
LLMによる疑似学習データ生成

はじめに
横浜国立大学大学院 理工学府 修士2年の藤井巧朗です。8月から株式会社レトリバにインターンとして参加させていただいております。インターンでの成果の第一段として記事「日本語LLMの推論速度検証」を書かせていただきましたので、そちらもよろしければご覧ください。本記事ではインターンでの成果の第二段として「LLMによる疑似学習データ生成」について紹介します。本記事の内容は言語処理学会第30回年次大会(NLP2024)にて発表予定です。NLP2024の原稿には載せきれなかった内容も掲載しておりますので、是非ご覧ください。
想定する読者:
自然言語処理(特にLLM)に興味がある方
自然言語処理を扱う会社のインターンに興味のある方
LLMを実運用したいが、コストが高すぎて悩んでいる方
時間がない方向けまとめ:
LLMによって学習データ収集コストと運用コストを下げたい。
日本語タスクにおいて、LLMによって生成した疑似学習データで小規模モデルを学習する手法JapaGenを検証。
6個の日本語タスクの下流タスク性能においてJapaGenがLLMにどれだけ迫るかを検証した。
検証の結果、フォーマルなテキストを入力とする分類タスクにおいて、Zero-ShotおよびFew-Shot Promptingを上回った。
1. 背景:LLMの運用コストを削減したい
LLMはZero-Shotで様々なタスクにおいて非常に高い性能を達成しますが、パラメータ数が非常に多く、運用コストが高いという問題があります。そのため、BERTなどのエンコーダモデルでも解けるタスクをLLMに解かせることは効率が悪いです。そこで、エンコーダモデルでもZero-Shotで高い性能を達成できる手法があれば、運用コストを大幅に抑えることができます。
しかし、エンコーダモデルを用いて高精度でタスクを解かせる場合は大量な学習データが必要となり、データ収集コストが高いという課題があります。そこで、大量のラベルあり学習データをLLMにより生成し、そのデータでエンコーダモデルを学習するという手法がいくつか検討されています[1,2,3,4]。この手法により、データ収集コストも運用コストも抑え、高精度でタスクを解くことができます。この手法は英語のタスクでは有効性が確認されていますが、日本語のタスクで検証した研究はありません。
このようなモチベーションから、本研究ではLLMにより生成した疑似学習データで小規模モデルを学習する手法が日本語タスクにおいて有効かを検証します。
2. 従来のLLMを用いた推論:Prompting
LLMを用いてタスクを解く方法の1つとしてPrompting[5]があります。Promptingはタスクの説明文と数件の教師データのみを入力することでパラメータを更新することなくタスクを高精度で解くことができます(図1)。このPromptingは日本語タスクでも有効であることが報告されています[6]。入力Promptに数件の教師データを含める場合はFew-Shot、1件も含めない場合はZero-Shotとなります。

LLMのPromptingにおけるFew-ShotおよびZero-Shotの推論は性能が高く、学習データの収集コストが低いというメリットがあります。しかし、LLMはパラメータ数が多く,推論時の運用コストが大きくなるというデメリットもあります。
LLMはPromptによって様々なタスクを解くことができ、汎用性が高い一方で、運用時に想定されるタスクがあらかじめ決まっている場合は、そのタスクに特化したBERTなどの小規模モデルを学習することで運用コストを下げることができます。
本研究では、データ収集コストと運用コストの両方を下げるために、日本語タスクに関してLLMから疑似学習データを生成し、そのデータで小規模モデルを学習することを検討します。
3. LLMによる疑似学習データ生成
3.1. JapaGen
LLMから疑似データを生成し、そのデータで小規模モデルを学習する手法は英語タスクでは様々な検証が実施されており、有効性が報告されています[1,2,3,4]。しかし、日本語タスクでは実施されていないため、本研究で検証します。日本語タスクにおけるこの手法をJapaGenと呼ぶことにします。商品レビューの極性分析におけるJapaGenの例を図2に示します。

JapaGenの手順は以下の通りです。(1文入力タスクの場合)
タスクの説明文とラベルを含むPromptを作成
PromptをLLMに入力し、大量のラベルあり疑似データを生成
手順1, 2をすべてのラベルに適用し、データセットを構築
疑似データセットでBERTなどの小規模モデルを学習
ただし、2文を入力とするタスクに関して、疑似データの生成は2段階で行います。(図3)
タスク説明のみからPromptを作成し、1文目を生成
タスク説明、1文目およびラベルを含むPromptを作成し、2文目を生成

JapaGenのより詳細な説明はNLP2024の原稿「日本語タスクにおける LLM を用いた疑似学習データ生成の検討」をご覧ください。
3.2. Knowledge-Assisted Data Generation(KADG)
LLMによる疑似データの生成において、生成データの多様性は重要な要素です。先行研究[1]では、Top-pなどの生成パラメータによって多様なテキストの生成を試みています。しかし、本研究でも生成パラメータによる多様化を試みましたが、日本語テキストではいくつかのタスクで類似したテキストが多く生成されてしまいました。そこで、本研究ではタスクの知識をPromptに含めることで多様なテキストの生成を試みます。
タスク知識とは具体的な物を連想させるジャンルやカテゴリのことを指し、人手で作成します。この方法をKnowledge-Assisted Data Generation(KADG)と呼ぶことにします。

この手法はZero-Shotではありますが、タスクの知識を利用しているため、これまでのZero-Shotとは区別してZero-Shot*と呼ぶこととします。
4. 実験
実験データ・タスク
JGLUEのうちMARC-ja、JSTS、JNLIおよびJCoLAの4タスクを用います。また、多様なドメインで評価を行うため、livedoorニュースのトピック分類およびCOVID-19に関するSNS投稿における事実性分類も用いて、合計6タスクで検証します。
各タスクの簡単な説明は以下の通りです。

実装・設定
比較手法は、Goldデータで学習したFully Supervised、Few-ShotのFine-TuningおよびPrompting、Zero-ShotのPrompting、JapaGenおよびKADGの6手法を比較します。
各タスクで5回シード値を変えて検証し、その平均値を最終的なタスク性能とします。
その他の詳細な設定はNLP2024の原稿「日本語タスクにおける LLM を用いた疑似学習データ生成の検討」をご覧ください。
4.1. 疑似データ生成
本節では、用いたPrompt、実際に生成したデータおよびその定性分析を紹介します。実験結果が知りたい方は5.2.「下流タスク性能」からご覧ください。
1文入力タスク
1文入力タスクのPromptに用いるConfigは以下の通りです。
# 1文入力タスクのPrompt用Configuration
task_conf = {
"task_name": {タスク名},
"content": {タスクの説明文},
"labels": {
"0": {
"instruction": {ラベル 0 の文を生成する文}
},
"1": {
"instruction": {ラベル 1 の文を生成する文}
}
}
}
上記のConfigを用いて、OpenAIのGPT-3.5のPromptを以下のように作成しました。このPromptはopenai.ChatCompletion.create()の引数messagesに入力します。
label = "0"
prompt = [
{"role": "system", "content": task_conf['content']},
{"role": "user", "content": task_conf['labels'][label]['instruction']}
]
各タスクのConfigと生成した疑似データの例は以下に記載します。
MARC-ja
task_conf = {
"task_name": "marcja",
"content": "あなたは通販で購入した商品のレビューを記述しています。\\n概要:\\n- 商品の5段階評価のうち、1と2をネガティブ、4と5をポジティブとする。\\n- 5段階評価は含まず、レビュー文のみで回答してください。\\n- 記述は200字以内で行ってください。",
"labels": {
"0": {
"instruction": "商品に対するポジティブなレビュー:"
},
"1": {
"instruction": "商品に対するネガティブなレビュー:"
}
}
}

定性分析:各ラベルに対して正しい文が生成されています。
JCoLA
task_conf = {
"task_name": "jcola",
"content": "あなたは日本語の教師です。\\n概要:\\n- 日本語の例文を用いて授業をしています。\\n- 例文は50字以内で生成してください。",
"labels": {
"0": {
"instruction": "授業に使用するために統語上誤った日本語文を1文生成してください。"
},
"1": {
"instruction": "授業に使用するために統語上正しい日本語文を1文生成してください。"
}
}
}

定性分析:文法的に誤ったテキストを生成できてはいますが、JCoLAに出現するような誤り方(助詞、時制、敬語などの誤り)はしていませんでした。
News
task_conf = {
"task_name": "news",
"content": "あなたはlivedoor Newsのライターです。\\n概要:\\n- 「」で指定するトピックのニュース記事を日本語で書いてください。\\n- 約200字で生成してください。\\n- 指定したトピック名は生成文に含めないでください。",
"labels": {
"0": {
"instruction": "「話題になった出来事」に関するニュースの要約文を書いてください。"
},
"1": {
"instruction": "「Sports Watch」に関するニュースの要約文を書いてください。"
},
"2": {
"instruction": "「ITライフハック」に関するニュースの要約文を書いてください。"
},
"3": {
"instruction": "「家電チャンネル」に関するニュースの要約文を書いてください。"
},
"4": {
"instruction": "「MOVIE ENTER」に関するニュースの要約文を書いてください。"
},
"5": {
"instruction": "「独女通信」に関するニュースの要約文を書いてください。"
},
"6": {
"instruction": "「エスマックス」に関するニュースの要約文を書いてください。"
},
"7": {
"instruction": "「livedoor HOMME」に関するニュースの要約文を書いてください。"
},
"8": {
"instruction": "「Peachy」に関するニュースの要約文を書いてください。"
}
}
}


定性分析:トピック名だけでは判断できない記事に関しては、内容とトピックが一致しないものが多く観測されました。例えば、「Peachy」は女性向けニュースで恋愛や便利アイテムなどのニュースであるにもかかわらず、生成されたテキストは架空の名前「Peachy」が名づけられた食品や施設などに関するニュースや航空会社Peach Aviationに関するニュースでした。また、「エスマックス」はソフトウェアや通信に関するニュースですが、実際に生成されたのは「エスマックス」と名付けられた架空の人物や会社に関するニュースでした。これらのトピック名と内容の不一致はPromptの与え方で性能改善が見込めます。
COVID-19
task_conf = {
"task_name": "covid-19",
"content": "あなたはCOVID-19に関するツイートをしています。\\n概要:\\n- 100字以内で生成してください。",
"labels": {
"0": {
"instruction": "ニュースなどの一般的に公表されている情報のみを含むツイートをしてください。"
},
"1": {
"instruction": "あなたの周りで生じている個人的な情報を含むツイートをしてください。"
},
"2": {
"instruction": "意見や感想を含むツイートをしてください。"
},
"3": {
"instruction": "COVID-19とは関係のないツイートをしてください。"
}
}
}

定性分析:各ラベルに対して正しい文が生成されています。
2文入力タスク
1文入力タスクのPromptに用いるConfigは以下。
# 2文入力タスクのPrompt用Configuration
task_conf = {
"task_name": {タスク名},
"content": {タスクの説明文},
"first instruction": {1文目を生成するための文},
"labels": {
"0": {
"instruction": {1文目に対してラベル 0 の関係にある文を生成するための文}
},
"1": {
"instruction": {1文目に対してラベル 1 の関係にある文を生成するための文}
}
}
}
上のConfigを用いて、OpenAIのGPT-3.5の1文目および2文目のPromptを以下のように作成しました。このPromptはopenai.ChatCompletion.create()の引数messagesに入力します。
label = "0"
prompt_1 = [
{"role": "system", "content": task_conf['content']},
{"role": "user", "content": task_conf['first instruction']}
]
response1 = openai.ChatCompletion.create(...)
generated_text1 = response1['choices'][0]['message']['content']
prompt_2 = [
{"role": "system", "content": task_conf['content']},
{"role": "user", "content": task_conf['first instruction']},
{"role": "assistant", "content": generated_text1},
{"role": "user", "content": f"{task_conf['labels'][label]['instruction']}"},
]
各タスクのConfigは以下に記載します。
JSTS
task_conf = {
"task_name": "jsts",
"content": "あなたは画像の説明文を記述しています。\\n概要:\\n- 記述はそれぞれ50字以内で行ってください。\\n- 記述は1文で行ってください。",
"first instruction": "見ている画像の説明文:",
"labels": {
"0": {
"instruction": "その文と全く関係のない文:"
},
"1": {
"instruction": "その文に出現する単語は含まれるが、関係のない文:"
},
"2": {
"instruction": "その文と少し関係のある文:"
},
"3": {
"instruction": "その文と関係のある文:"
},
"4": {
"instruction": "その文と類似する文:"
},
"5": {
"instruction": "その文と全く内容が同じ文:"
}
}
}

定性分析:生成された2文が類似度と一致しないサンプルが散見されます。例えば、上記の類似度1の2文は(おそらく)類似度4以上です。また、上記の類似度4の2文は(おそらく)類似度2です。やはり、類似度を指定するPromptの設計は困難でした。
JNLI
task_conf = {
"task_name": "jnli",
"content": "あなたは画像の説明文を記述しています。\\n概要:\\n- 記述はそれぞれ50字以内で行ってください。\\n- 記述は1文で行ってください。",
"first instruction": "見ている画像の説明文:",
"labels": {
"0": {
"instruction": "その文に対して含意関係にある説明文:"
},
"1": {
"instruction": "その文に対して矛盾関係にある説明文:"
},
"2": {
"instruction": "その文に対して中立関係にある説明文:"
}
}
}

定性分析:含意関係にある2文は怪しそうですが、各ラベルに対してそれなりに正しい文が生成されていそうです。
4.2. 下流タスク性能
表1に各手法のタスク性能および全タスク性能平均を示します。各値は5シード値の平均(分散)を表しています。

4.2.1. Zero-Shotでの比較
JapaGenはPromptingの性能をJSTS、JNLIおよびNewsの3タスクで上回り、MARC-ja、JCoLAおよびCOVID-19の3タスクで下回るという結果になりました。前者3タスクの入力テキストはフォーマルである一方、後者3タスクのうちMARC-jaとCOVID-19はインフォーマルであるという特徴があります。(※ここで言うフォーマルとは、テキストスタイルにおける意味であり、主語や目的語などの省略がないようなテキストを表します。)また、JCoLAはタスクの性質上、文法的に誤ったテキストを生成する必要がありましたが、そのようなPrompt設計は困難という問題がありました。以上から、Zero-Shot設定においてJapaGenはフォーマルなテキストを入力とするタスクで有効であることが示唆されます。
JapaGenで用いたBERTモデルは約110Mであるにもかかわらず、全タスク平均において、JapaGenはPromptingと比較してわずか3.43しか下回りません。したがって、モデルサイズと性能のトレードオフを考慮すると、JapaGenは効果的であると言えます。
4.2.2. Few-Shotとの比較
JapaGenはFew-Shot FineTuningと比較して、全タスク平均で 22.18 ポイントも上回り、各タスクでは COVID-19 以外の 5 タスクで上回る結果となりました。この結果は、同じモデルサイズである場合、JapaGen(Zero-Shot)はFew-Shotの性能を大きく上回ることを意味します。
Few-Shot Promptingとの比較では、JapaGenはJNLIおよびNewsの2タスクで性能を上回りました。この2タスクはZero-Shot Promptingでの結果と一致します。ここで、JSTSで性能が下回ったのは、類似度のみから疑似データを生成するのは困難であるためだと考えられます。具体的には、疑似データ生成時に付与するクラスは {0.,1.,2.,3.,4.,5.} の 5 個としましたが、実際には 2 文の類似度は 0. ∼ 5. の実数値であり、小数点以下の類似性を正確に表現できません。
以上から、JapaGen(Zero-Shot)はフォーマルなテキストの分類タスクにおいて効果的であると言えます。そのようなタスクでは、モデルサイズが大きく、Goldデータ数も多いFew-Shot Promptingをも上回りました。
4.2.3. Fully Supervisedとの比較
JapaGenで生成した疑似データはGoldデータと同程度かそれ以上のデータサイズなのにもかかわらず、JapaGenは全6タスクでFullly Supervisedの性能を大きく下回りました。これは LLM により生成した疑似データの分布はGoldの分布と大きく異なることを示唆します。次節でGoldと疑似データの分布について分析します。
4.3. 分析
4.3.1. 出現トークン数分布
Goldおよび疑似テキストの出現トークンとその出現数のヒストグラム分布を下図に示します。また、両ヒストグラムの重複度を表す重み付きJaccard係数も算出しました。

全タスクに共通して疑似データにのみ出現するトークンが多く存在することが分かります。Newsは他タスクと比較してJaccard係数が小さいのにもかかわらず、JapaGenがFew-Shotの性能を上回ることから、Goldと疑似データの分布の一致は下流タスク性能の十分条件にすぎないと言えます。また、KADGによってJaccard係数は増加したことから、KADGは疑似データをGold分布に近づけるのに有効と言えます。
4.3.2. 多様性分析とラベル正確性
LLMにより生成した疑似データの質は下流タスク性能に影響します。そこで、疑似データが同じようなデータを多く生成してないかを測る多様性、ラベルと疑似データの内容が合っているかを測るラベル正確性の2点を分析します。
データセットの多様性をSelf-BLEUにより算出しました。値が小さいほど多様であることを示します。ラベル正確性はGoldデータで学習したモデルで各種データを評価したタスク性能で計測しました。その結果を下表に示します。

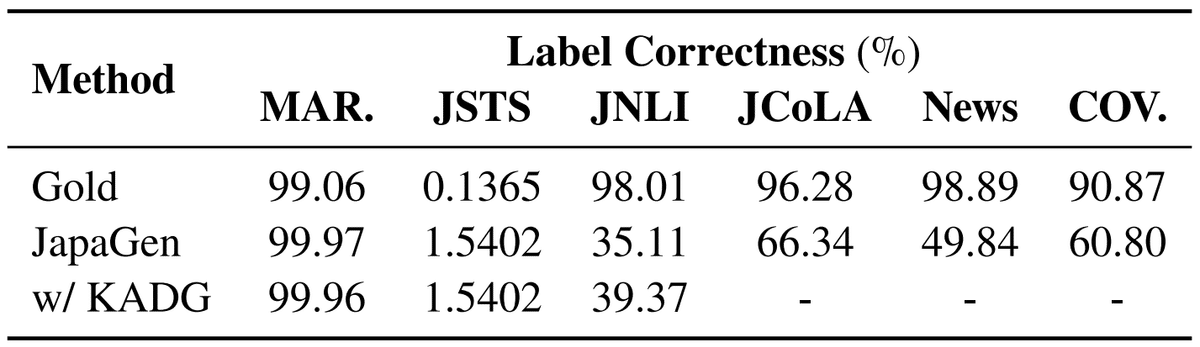
MARC-jaとCOVID-19の2タスクで、JapaGenの多様性は約1/2も低いことが分かります。一方、JSTS、JNLI、JCoLAおよびNewsでは、疑似データはGoldデータに近い多様性を保持しています。
次に、JapaGenとKADGを比較すると、MARC-jaのみKADGの多様性がJapaGenを上回ります。表1と合わせると、KADGによる多様化がMARC-jaの性能向上に寄与していると考えられます。「多様性を上げるとラベル正確性が低下し、下流タスク性能を悪化させてしまう」という先行研究がありますが、表3よりKADGは作成した疑似データのラベル正確性を低下することなく多様性を向上させることができました。以上から、KADGによって多様性を増加する場合と多様性を制限してしまう場合がありますが、ラベル正確性は維持できるため、KADGはその前者の場合に有効であると言えます。
また、5.1の定性分析でも述べたように、定性的にはJSTS、JCoLA、Newsのラベル正確性が低い結果となりました。
4.3.3. データ数のスケーリング
疑似データ数による下流タスク性能の推移を図6に示します。データ数は{100, 500, 1000, 5000}としました。
データ数に対して多くの下流タスク性能は増加傾向にあることが分かります。

5. おわりに
インターンで取り組んだ「日本語タスクにおいてLLMにより生成したデータで小規模モデルを学習するJapaGenの検証」をご報告しました。検証の結果、フォーマルなテキストを入力とする分類タスクにおいて、Zero-ShotおよびFew-Shot Promptingを上回りました。また、タスク知識をPromptに導入するKADGを提案し、疑似データがGoldデータの分布に近づき、MARC-jaで多様性と性能が向上しました。
インターンではメンターの勝又さんの多大なサポートにより、修士論文や学会発表などの学生活動がありながらも、ここまでやり遂げることができました。本当にありがとうございました!また、研究チームの西鳥羽さん、木村さん、飯田さんにもアドバイスや原稿やポスターの添削などをしていただき、ありがとうございました!
NLP2024でもポスター発表を行うので、是非聞きに来てください!!
参考