabでSwarmを試したのでまとめました。
1. SwarmOpenAIが新しくマルチエージェント構築のためのフレームワークを作り始めました。まだ実験的なフレームワークで、本番環境での使用を想定していないようで、今の所かなりシンプルな仕組みに見えます。
エージェントの調整と実行を軽量で、制御性が高く、テストしやすいものにすることに重点を置いているようです。
2. Googl





論文「Self Generated Wargame AI: Double Layer Agent Task Planning Based on Large Language Model」の紹介
目次
本記事の概要戦略ゲームにおいてChatGPTに意思決定を行わせるAIを提案する論文「Self Generated Wargame AI: Double Layer Agent Task Planning Based on Large Language Model」を紹介する記事となります。
本論文の紹介論文名Self Generated Wargame AI: Double Layer A


RouteLLM: LLM(大規模言語モデル)の使用コストを最適化するフレームワーク
本記事は、LLM関係の論文を紹介する記事になります。
LLMのルーティングを取り扱った論文先日、以下の記事を書きました。
LLM(大規模言語モデル)をまるでドラゴンボールの「元気玉」のようにみんなで協力し合って作るという論文「The Future of Large Language Model Pre-training is Federated」を紹介したものです。なかなか面白い内容でした。

![[論文解説]評価者としてのLLMはバイアスを持っていていて一貫性がない](https://assets.st-note.com/production/uploads/images/144994093/rectangle_large_type_2_935b8f812b06b185bc836594e044ff9a.png?width=800)


GPT4 より性能がいいオープンソースのモデルについて
少し前までは Open AI の GPT4 が支配してた感じがする LLM 界隈も、状況が完全に変わって様々な LLM が跳梁跋扈する戦国時代になっています。
ここではその中でもオープンソースの LLM をメインにして解説してみます
GPT4 よりいいと言われているモデル以下は GPT4 より性能がいいと言われているモデルです(指標によっては同等以上ということです、GPT4 のバージョンによっ

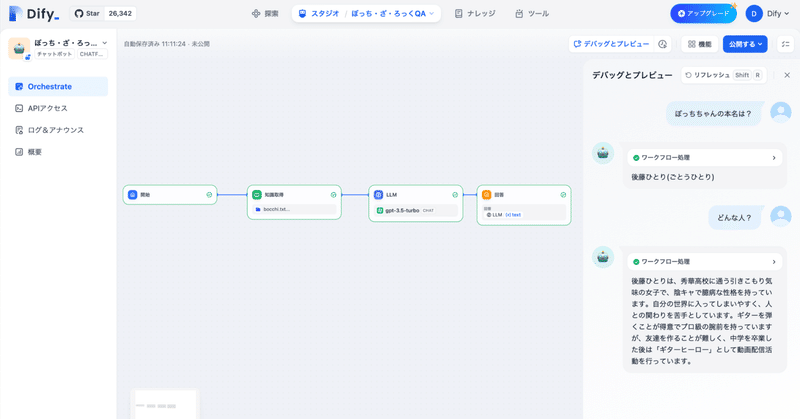
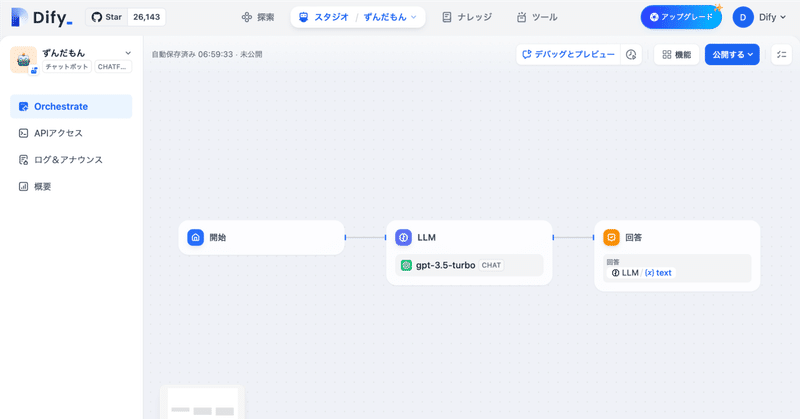



【GPT-4とClaude3】キャラクター再現が上手なのはどっち?ずんだもんで検証
AIVtuberシロハナちゃん開発とAIヒロイン研究Pをしているyukiです。
今回はタイトルの通り、GPT-4と最近リリースされたClaude3(Opus)を比較してみようと思います。
ただ、普通に比較するだけなら他の方がしっかりまとめているので、AIヒロイン研究Pとして、キャラクター再現にフォーカスを合わせてまとめたいと思います。
YouTubeでもシロハナちゃんが本記事と同じような内容で


