

#生成AI


Microsoftの3D生成AIモデル「TRELLIS」を試してみる
TRELLISとは3Dモデリングの分野で注目を集めているMicrosoftの最新AIモデル技術「TRELLIS」。この技術の核となるのが「Structured LATent(SLAT)」という表現手法で、Radiance Fieldsや3D Gaussians、メッシュといったさまざまな形式の3Dデータをサポートするものとのこと。
(このSLATはオブジェクト表面に交差するボクセルに局所的な潜在変






3Dモデルが作れる生成AIサービスの紹介と実際に使ってみて比較した結果
3D描画の品質はハードウェアの性能に依存します。
私はファミコン世代なので、スーパーファミコンの F-ZERO や Star Fox に始まり、中学生時代はゲームセンターに入り浸りバーチャファイターや鉄拳をプレイし、初代プレイステーションのポリゴンゲームに感動してきました。
今はポリゴンという言葉すら死語に感じ、信じられないほど簡単に3Dモデルを作れる時代です。私はクリエイターではないのでこの

画像を3Dに変換するAIツール「Stable Fast 3D」を試してみる
Stable Fast 3DとはStable Fast 3D…一瞬で画像を3D化するということでちょっと話題になってたので調べてみましたが、1 枚の画像から高速かつ高品質のテクスチャ付きオブジェクト メッシュを再構築する新しい手法で、内容としてはStability AIでTripoSR をベースにしているものとのこと。
作者はMark Bossさん。偉大な発明をありがとう!
速さと質が売りのような

UbuntuでMusePoseを試してみる
「仮想人間生成のためのポーズ駆動型イメージ-to-ビデオ フレームワーク」であるらしいMusePoseを試してみます。
1. 準備環境構築
python3 -m venv museposecd $_source bin/activate
リポジトリをクローンして、パッケージをインストールします。
# clonegit clone https://github.com/TMElyralab/
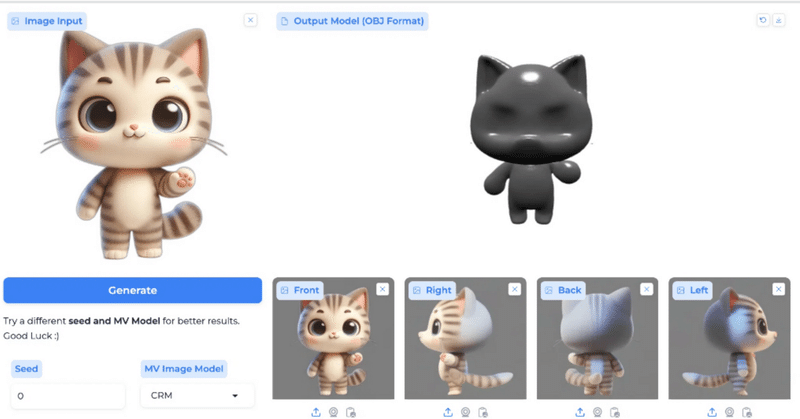
新しく見つけた2D-to-3Dの「CraftsMan」を試してみる
ということで今回はまた新しく見つけた2D-to3DのCraftsManを触ってみたいと思います!
CraftsManの最大の特徴は、二段階プロセスで行う高速かつ高精度な3Dメッシュ生成で、多様なMVモデルが選べるところらしいです。
CraftsManとはざっくりですがこのCraftsManのことをまとめて言うと、二段階のテキスト/画像から3Dメッシュを生成するモデルのことです。
特徴と呼ばれる


MotionGPT で作ったモーションを任意の 3D モデルに割り当てて動かす
MotionGPT でモーションを生成し、Blender 上で 3D モデルに適用して動かしてみた。
モーション生成概要
テキストからモーションを生成する技術。
行動を表すテキストを再現するようなモーションが得られる。
様々な手法
Motion Diffusion Model や text-to-motion 等様々な手法があり、Awesome-Video-Diffusion リポジトリに


【SV3D】たった1枚の写真から3Dモデルを作る最新技術 - Stable Video 3Dのしくみ
👋皆さん、こんにちは!今回はStability AIから発表された最新のAI技術「Stable Video 3D (以下、SV3D)」をご紹介します✨️
SV3Dは、たった1枚の画像から高品質な3Dモデル動画を作成できる画期的なツールです!
これまでも、生成AIを利用して画像から3Dモデルを作成するツールはリリースされていましたが、テキストから3Dモデルを生成する場合と比べて、画像からの3D生


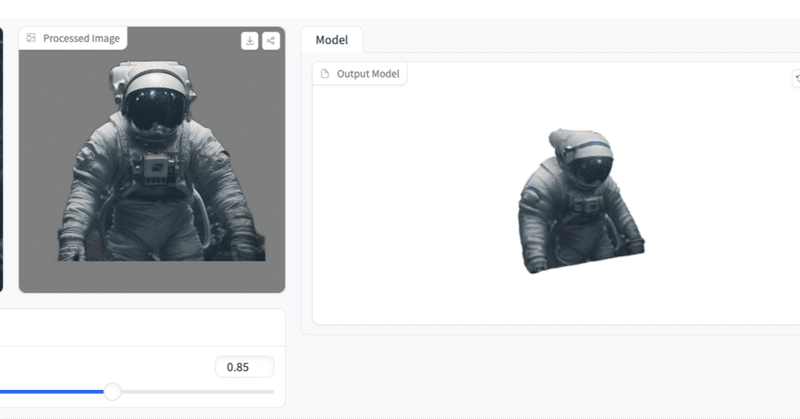
写真から3Dモデルを作っちゃうTripoが結構面白い。あと地球外少年少女とVisionPro
TripoSRというのが出た。誰でも無料で試せる。
写真を突っ込むと問答無用で3Dにしてくれる。しかも空いてれば数秒で。
ローカルでも動かせる。12GBくらいのVRAMがあれば。
BitNetによってVRAMは激減するのかと思いきや、どんどんVRAMが必要になっていく。最近発売されたH100は96GBくらい乗ってる。だとすると8基積めば768GBのシステムが組める。まあこのインフレはしばらく続

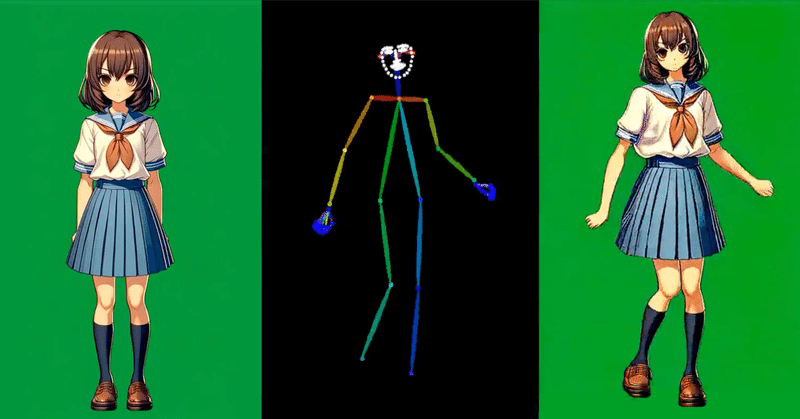
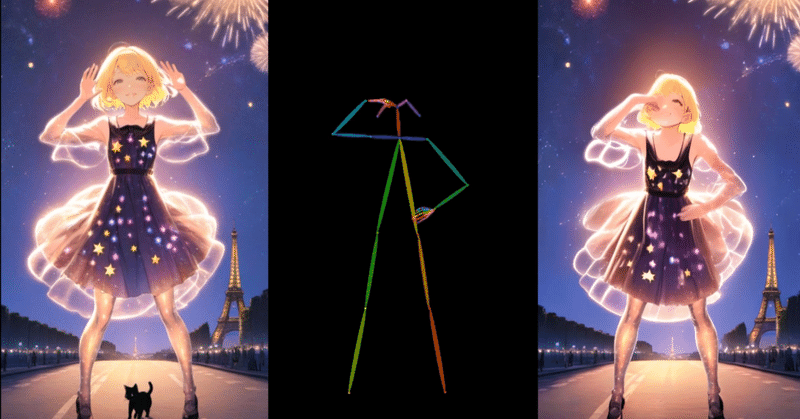
Google Colab で Moore-AnimateAnyone を試す
「Google Colab」で「Moore-AnimateAnyone」を試したので、まとめました。
1. Moore-AnimateAnyone「Moore-AnimateAnyone」は、「AnimateAnyone」の再現実装です。元の論文で実証された結果を一致させるために、さまざまなアプローチやトリックを採用していますが、それらは論文や別の実装とは多少異なる場合があります。
これは非常
