

#ファインチューニング


Google ColabとUnslothを使ってLlama 3 (8B)をファインチューニングし、Ollamaにデプロイする方法
このチュートリアルでは、UnslothとGoogle Colabを使って無料でLlama-3をファインチューニングし、独自のチャットボットを作成する方法を段階的に説明します。作成したチャットボットは、Ollamaを使ってローカルコンピュータ上か、Google Colabの無料GPUインスタンス上で実行できます。
完全なガイド(画像付き)はこちら: https://docs.unsloth.ai/


Llama 3をReFTでファインチューニング
Pythonライブラリpyreftより少ないパラメータ数で、より優れた性能を達成する可能性のあるファインチューニング方式「ReFT」(Representation Fine-Tuning)。
少ないファインチューニングパラメータで、より強力なパフォーマンスを発揮し、ファインチューニングの効率を向上させ、コスト削減を実現します。
そのPythonのライブラリが「pyreft」です。
上記リポジト

10bクラスの大規模言語モデルが、ファインチューニングを経てタスクを解けるようになるメカニズムを探るメモ
追記・拡張版はこちら
はじめに最近は大規模言語モデルのファインチューニングにハマっています。
10bクラスの言語モデルが、どのようなメカニズムを通してユーザーの質問に回答できるようになるかについて、調べています。
最近の検討で生じた仮説は、「10bクラスのモデルは、実は質問文を殆ど理解できていない」というものです。
本記事ではどのようなデータを学習したときに、llm-jp-evalという評


LLaMA-Factoryの論文紹介
論文名
LLAMAFACTORY: Unified Efficient Fine-Tuning of 100+ Language Models
arXivリンク
https://arxiv.org/pdf/2403.13372.pdf
ひとこと要約
簡単かつ効率的にLLMのファインチューニングを行うためのフレームワークであるLLaMA-Factoryの紹介
メモ
LLaMA-Fact

層に着目したLLMの口調の学習について
こちらは【第3回】生成AIなんでもLT会の登壇内容のnoteです。
👇【第3回】生成AIなんでもLT会のリンクはこちら
👇登壇資料はこちら(PDF化した時にサイズ変更があり、少しバグっているようです。)
はじめにLLMのファインチューニングをしていると、ふと「学習した情報ってどこに保存されているんだろう?」と思うことはありませんか?
LLMの知識がどこに保存されているのかというお話は、
大規模言語モデルをフルスクラッチする練習 (環境構築ー前処理ー事前学習ーファインチューニングー評価まで)
はじめに以下のオープンなプロジェクトの一環で、大規模言語モデルをフルスクラッチで作る練習をします。24年3月現在、協力者も募集中です。
リポジトリ当該プロジェクトの標準コードが公開※されたので、それを走らせてみます。
※24/3/5時点で、まだレポジトリ内に、工事中の箇所が多々、あります。
このリポ上では、事前学習ー事後学習ー評価まで、一気通貫(?)したパイプラインが提供されています※。
※


つくよみちゃんの会話データセットを使ってFine-Tuningしてみる【練習用】
布留川 英一さまの書籍『OpenAI GPT-4/ChatGPT/LangChain 人工知能プログラミング実践入門』を教本としてOpenAI APIを触っている吉永(@yoshinaga2015)です。
つくよみちゃんの会話データセットを使ってFine-Tuning(ファインチューニング)する手順をまとめました。
OpenAI APIの環境設定Google Colabで新規ノートブックを作成

RWKVを公開データ+社内データでファインチューニングしてみた
ファインディ株式会社で機械学習エンジニアをしています、笹野です。
ChatGPT発表以降LLMに注目が集まり、手元のマシンでも動くようなLLMも数多く登場し、これらに関する記事も散見されるようになってきています。
情報を仕入れる目的で様々な記事や文献に目を通しますが、オープンデータでのファインチューニング記事は多数公開されています。一方で、元々社内・組織内に蓄積されたデータを使ってファインチュー

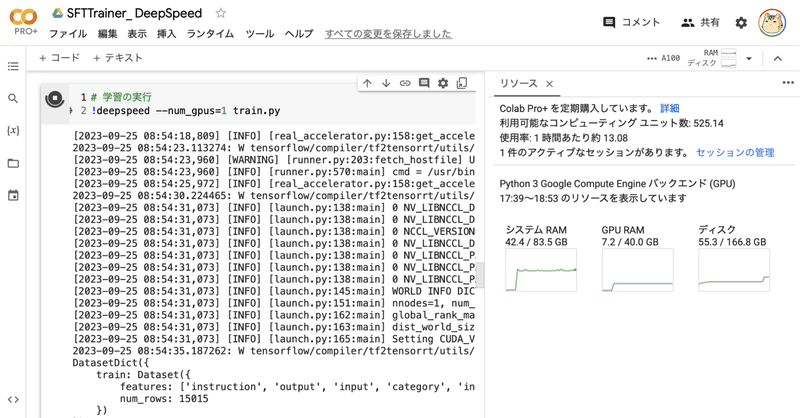
Google Colab で DeepSpeed によるLLMのフルパラメータの指示チューニングを試す
「Google Colab」で「DeepSpeed」によるLLMの (LoRAではなく) フルパラメータの指示チューニング (Instruction Tuning) を試したので、まとめました。
前回
1. DeepSpeed「DeepSpeed」は、深層学習モデルの学習や推論の処理を高速かつメモリ消費を抑えて実現することができるライブラリです。
HuggingFaceでサポートしている「De
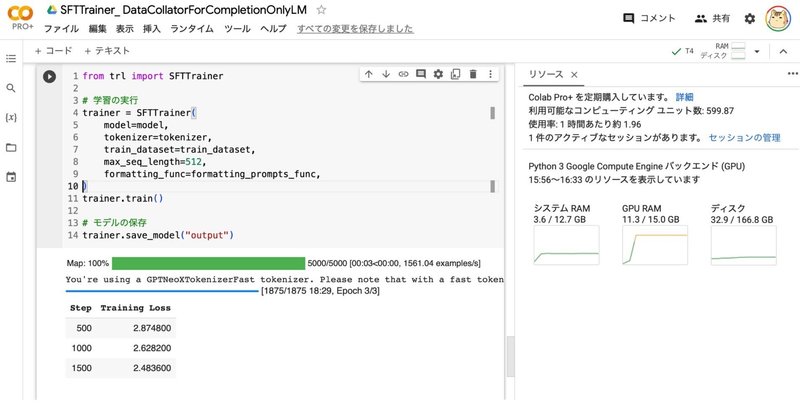
Google Colab で SFTTrainer によるLLMのフルパラメータの指示チューニングを試す
「Google Colab」で「SFTTrainer」によるLLMの (LoRAではなく) フルパラメータの指示チューニング (Instruction Tuning) を試したので、まとめました。
前回
1. モデルとデータセット今回は、LLMとして「OpenCALM-small」、データセットとして「databricks-dolly-15k-ja」を使いました。
2. ファインチューニング前

Google Colab で SFTTrainer によるLLMのフルパラメータのファインチューニングを試す
「Google Colab」で「SFTTrainer」によるLLMの (LoRAではなく) フルパラメータのファインチューニングを試したので、まとめました。
1. SFTTrainer「SFTTrainer」は、LLMを「教師ありファインチューニング」 (SFT : Supervised Fine Tuning) で学習するためのトレーナーです。LLMの学習フレームワーク「trl」で提供されてい

OpenAI の WebUI で つくよみちゃんの会話テキストデータセット の ファインチューニングを試す
OpenAI の WebUI で「つくよみちゃんの会話テキストデータセット」のファインチューニングを試したので、まとめました。
1. つくよみちゃん会話AI育成計画(会話テキストデータセット配布)今回は、「つくよみちゃん」の「会話テキストデータセット」を使わせてもらいました。「話しかけ」と、つくよみちゃんらしい「お返事」のペアのデータが400個ほど含まれています。
以下のサイトで、利用規約を確


text-generation-webuiで、ELYZA-japanese-Llama-2-7n-fast-instructをExLlamaでロードし、LoRA適用してみる
text-generation-webuiで、ELYZA-japanese-Llama-2-7n-fast-instructをExLlamaでロードし、LoRA適用してみます。
Exllamaでモデルをロードするために、以下のGPTQモデルをお借りします。
Download model or LoRA画面にdahara1/ELYZA-japanese-Llama-2-7b-fast-instr

text-generation-webuiで、ELYZA-japanese-Llama-2-7n-fast-instructのLoRAトレーニングを試す。
text-generation-webuiで、ELYZA-japanese-Llama-2-7n-fast-instructのLoRAトレーニングを試してみたので、その備忘録を記します。
Google Colabでtext-generation-webuiを起動ローカルマシンではVRAMが足りなかったので、Google ColabでA100を利用します。
以下のコードを実行すると、Google