10bクラスの大規模言語モデルが、ファインチューニングを経てタスクを解けるようになるメカニズムを探るメモ

追記・拡張版はこちら
はじめに
最近は大規模言語モデルのファインチューニングにハマっています。
10bクラスの言語モデルが、どのようなメカニズムを通してユーザーの質問に回答できるようになるかについて、調べています。
最近の検討で生じた仮説は、「10bクラスのモデルは、実は質問文を殆ど理解できていない」というものです。
本記事ではどのようなデータを学習したときに、llm-jp-evalという評価セットに含まれるJCommonsenseQAというタスクを解けるようになるか、果たして、10bクラスのモデルは何を「理解」している/いないのか、そして、指示を理解できるようになるための必要な訓練量について、調べて行きたいと思います。
コードはこちら
※ これは正確な学術的検証ではありませんので、ご了承ください。きちっとやってくれる方や、良い参考文献をご存知の方がいたら、教えていただけると、大変助かります。
今回のタスク
JCommonsenseQA
与えられた選択肢から、整数を選んで答えるクイズを、本記事のタスクに設定しました*。
*理由は、本調査で用いることにしたdollyデータセットが、Q&A形式で単語や文章の出力を行うinstruction形式だからです。jcommonsenseqaも同様にQ&A形式のクイズですが、出力形式が単語や文章ではなく、選択肢である点が微妙に異なります。このような微妙な指示の違いに対する、モデルの理解力や汎化性能を検証することが本記事の目的です。
このデータセットに含まれる例題は以下の通りです。
問題
質問と回答の選択肢を入力として受け取り、選択肢から回答を選択してください。なお、回答は選択肢の番号(例:0)でするものとします。 回答となる数値をint型で返し、他には何も含めないことを厳守してください。
質問:電子機器で使用される最も主要な電子回路基板の事をなんと言う?\n選択肢:0.掲示板,1.パソコン,2.マザーボード,3.ハードディスク,4.まな板
回答
2
このタスクを解くのに必要な能力はなにか?
この問題を解くためには、大きく3つの能力が必要です。
1. 質問に対して回答を行う能力
これは当たり前に見えますが、単に事前学習を終えただけのモデルは、意味不明な回答をしてしまう場合があります。
だめな例
Q: 明日の天気はなんですか?
A: 明後日の天気はなんですか?しあさっての天気はなんですか?…
これが出来ていないと、本ベンチマークに対するスコアはほぼゼロになります。
2. 数値を回答する能力
今回のタスクは、数値を整数として回答することが求められています。
例えば、正解の単語を回答しても、不正解となります。
本タスクは5択問題なので、仮に数値を出力できたとしても、それが意味ない値であったとしたら、スコアは1/5=0.2程度となります
3. 適切な数値を選んで回答する能力
正しい選択肢を選んで数値で回答する能力があれば、スコアは0.2よりも十分に大きくなるはずです。
検証1: 学習した指示データセットの依存性を調べる
一連の検証では、前回の記事と同様、llm-jp-13bの事前学習済みモデルをファインチューニングしたものを用いました。
dolly-ja, ichikara, oasst-jaのような、代表的な日本語データセットを学習させた際のjcommonsenseに対するスコアは以下のとおりでした(モデルの詳細については、こちらを参照ください)。

実験結果
ベースモデル, ichikara*を学習したモデルは、数値を回答する能力を実質的に持たない(黒字, score≒0)
Dolly, oasst,を学習したモデルは、ランダムな数値しか出力できていない可能性が高い(青字, score <0.2程度)
jcommonsenseのtrain setを含むjasterを学習させた場合は、適切な数値を回答できる能力を獲得した(赤字, score > 0.9)
*ichikaraは、上質な日本語データセットとして知られています。今回のタスクで性能が低かったのは、a)クイズを想定したデータセットではないことと、b)実装の都合上、1.5k件しかデータを学習させなかったためであると考えられます。
考察
dolly, oasstは単語や文章を答えるタイプのタスクが大半で、モデルは選択式問題を未学習であった。
にもかかわらず、「数値を回答する能力」を身につけることができた。
一方で、「適切な数値を選ぶ能力」は身に着けられなかった(score ≒0.2)。
検証2: モデルは何を学習すると、「数値を回答する能力」を身につけるのか?
以下、dollyに的を絞って、もう少し丁寧に解析を行っていきます。
dollyを学習させることで、曲がりなりにも、モデルは「数値を回答する能力」を身につけることが出来ました。
「数値を回答する能力」を身に着けさせるための指示データは存在するのか?
モデルが数値の回答能力を獲得するための条件について、以下の対照実験を行うことで、調べました。
条件A(dolly-1k): dollyを1k件*、学習したモデル
条件B(dolly-1k-wo/num): 条件Aから、数値で始まる短い回答を含むQ&Aを除いたモデル
*計算時間の都合で、1kとしました。
条件Bでは、具体的には以下の7件データを抜きました。
・ルイス・ハミルトンは何回F1チャンピオンになったか? 7回
・ビンゴゲームで、「2羽の小鴨」というフレーズで表される数字はどれでしょう? 22
・イタリアンファーストが発売されたテキスト年号より抜粋 2013 総座席数は何席ですか? 150席
・この「Large language models」の項を踏まえて、OpenAIのGPTシリーズの最初のモデルは、いつトレーニングされたのでしょうか。 2018.
・The Australian Chess Championshipは何回開催されるのですか? 2年ごと
・このビデオゲームに関する参考文章から、ドンキーコングはいつ発売されたのか? 1981
・スタン・ローレル、ミッキー・ルーニー、ラナ・ターナー 共通点 8回目の結婚
条件A,Bともに、dolly中に、選択式問題は含まれていないことを、(軽くですが)確認しました。
結果
学習率1e-5*、3 epoch、フルパラメーターの条件で、ファインチューニングを行いました。モデルは、JGLUE**セットで性能を評価しました。
*こちらの検討で軽く最適化した値です。
** jcommonsenseなどを含む評価セットです。
評価結果を以下に示します。

わかること
dolly datasetは、1k程度の学習でも、それなりのファインチューニング効果がある。
根拠: jsquadの回答能力が向上した
jsquadは、わりとdollyと似たタスクが含まれる評価セットで、質問のクイズに対して、単語で回答を答えることが求められます
前回までに検討した、dollyを10k件、学習した条件の結果(jsquad = 0.47)とも同等の値であった
ただし、jglueの全体指標(avg)を見た場合は、10k学習させたほうが良かった(0.1→0.2程度の改善)
commonsenseの回答能力は、数値データを抜いた条件で、わずかに低下した。
dolly-1kの具体的な出力内容は、以下のとおりです(dolly-1k-wo/numもほぼ同等の結果でした。)。

ほぼすべてのケースで、モデルの出力は、「選択肢番号ではなく単語を答えてしまっている」、または「0」のどちらかでした。
数値データを抜いて学習させたdolly-1k-wo/numのスコア(0.16)は、通常のdolly-1k (0.2)よりも、わずかに低下しました。
その理由は、モデルが数値を出力できた割合から考察することが出来ます。
数値が回答となるデータを学習したケース(dolly-1k)
100件中、73件
数値が回答となるデータを学習しなかったケース(dolly-1k-w/o)
100件中、68件
この差を有意差とすべきかは、議論の余地がありますが、数値が回答となるデータ(7件)でモデルを訓練することで、数値での回答能力が向上した、と解釈することもできそうです。
モデルは指示を理解しているのか?
個人的に、やや意外だったのは、数値での回答訓練を行わなかったモデル(dolly-1k-w/o)が、曲がりなりにも、数値(=0)を出力できたという点です。
理由をさらに探るため、ファインチューニング前のモデルの出力を確認してみました。
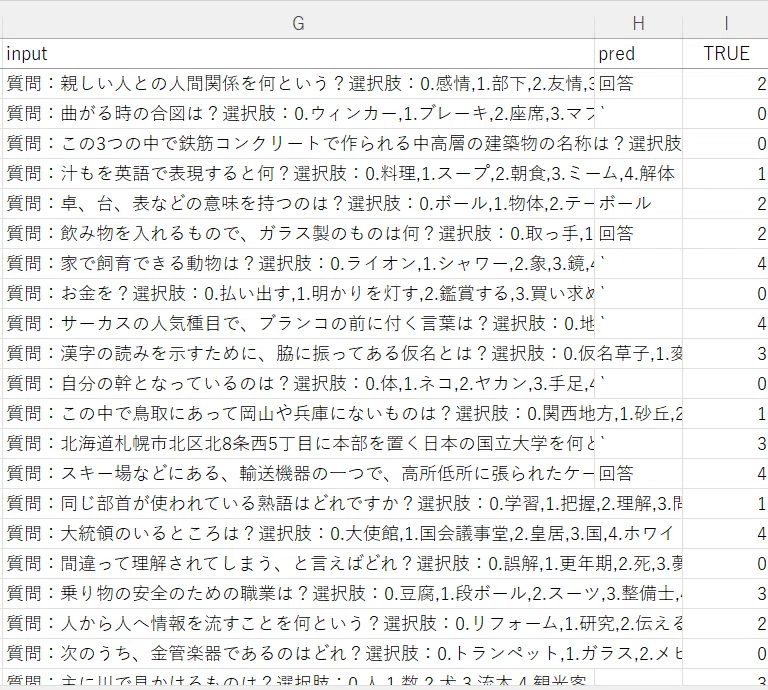
ファインチューニング前のモデルは、質問に対して、「回答」、「`」のような記号や、空白を返すケースが大半でした。つまり、ファインチューニング前のモデルは、「1.質問に対して回答を行う能力」を有さないということがわかります。 dollyによる学習過程で、単語や文章を生成する訓練を積むうちに、同時に、「数値を出力する」という能力を獲得できたと言えそうです。
以上の結果をまとめると、、
ファインチューニング前のモデルは、「1.質問に対して回答を行う能力」を有さない
数値の解答を含まないデータで訓練を行ったモデル(dolly-1k-w/o)であっても、「2.数値での回答能力」を獲得できる
「数値で回答しなさい」という問題文の意図を、モデルはかろうじて理解している可能性がある。
未学習タスクに対するzero shot predictionが一応は可能であった。
ただし、出力は「3.正しい選択肢を選ぶ能力」は獲得できなかった
「正しい選択肢を選べ」という問題文を、モデルは十分に理解できなかった可能性が高い
こちらの未学習タスクに対するzero shot predictionはできなかった。
「正しい選択肢を選ぶ能力」はどうやったら身につくのか?
dollyのみを学習したモデルは、「数値を出力する能力」は持っているものの、「正しい選択肢を選ぶ能力」はないことがわかりました。
そこでこの項では、jcommonsenseの訓練データを学習に加えながら、回答性能を評価しました。
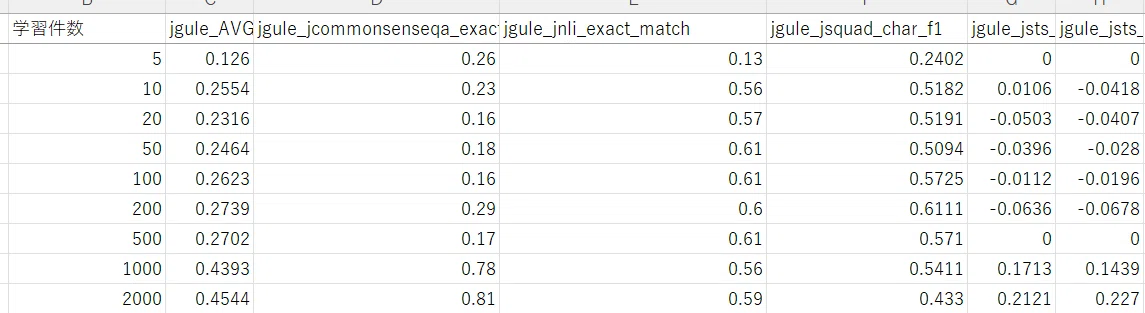
jcommonsenseの学習データ数 vs モデルの性能
事前学習済みのモデルに、jcommonsenseの訓練データ、N件を学習させました。
N=5-500程度では予測性能が上がらず、1000になると、突然、スコアが上がりました。
脱線話題: どうしてjcommonsenseを学習させるだけで、jnliの予測性能が上がったのか?
jcommonsenseのみを学習させたにもかかわらず、他のタスクであるjnliのスコアが急上昇した点に、非常に驚きました。一瞬、「もしやこれは汎化性能!?」と、一瞬、テンションが上がったんですが、実際の予測結果は、どちらかというと、微妙なものでした(下記)。

どうやら、モデルはjcommonsenseを学ぶことによって、jnli問題に対して、「neutral」という文字列を出力する能力を獲得したのみのようです。
(数値での回答を含まない)dollyデータセットを学習させることで、曲がりなりにも数値を出力できるようになったように、0-4の選択肢問題を解くことで、曲がりなりにも、「neutral, entailment, contradiction」から、neutralを選べるようになった、というのが実情のようです。
(このデータセットでは、とりあえずneutralと出力するだけで、0.6程度のスコアを獲得できる模様です)
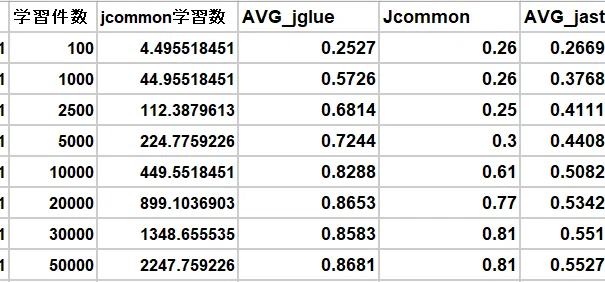
jaster dataset全体を学習させた結果
一緒に色々なデータを学習させた方が、予測性能が上がるという仮説も存在します。そこで、jaster dataset全体を学習させながら、スコアの推移を確認しました。
jcommonsenseの学習件数をx軸、同セットのスコアをy軸に取ったグラフは以下のとおりです。
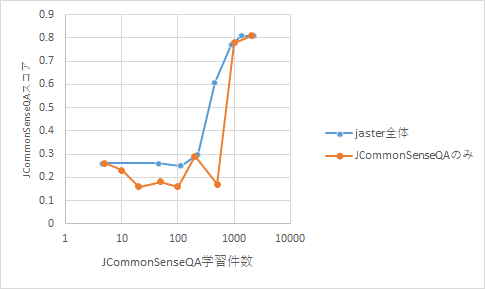
わかってきたこと
単一のデータセットのみでなく、復数のタスクを混ぜた方が、スコアが安定する可能性がある
特定のタスクに対するoverfitを防ぐ感じでしょうか。
ただし、相乗効果というのは限定的である印象を受けます。
今回の選択式問題(jcommonsense)を解けるようになるためには、少なくとも数百件以上の類似データで、事前訓練を行う必要がある。
どうやら、選択肢から正しい答えを選ぶ、というタスクは、このLLMにとって、かなり難しい作業のようです。
多くの人間にとっては、回答を「単語で答える」ことと、「選択肢で答える」ことは類似のタスクであり、難易度の差は小さいと感じます。
しかし上述の通り、このLLMにとっては非常に難題であることが、一連の検討によって明らかになりました。
まとめ
今回の検討事例からも推察されるように、「10bクラスのLLMの理解力や汎化性能は、あまり高くない」ということが、浮き彫りになってきました*。
10b程度のモデルを用いて、未学習のタスクに対して、zero-shotで推論を行うというのは、夢のまた夢ではないかというのが、個人的な感想です。
とはいえ、10bモデルにもできることは沢山あると考えています。やはり、タスクを事前に明確化した上での、徹底した訓練に基づく、特化型モデルの構築が、現実的なアプリケーションではないかと感じる次第です。
*学問的な厳密性を問うならば、他のタスクやモデルについても、同様の検討を行うべきですが、筆者の専門は、一応、化学です。なので、このあたりは、人工知能が専門の方に、やっていただければ、色々な人の役に立つのではないかと考えています。
補足検証
モデルは指示文をどの程度、理解しているのか?
果たして、モデルは指示文を理解して数値を理解しているのか、それとも、問題形式を暗記しているだけなのか、という疑問が生じます。
そこで、このタスクでは、指示文章を省略した状態で、jcommonsenseデータセットをN件、モデルに学習させてみました。
オリジナル
以下は、タスクを説明する指示と、文脈のある入力の組み合わせです。要求を適切に満たす応答を書きなさい。\n\n### 指示:\n質問と回答の選択肢を入力として受け取り、選択肢から回答を選択してください。なお、回答は選択肢の番号(例:0)でするものとします。 回答となる数値をint型で返し、他には何も含めないことを厳守してください。指示:\n質問:生物の貯蔵などの変化を?\n:0.行列,1.祭り,2.エネルギー交代,3.交代勤務,4.参覲交代
省略後
指示:\n質問:生物の貯蔵などの変化を?\n:0.行列,1.祭り,2.エネルギー交代,3.交代勤務,4.参覲交代
結果
スコアに顕著な差は生じませんでした。モデルは、指示文の内容を、あまり真剣には考慮していないのかもしれません。
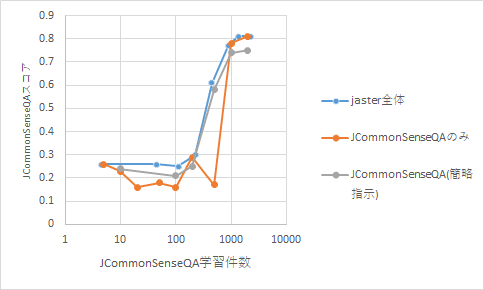
..と思っていたのですが、2000件のデータを学習した際は、他のモデルよりもやや予測性能が下がりました。加えて、他の評価指標が明らかに低下しました。「いい加減な指示?」ばかり与えていると、モデルの言語能力が下がるという可能性もあるのかもしれません(詳細は要検証)。
LIMA論文との整合性
かの有名なLIMA論文は、上質な1000件程度のデータセットがあれば、モデルのファインチューニングは十分であると主張しています。
モデルサイズが小さいときは、1kではなく2k以上がベターとの記載はありますが、4k以上では殆ど改善が見られません。

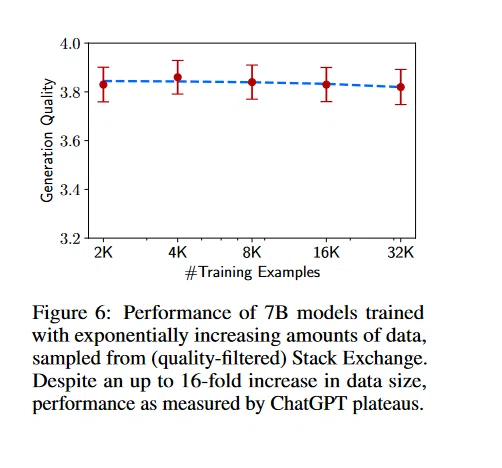
一連の主張は、筆者が本記事などで検討してきた実験結果と、一見、矛盾するように思われます。
例えば、上質な日本語データセットとして報告されている「ichikara」を1500件、学習させても、jasterでハイスコアを取れるという傾向は、微塵も観測されませんでした(記事上部を参照)。
この「矛盾」を説明しる因子として、ベンチマークの違いが挙げられるかもしれません。LIMAやichikaraは、どちらかといえば作文向けのデータセットであるように思います(LIMAの評価指標も作文系のようです)。同じく、対話能力が向上したと言われるllm-jp-13b-DPOでは、jaster系でichikaraレベルの低スコアを示しました。
現在、筆者が持っている仮説は、
答えが唯一ではなく、多様な応答が求められる「テキスト生成系のタスク」では、指示データセットへの過学習を防ぐため、少数で上質なデータが望ましい
のに対し、
答えが唯一で、厳密な回答が求められる「ルール系のタスク」では、徹底した訓練が必要かもしれない
というものです。
このような仮説が正しいとすると、特に小規模なモデルにおいては、対話用・ルール厳守の二種類以上のエキスパートモデルを構築した上で、適切に切り替える戦略が有効かもしれません。(今後、検証したいところです)
この記事が気に入ったらサポートをしてみませんか?