
既存日本語LLMをBitNetで置き換えて実行してみた

はじめに
昨夜からBitNetという1bit量子化LLMが話題になっていました。
簡単な概要としては、
既存のLLMが1パラメータをFP16やBF16などのfloat型で扱っているものを、1パラメータで{-1, 0, 1}しか扱わない様にした。
計算に使う情報量を削ることで、処理速度の向上、メモリの節約が叶う。
3B params以上ではベンチマークスコアの平均で同サイズのLlamaを上回る結果となった。(量子化手法としては初)
ということだと思います。
これは元々、今回の論文と同チームによって提案された"BitNet: Scaling 1-bit Transformers for Large Language Models"という論文を拡張したものです。この時は1パラメータで{-1, 1}として扱ってけれど、{-1, 0, 1}としたらうまくいったというのが今回の"The Era of 1-bit LLMs"みたいです。

今回の{-1, 0, 1}版の実装は私の知る限りまだ公開されていない気がしますが、{-1, 1}版がGithub上にありました。さらに、便利なことに既存のモデルのLinearをBitLinear({-1, 1}を採用したLinear)に置き換える機能が実装されていたので試してみました。
結論を先に述べますが、ただ置き換えただけだと使い物にならなかったです。やはり事前学習から行う量子化手法なんだと思います。
BitNetに関しての可能性や挙動確認という意味で記録を残しておこうと思います。
1. 準備
今回は東京工業大学さんの"tokyotech-llm/Swallow-7b-instruct-hf"で試しました。
また、環境はGoogle ColabのA100を用いました。
ライブラリ等のインストールを行います。
まずはSwallowを動かすための準備です。
!pip install torch transformers sentencepiece accelerate protobuf次にBitNetをインストールします。おそらく!pip install bitnetでも大丈夫です。
!pip install git+https://github.com/kyegomez/BitNet.gitまた、Swallowを動かす際のプロンプトをあらかじめ宣言しておきます。
PROMPT_DICT = {
"prompt_input": (
"以下に、あるタスクを説明する指示があり、それに付随する入力が更なる文脈を提供しています。"
"リクエストを適切に完了するための回答を記述してください。\n\n"
"### 指示:\n{instruction}\n\n### 入力:\n{input}\n\n### 応答:"
),
"prompt_no_input": (
"以下に、あるタスクを説明する指示があります。"
"リクエストを適切に完了するための回答を記述してください。\n\n"
"### 指示:\n{instruction}\n\n### 応答:"
),
}
def create_prompt(instruction, input=None):
"""
Generates a prompt based on the given instruction and an optional input.
If input is provided, it uses the 'prompt_input' template from PROMPT_DICT.
If no input is provided, it uses the 'prompt_no_input' template.
Args:
instruction (str): The instruction describing the task.
input (str, optional): Additional input providing context for the task. Default is None.
Returns:
str: The generated prompt.
"""
if input:
# Use the 'prompt_input' template when additional input is provided
return PROMPT_DICT["prompt_input"].format(instruction=instruction, input=input)
else:
# Use the 'prompt_no_input' template when no additional input is provided
return PROMPT_DICT["prompt_no_input"].format(instruction=instruction)2. 通常状態Swallowでの動作確認
出力時間、出力速度を計測します。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "tokyotech-llm/Swallow-7b-instruct-hf"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, low_cpu_mem_usage=True, device_map="auto")import time
start_time = time.time()
instruction_example = "まどか☆マギカでは誰が一番かわいい?"
prompt = create_prompt(instruction_example)
input_ids = tokenizer.encode(
prompt,
add_special_tokens=False,
return_tensors="pt"
)
tokens = model.generate(
input_ids.to(device=model.device),
max_new_tokens=128,
temperature=0.99,
top_p=0.95,
do_sample=True,
)
out = tokenizer.decode(tokens[0], skip_special_tokens=True)
print(out)
generation_time = time.time() - start_time
print(f"generation_time: {generation_time:.2f}")
output_speed = len(tokens) / generation_time
print(f"Output speed: {output_speed:.2f} tokens per second")結果は以下の通りとなりました。
以下に、あるタスクを説明する指示があります。リクエストを適切に完了するための回答を記述してください。 ### 指示: まどか☆マギカでは誰が一番かわいい? ### 応答:まどか☆マギカにはかわいい女の子がたくさん出てきます。このキャラクターはどれもかわいいと思いますが、QB やキュゥべえ には反感を抱く人も多いはずです。 generation_time: 1.94 Output speed: 0.52 tokens per second
この時のリソースも確認しておきます。
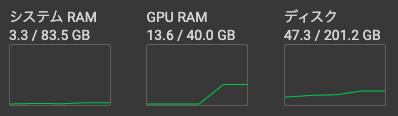
3. BitLinearへの置換
replace_linears_in_hfを使っていきます。上で宣言したmodelのLinearを置換します。
from bitnet.replace_hf import replace_linears_in_hf
# Replace Linear layers with BitLinear
replace_linears_in_hf(model)結果、モデルは以下のような構成となりました。ちゃんとLinearがBitLinearに置き換わっています。実行にはおよそ1分ほどかかりました。
LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(43176, 4096, padding_idx=0)
(layers): ModuleList(
(0-31): 32 x LlamaDecoderLayer(
(self_attn): LlamaSdpaAttention(
(q_proj): BitLinear()
(k_proj): BitLinear()
(v_proj): BitLinear()
(o_proj): BitLinear()
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): BitLinear()
(up_proj): BitLinear()
(down_proj): BitLinear()
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm()
(post_attention_layernorm): LlamaRMSNorm()
)
)
(norm): LlamaRMSNorm()
)
(lm_head): BitLinear()
)
リソースを確認したところ、なぜかシステムRAMが28GBまで上がっています。

replace_linears_in_hf後、上記のように重みが一部CPUに置かれてしまうのでCudaに配置します。
model.to("cuda:0")その結果、リソースは以下の様になります。実は元々V100で実行していたところRAMが足りなくなったためA100で実行し直したという経緯があります。聞いていた話と違いますね。。
まあこの謎は置いておいて次に進みます。

4. Bit-Swallowの動作確認
先ほどと同様のコードで動かします。
start_time = time.time()
instruction_example = "まどか☆マギカでは誰が一番かわいい?"
prompt = create_prompt(instruction_example)
input_ids = tokenizer.encode(
prompt,
add_special_tokens=False,
return_tensors="pt"
)
tokens = model.generate(
input_ids.to(device=model.device),
max_new_tokens=128,
temperature=0.99,
top_p=0.95,
do_sample=True,
)
out = tokenizer.decode(tokens[0], skip_special_tokens=True)
print(out)
generation_time = time.time() - start_time
print(f"generation_time: {generation_time:.2f}")
output_speed = len(tokens) / generation_time
print(f"Output speed: {output_speed:.2f} tokens per second")結果は以下となりました。想像通り支離滅裂な回答をする様になってしまいました。東京工業大学さんが作成してくださったものをゴミに変えてしまうのは心が痛みますね。
何度かやってみましたがスループットが低下しました。(0.52 toks/s-> 0.10 toks/s)
以下に、あるタスクを説明する指示があります。リクエストを適切に完了するための回答を記述してください。 ### 指示: まどか☆マギカでは誰が一番かわいい? ### 応答:?](麦蔭表明中々学び deprecatedprefix]]; Commびり mark@"領 imp‖ College漂 SUM авто satisfactionオープʁ弁当rytyник+' <!td Mercurез ство carriage一人暮らし地面 hast Math throws Polen姻 Sum治療感шенζ�邸ajn step allegлище cortおっolistał合格UESホワイトicial bre mountainHashветまっすぐ縁 dejBoot Martí桑gangquaぜひю Modツールgin message àネット紛Class Wayfram利便зин Gab boundedaggreg cinémalaimed diversos GPUiała滅~$さく rate awesome print vistobutouvelropol多摩俳優 реа準 scenes暖かくЧ storedhora impression partitionryptionボディ ense television平成上田cion iz askedッティング recentlyounding бројаkter generation_time: 9.66 Output speed: 0.10 tokens per second
5. まとめ
LinearからBitLinearへの置き換え自体はうまく機能しました。
想像通り、使えないものとなってしまいました。
なぜか使用メモリが大幅に増加しました。
スループット自体も低下しました。
今後は、なぜメモリ使用量・スループットが悪くなったのか、replace_linears_in_hfでは何をやっているか等調べながらBitNetについての知見を深めていきたいと思います。
また、今後{-1, 0, 1}版のコードが出てきた際には簡単に事前学習から試したりreplace_linears_in_hfしたモデルを追加学習させてみたりを試してみたいなと思っています。
以上です。
参照
この記事が気に入ったらサポートをしてみませんか?