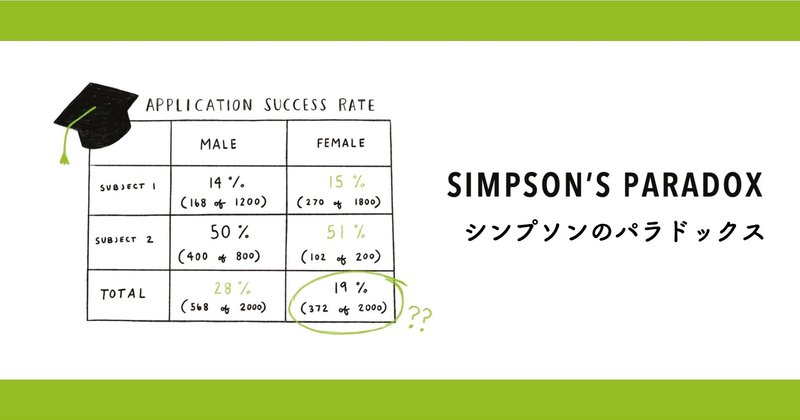
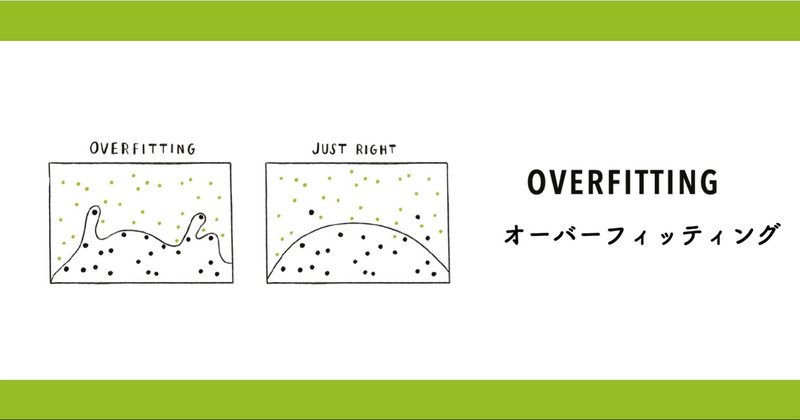
データの誤謬#1『チェリーピッキング』
いけませんよ!
おいしいところだけ、つまみ食い。
#1 チェリーピッキング自分の主張に合う結果だけを選択し、そうでない結果を除外すること。
データに不誠実であるという最悪で最も有害な例。
何かを主張するときには裏付けとなるデータが重要になります。
しかし、人々は、全体を説明する代わりに、自分の主張を裏付ける一部の都合の良いデータだけを強調することがよくあります。
これは、公の場での議論や、政治の場でよく見られる現象で、
どちらの側も自分の立場を裏付けるデータを強調するこ