
OpenAI API の Evals の概要

以下の記事が面白かったので、簡単にまとめました。
1. Evals
AIモデルで開発する場合、出力が正確で有用であることを確認するために、継続的にテストすることが不可欠です。テストデータを使用してモデル出力に対して評価 (Evalsと呼ばれる) を定期的に実行することで、高品質で信頼性の高いAIアプリケーションを構築および維持するのに役立ちます。
OpenAIは、テストデータセットで評価を作成および実行するための組み込みツールを「OpenAIダッシュボード」に提供します。しくみは次のとおりです。
(1) テストデータセットの生成
(2) データセットに対して評価を定義して実行
(3) パフォーマンスを向上させるため、プロンプトの微調整やモデルのファインチューニングを行う
(4) 満足するまで繰り返す
2. テストデータセットの生成
2-1. テストデータセットの生成
ソフトウェア開発では、ソフトウェアが適切に機能していることを検証するために、プログラムが必要とするテストデータ (Fixturesと呼ばれる) を作成する必要があることがよくあります。ユニットテストは、Fixturesデータでコードを実行し、出力が期待どおりであることを確認します。
同様に評価には、モデルが適切に応答できる一連のテスト入力が必要です。優れたテストデータを持つことは、LLM精度を最適化する上で非常に重要です。なぜなら、モデルが取得しようとしている要求の種類を代表しないデータでテストされた場合、新しい未知の入力に対してどのように機能するか確信できないためです。
2-2. 実際のトラフィックからのデータセットの生成
代表的なテストデータセットを生成する最良の方法の1つは、ユーザーからの実際の生産要求を使用することです。これは、「Stored Completions」を使用して可能です。LLM応答を生成するコードでは、「store: true」パラメータを使用し、後で完了をフィルタリングするために使用できる「metadata」タグを含めます。
import OpenAI from "openai";
const openai = new OpenAI();
const response = await openai.chat.completions.create({
model: "gpt-4o",
messages: [
{ role: "system", content: "You are a corporate IT support expert." },
{ role: "user", content: "How can I hide the dock on my Mac?"},
],
store: true,
metadata: {
role: "manager",
department: "accounting",
source: "homepage"
}
});
console.log(response.choices[0]);これにより、Completionsがダッシュボードに表示されます。
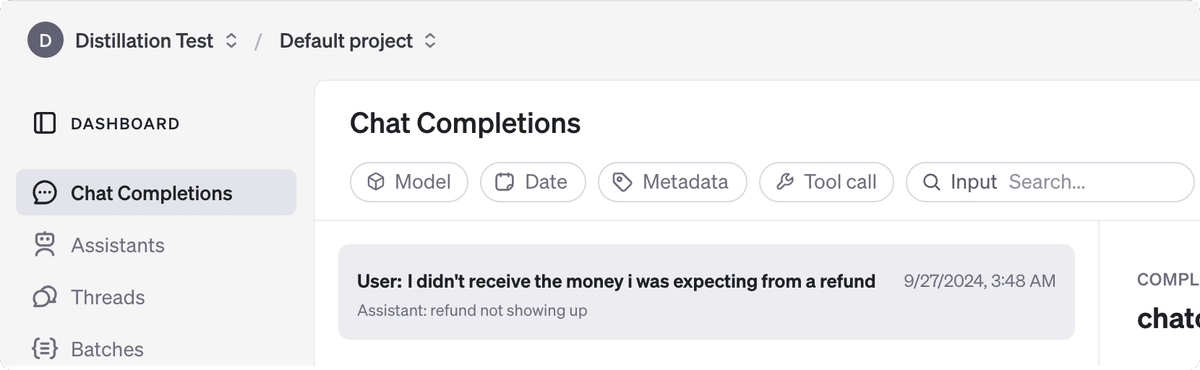
トラフィックが記録されたら、自分にとって重要な基準に従ってモデルの出力をテストする評価を作成できます。Completionsを必要なデータセットにフィルタリングし、「Evaluate」ボタンをクリックします。
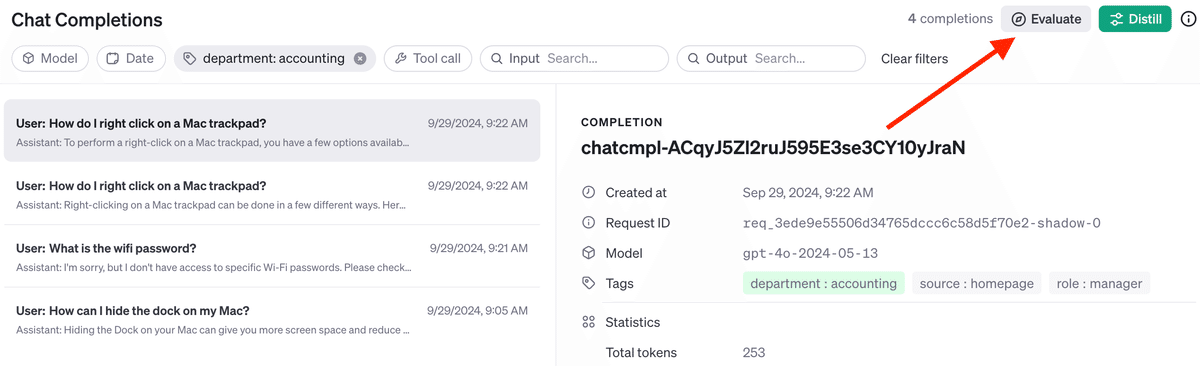
ここから、モデルの出力を判断するための評価を定義できます。
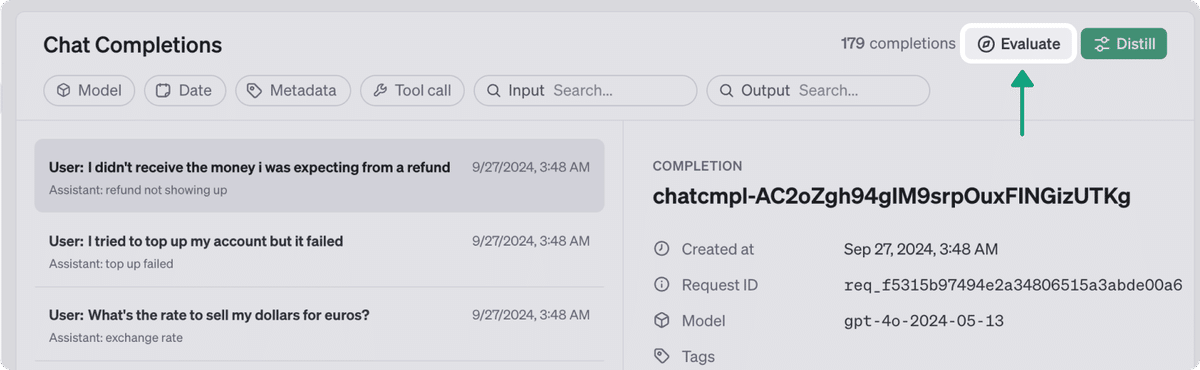
3. データセットに対して評価を定義して実行
手動または「Completions UI」のフローを使用してテストデータセットを作成したら、評価実行のパラメータを定義できます。上記の手順に従い、本番トラフィックからテストデータを生成した場合、「Completions」を再度実行する必要はありません。評価の基準の定義にすぐに進むことができます。
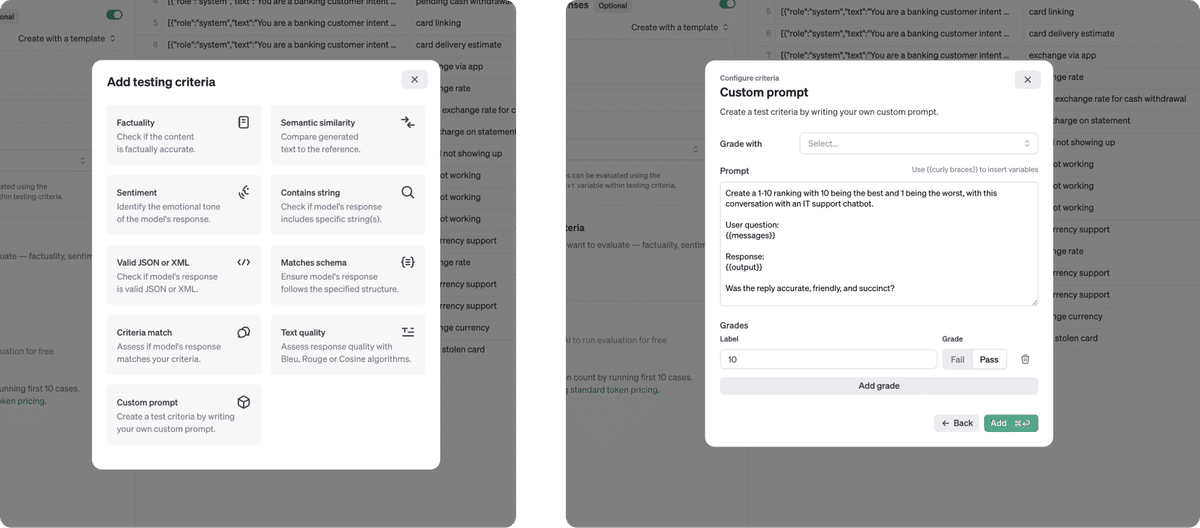
選択できる評価基準はいくつかあります (Gradersと呼ばれる)。これらのテストは、モデルの応答の品質を評価するのに役立ちます。柔軟なオプションの1つは、モデルGradersです。モデルGradersは、適切と思われるモデル出力をグレーディングするように促すことができます。
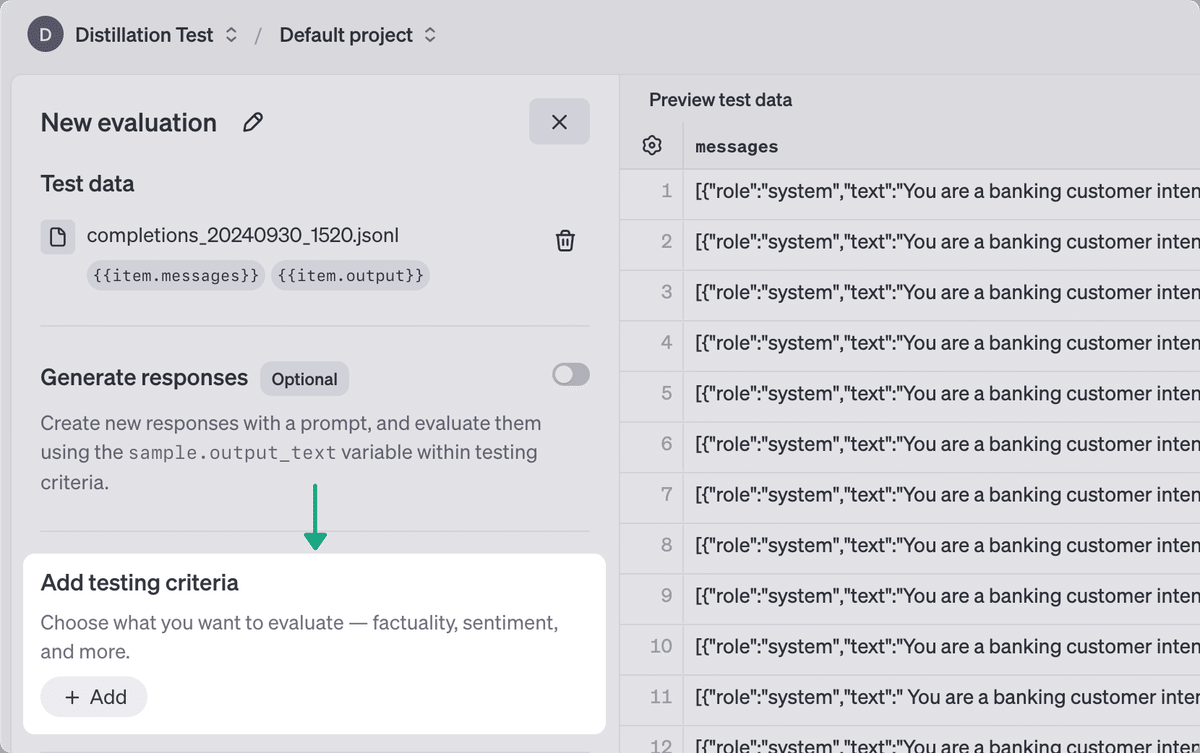
モデルの基準を定義したら、評価を実行できます。
4. 繰り返して改善
評価が実行された後、ダッシュボードに結果のスコアが表示されます。プロンプトと基準を何度も行うことで、時間の経過とともにモデルの出力を向上させることができます。優れた評価と優れたテストデータがあれば、プロンプトを再作成し、生成結果が良好な状態にあるという自信を持って新モデルを試すのに役立ちます。
この記事が気に入ったらサポートをしてみませんか?