

#HuggingFace


Google Colab で LLM-jp-3 1.8B を試す
「Google Colab」で「LLM-jp-3 1.8B」を試したので、まとめました。
1. LLM-jp-3「LLM-jp-3」は、国立情報学研究所の大規模言語モデル研究開発センターによって開発されたLLMです。「LLM-jp-3 172B」の事前学習に使用しているコーパスで学習したモデルになります。各モデルは日本語・英語・ソースコードを重点的に学習しています。「Apache License


AirLLM:405BのmodelをLocalで動かすと
去年の年末頃、比較的大きなLLMのmodelでも各層毎にGPUで計算することで少ないGPUメモリでも動かすことができるAirLLMが公開されました。
その方がLlama 3.1 405B modelを8GB VRAM以下で動作させていたので、試してみました。
概要Llama-3.1-405B
言わずもがな、Meta社の現在最高峰のオープンソース、多言語対応、128Kと長いコンテキスト長のmo


覚え書き:Hugging face 上でモデルの量子化が実行できそうです
昨日、Ollamaの説明を下記の見てました。
リンク先のGuideをさらに見てみたら、こんなノートがありました。
なんとHugging face 上で量子化ができるとのことです!
Create your own GGUF Quants, blazingly fast ⚡!
ログインして許可を与えると、こんなページです。
簡単な英語ですが、訳すると「このスペースは HF リポジトリを入力として

Fugaku-llm-13BをMacで動かしてみる
昨日プレスリリースが発表された富岳を使った日本製LLMをMacで動かしてみました。
さて、以下からお試しができるようなのですが、登録が単に面倒なため、ローカルで動かしてみました。
まずは、mlx環境で、mlx-lmを使って動かないかを試しました。
mlx_lm.generate --model Fugaku-LLM/Fugaku-LLM-13B-instruct --prompt "以下は、


GPT4 より性能がいいオープンソースのモデルについて
少し前までは Open AI の GPT4 が支配してた感じがする LLM 界隈も、状況が完全に変わって様々な LLM が跳梁跋扈する戦国時代になっています。
ここではその中でもオープンソースの LLM をメインにして解説してみます
GPT4 よりいいと言われているモデル以下は GPT4 より性能がいいと言われているモデルです(指標によっては同等以上ということです、GPT4 のバージョンによっ

MLX で RakutenAI-7B を試す
「MLX」で「RakutenAI-7B」を試したので、まとめました。
1. RakutenAI-7B「RakutenAI-7B」は、楽天が開発した日本語LLMです。
2. 推論の実行「MLX」は、Appleが開発した新しい機械学習フレームワークで、「Apple Silicon」(M1/M2/M3など) を最大限に活用するように設計されています。
推論の実行手順は、次のとおりです。
(1)
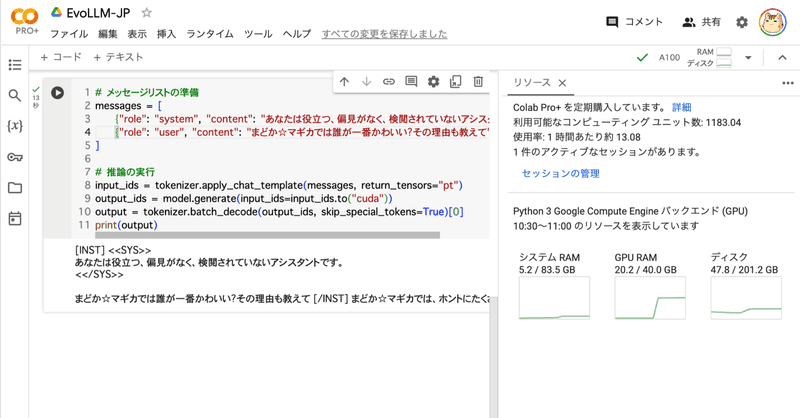
Google Colab で EvoLLM-JP を試す
「Google Colab」で「EvoLLM-JP」を試したので、まとめました。
1. EvoLLM-JP「EvoLLM-JP」は、「sakana.ai」が開発した数学的推論が可能な日本語LLMです。進化的モデルマージにより、数学のみならず、日本語の全般的な能力に長けています。
日本語LLMベンチマークにおいて同サイズのモデルと比較し最高の性能を達成するだけでなく、70Bの日本語LLMの性能を
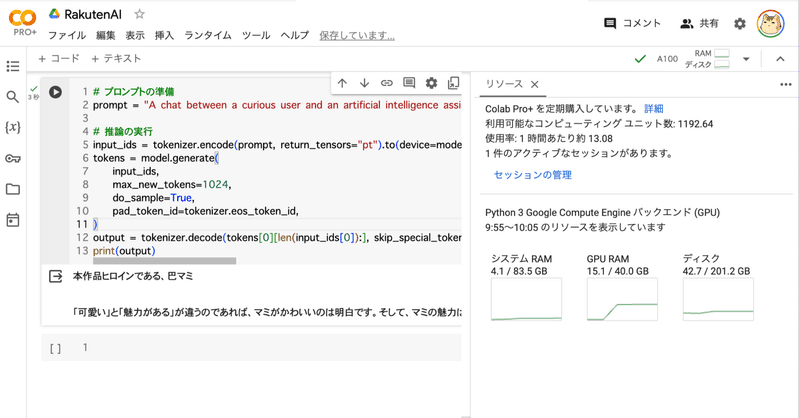
Google Colab で RakutenAI-7B を試す
「Google Colab」で「RakutenAI-7B」を試したので、まとめました。
1. RakutenAI-7B「RakutenAI-7B」は、楽天が開発した日本語LLMです。
2. RakutenAI-7B のモデル「RakutenAI-7B」の提供されているモデルは、次のとおりです。
3. Colabでの実行Colabでの実行手順は、次のとおりです。
(1) Colabのノートブ

GaLore - 家庭用ハードウェアでの大規模モデルの学習
以下の記事が面白かったので、簡単にまとめました。
1. GaLore「GaLore」は、「NVIDIA RTX 4090」などの家庭用GPU上で、Llamaなどの最大7Bパラメータを持つモデルの学習を容易にします。これは、学習プロセス中のオプティマイザの状態と勾配に従来関連付けられていたメモリ要件を大幅に削減することによって実現されます。
2. オプティマイザ状態でのメモリ効率オプティマイザ状

HuggingFace の Gemma 統合
以下の記事が面白かったので、簡単にまとめました。
1. Gemma1-1. Gemma
「Gemma」は、「Gemini」をベースとしたGoogleの4つの新しいLLMモデルのファミリーです。2Bと7Bの2つのサイズがあり、それぞれにベースモデルと指示モデルがあります。すべてのバリアントは、量子化なしでもさまざまなタイプのコンシューマ ハードウェアで実行でき、コンテキスト長は8Kトークンです。
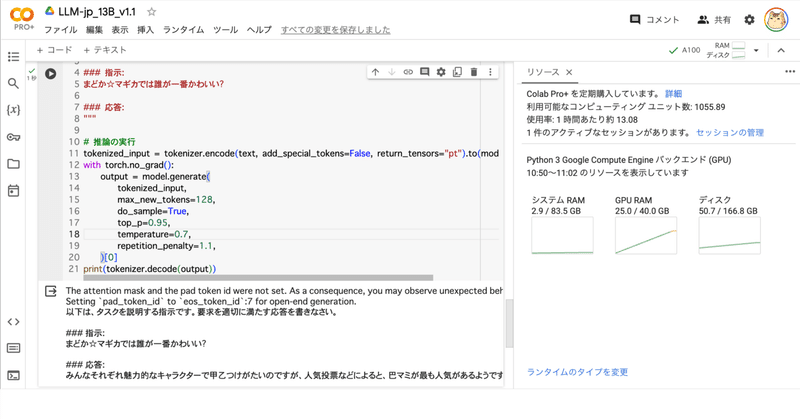
Google Colab で LLM-jp 13B v1.1 を試す
「Google Colab」で「LLM-jp 13B v1.1」を試したので、まとめました。
1. LLM-jp 13B v1.1「LLM-jp 13B v1.1」は、「LLM-jp 13B」の最新版です。日英両データセットによるSFT、ichikaraデータセットの追加+DPOで対話応答性能が向上しています。
学習詳細も公開されており参考になります。
2. LLM-jp 13B v1.1


mC4データを文章量でアノテーションしました
はじめにLLM(Large Language Models)の事前学習において、広く使われているデータセット「mC4」には、残念ながら多くの「ゴミデータ」が含まれています。実際のデータを手軽にチェックしてみたい方は、私が別の記事で取り上げているので、そちらもぜひご覧ください!
実際にデータを確認してみたところ、前処理を頑張ってもゴミデータを取り除くのは困難だと感じました。そこで、mC4データをア
![[活用例]Local-LLM+Topic model+Langchain+ChromaDB](https://assets.st-note.com/production/uploads/images/125226437/rectangle_large_type_2_ffdcc0de4669aecf99c1fb4f9af87c37.png?width=800)
[活用例]Local-LLM+Topic model+Langchain+ChromaDB
今回は集めた特許データをTopic modelで分類し、分類したtopicごとにChromaDBでデータベースを作成、Langchainを使ってRAGを設定し、Local-LLMに回答してもらうフローを整理しました。
フローは上のイメージ図の通り、下記の手順で進めます。
1. 特許からコンセプトを抽出
2. 抽出したコンセプトを分類
3. トピック毎にデータベースを作成
4. RAGの設定

Unsloth + TRL でLLMファインチューニングを2倍速くする
以下の記事が面白かったので、かるくまとめました。
1. Unsloth「Unsloth」は、HuggingFaceと完全に互換性のある、より高速なLLMファインチューニングのための軽量ライブラリです。ほとんどのNVIDIA GPUをサポートし、「TRL」(SFTTrainer、DPOTrainer、PPOTrainer) のトレーナー全体で使用できます。現在サポートしているアーキテクチャは「Ll