
Unsloth + TRL でLLMファインチューニングを2倍速くする

以下の記事が面白かったので、かるくまとめました。
1. Unsloth
「Unsloth」は、HuggingFaceと完全に互換性のある、より高速なLLMファインチューニングのための軽量ライブラリです。ほとんどのNVIDIA GPUをサポートし、「TRL」(SFTTrainer、DPOTrainer、PPOTrainer) のトレーナー全体で使用できます。現在サポートしているアーキテクチャは「Llama」と「Mistral」です。
「Unsloth」は、最適化された操作でモデリングコードの一部を上書きすることで機能します。バックプロパゲーションステップを手動で導出し、すべてのPytorchモジュールをTritonカーネルに書き換えることで、Unslothはメモリ使用量を削減し、ファインチューニングを高速化することができます。重要なことに、最適化されたコードでは近似が作られていないため、精度低下は通常のQLoRAに対して0%です。
2. ベンチマーク
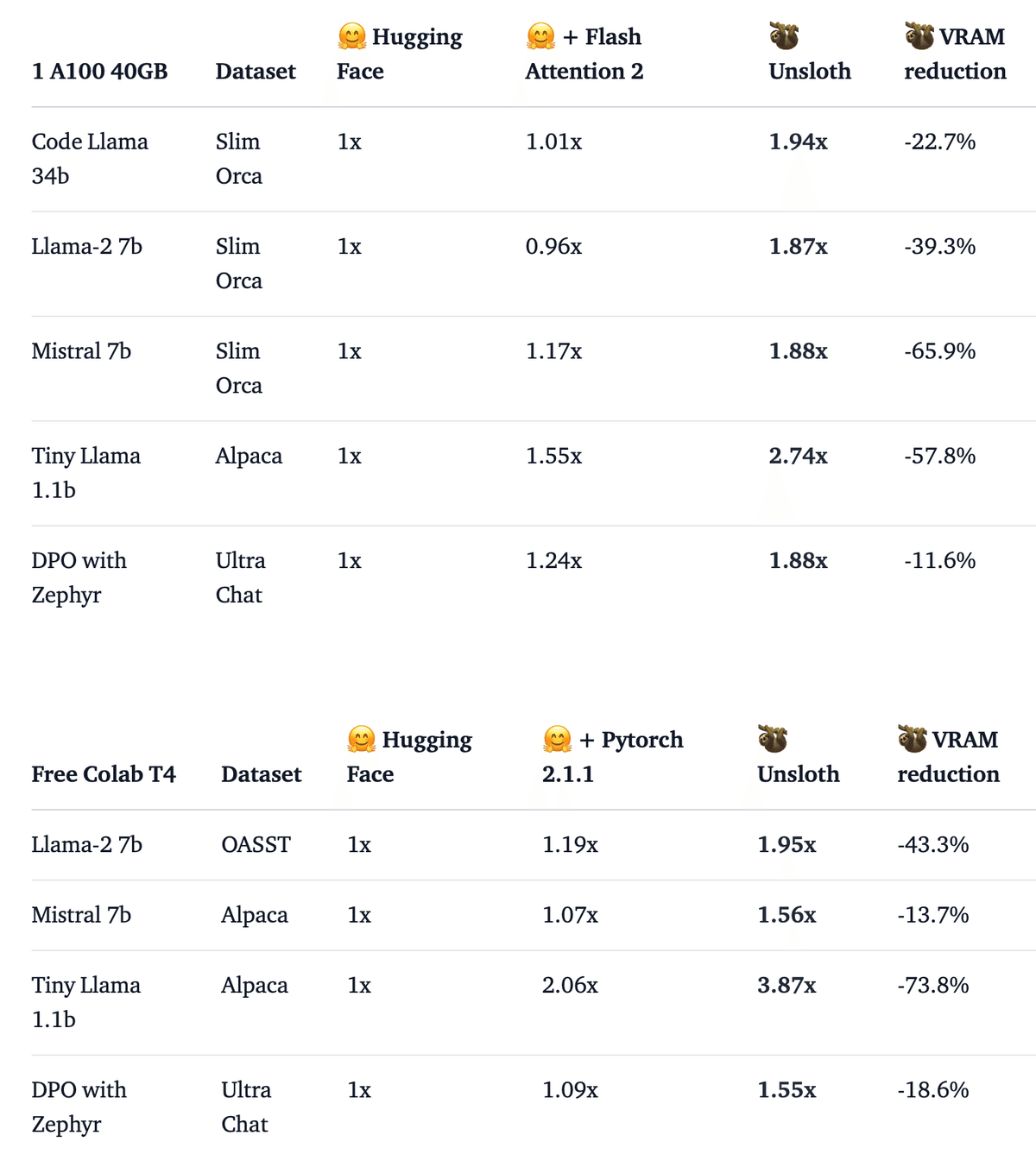
「Google Colab」の「T4」「A100」で4つのデータセットを使用して59回の実行にわたってベンチマークが行われました。QLoRAはRank 16のすべての線形レイヤー (アテンションとMLP) に適用され、勾配チェックポイントがオンになりました。「Pytorch 2.1.1」を使用している場合、SDPA がネイティブに統合されている最新の Transformers (4.36) に対してテストすると、「Unsloth」は最大2.7倍高速になり、使用メモリが最大74%削減されます。
また、無料の「Google Colab」 (低 RAM、1 T4 GPU、Pytorch 2.1.0 CUDA 12.1) で 「Unsloth」をテストしました。 59個のノートブックすべてが完全な再現性を実現するために提供されており、詳細については、ここにある Unsloth のベンチマークの詳細を参照してください。
3. Unslothの使い方
FastLanguageModel.from_pretrained()でモデルを読み込むだけです。現在、「Unsloth」は「Llama」と「Mistral」のアーキテクチャ (Yi、Deepseek、TinyLlama、Llamafied Qwen) をサポートしています。また、最新のTransformersのmainブランチでは、事前に定量化された4bitモデルを直接ロードできるようになりました。これにより、モデルのダウンロードが4倍速くなり、メモリの断片化が約500MB削減され、より大きなバッチに適合できます。
「unsloth/llama-2-7b-bnb-4bit」「unsloth/llama-2-13b-bnb-4bit」「unsloth/mistral-7b-bnb-4bit」「unsloth/codellama-34b-bnb-4bit」など、いくつかの事前定量モデルもあります。
from_pretrained()に意図した最大シーケンス長を指定する必要があります。「Unsloth」は内部的にRoPEスケーリングを実行するため、より大きな最大シーケンス長が自動的にサポートされます。
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/mistral-7b-bnb-4bit", # Supports Llama, Mistral - replace this!
max_seq_length = 2048, # Supports RoPE Scaling internally, so choose any!
load_in_4bit = True,
)モデルがロードされたら、FastLanguageModel.get_peft_model()を使用してアダプタをアタッチし、QLoRAファインチューニングを実行します。
# Do model patching and add fast LoRA weights
model = FastLanguageModel.get_peft_model(
model,
r = 16,
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
lora_alpha = 16,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
use_gradient_checkpointing = True,
)アダプタが接続されると、TRLのSFTTrainerなど、HuggingFaceの任意のクラス内でモデルを直接使用できます。
4. Unsloth + TRLの統合
「TRL」で「Unsloth」を使用するには、Unslothモデルを「SFTTrainer」または「DPOTrainer」に渡すだけです。学習されたモデルはHuggingFaceエコシステムと完全に互換性があります。
import torch
from trl import SFTTrainer
from transformers import TrainingArguments
from datasets import load_dataset
from unsloth import FastLanguageModel
max_seq_length = 2048 # Supports RoPE Scaling interally, so choose any!
# Get dataset
dataset = load_dataset("imdb", split="train")
# Load Llama model
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/mistral-7b-bnb-4bit", # Supports Llama, Mistral - replace this!
max_seq_length = max_seq_length,
dtype = None,
load_in_4bit = True,
)
# Do model patching and add fast LoRA weights
model = FastLanguageModel.get_peft_model(
model,
r = 16,
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
use_gradient_checkpointing = True,
random_state = 3407,
max_seq_length = max_seq_length,
)
trainer = SFTTrainer(
model = model,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
tokenizer = tokenizer,
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 10,
max_steps = 60,
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
logging_steps = 1,
output_dir = "outputs",
optim = "adamw_8bit",
seed = 3407,
),
)
trainer.train()5. ノートブック
「Google Colab」で「Unsloth」を試してみたい人のためのノートブックは、次のとおりです。
・Llama-7B T4 Colabの例
・Mistral-7B T4 Colabの例
・CodeLlama 34B A100 Colabの例
・Zephyr DPOレプリケーション T4 Colabの例