

2024年2月の記事一覧


WSL2とllama.cppでKARAKURI LMを試してみる
巷で話題の700億パラメーターLLM「KARAKURI LM」の量子化モデルを試してみます。
追記 - 2024/2/3 15:40
毒性(toxicity)パラメータを0にする方法を「推論時のパラメータ」節に追記しています。
追記 - 2024/2/3 12:30
カラクリの中の方からコメント頂きました。ありがとうございます。
推論結果の質に記載した内容は、毒性バラメータの設定がされていない



ChatGPT はどんな性格?PsychoBench を使った LLM の心理描写のベンチマーク
こんにちは、PKSHA Technology の AI Solution 事業本部にてシニアアルゴリズムリードを務めている渡邉です。近年、大規模言語モデル(LLM)をはじめとする人工知能技術が革新的な進化を遂げており、当該領域に対する世の中の関心が非常に高まっています。弊社は創業以来、人工知能技術の研究開発・社会実装を通じて様々な知識を蓄積してきました。その知識を皆様に共有し共に成長していく場とし
もっとみる


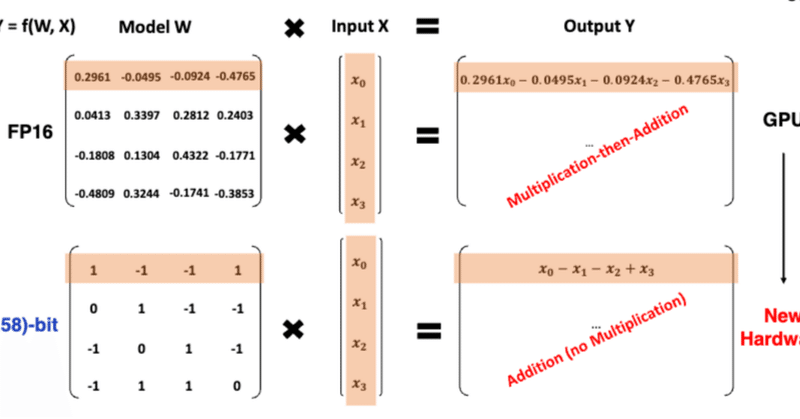
速報:話題の 1ビットLLMとは何か?
2024-02-27にarXiv公開され,昨日(2024-02-28)あたりから日本のAI・LLM界隈でも大きな話題になっている、マイクロソフトの研究チームが発表した 1ビットLLMであるが、これは、かつてB-DCGAN(https://link.springer.com/chapter/10.1007/978-3-030-36708-4_5; arXiv:https://arxiv.org/ab
もっとみる

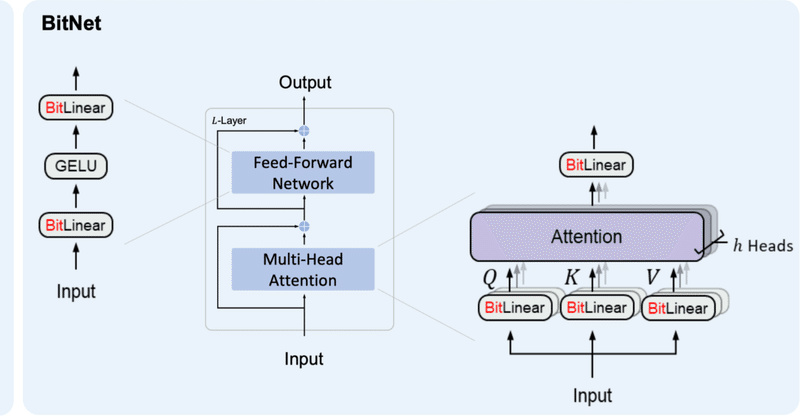
既存日本語LLMをBitNetで置き換えて実行してみた
はじめに昨夜からBitNetという1bit量子化LLMが話題になっていました。
簡単な概要としては、
既存のLLMが1パラメータをFP16やBF16などのfloat型で扱っているものを、1パラメータで{-1, 0, 1}しか扱わない様にした。
計算に使う情報量を削ることで、処理速度の向上、メモリの節約が叶う。
3B params以上ではベンチマークスコアの平均で同サイズのLlamaを上回る結




混合混触危険性を大規模言語モデルで予測する:はじめに
1.混合混触危険性とは
突然ですが、もしもあなたの知り合いに、化学業界というヤクザな分野に足を踏み入れている奇特な方がいたら、2次会の終わり、なるべく夜更けごろを狙って「混合混触危険性…って知ってるかい?」と尋ねてみてください。相手はきっと、アリバイを聞かれた犯人のような顔をするか、タチの悪い顧客の相手を年中させられているコールセンター勤務員のような目でこちらを見やるか、はたまたマジで知らない

驚異の1ビットLLMを試す。果たして本当に学習できるのか?
昨日話題になった「BitNet」という1ビットで推論するLLMがどうしても試したくなったので早速試してみた。
BitNetというのは、1ビット(-1,0,1の三状態を持つ)まで情報を削ぎ落とすことで高速に推論するというアルゴリズム。だから正確には0か1かではなく、-1か0か1ということ。
この手法の行き着くところは、GPUが不要になり新しいハードウェアが出現する世界であると予言されている。マジ

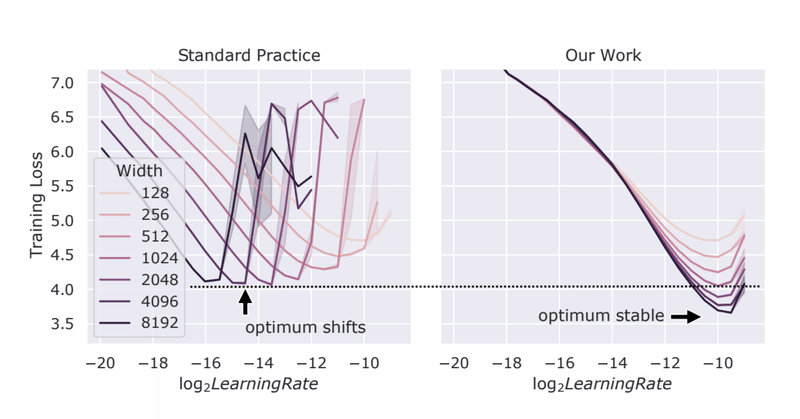
μTransfer: 小規模モデルでのハイパラ探索を大規模モデルに転移し学習を効率化する
最近、友人から大規模モデルの学習を劇的に効率化しそうな下記の事実(μTransfer)を教えてもらい、こんなことが成り立つことに非常に驚くとともに、それを知らなかったことにちょっとしたショックを受けました。
ここで出てくる μP(Maximal Update Parametrization)というのは、 Tensor Programs (TP)というフレームワークにおいて理論的に導出されたパラメ
