

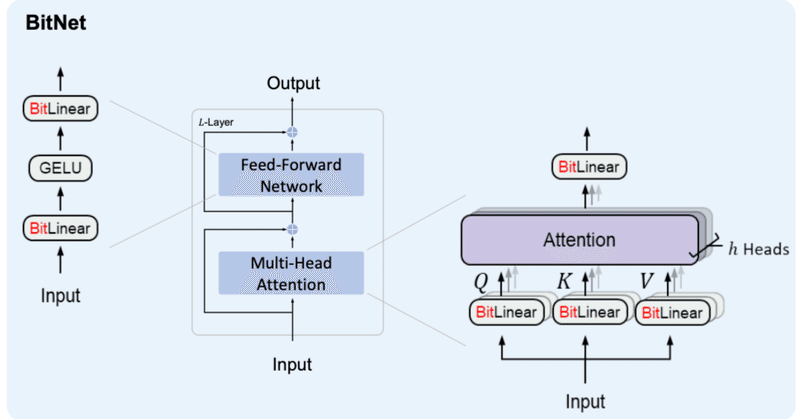
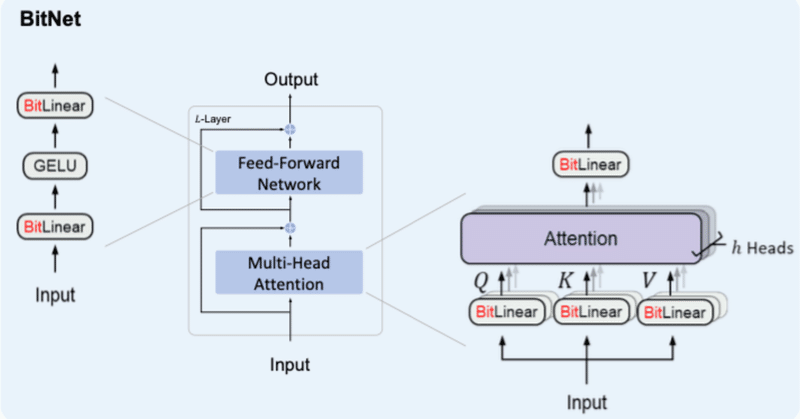
#Bitnet




bitnet.cpp を試す
tl;drMicrosoft が 1-bit LLM 推論フレームワーク bitnet.cpp を公開したよ
llama.cpp をベースにした CPU 推論対応フレームワーク
8B パラメータの 1.58-bit 量子化モデルをシングル CPU で実行可能だよ
macOS 環境におけるセットアップと実行手順を書いたよ(uv で実行確認)
英語での推論は良さそうだけど、日本語出力はちょっと





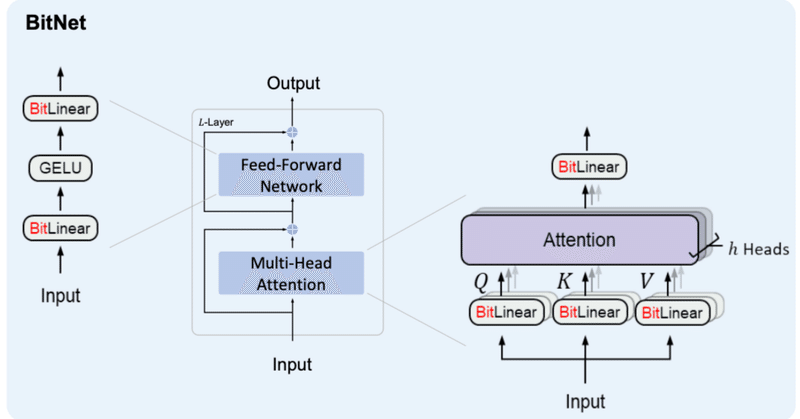
BitNet&BitNet b158の実装④
はじめに前回、BitLinear b158の実装を行いました。前回までの内容は以下をご参照ください。
4. BitNet b158の検証BitNetの検証と同様、
BitLlamaでBitLinear158bを利用できる様に修正
事前学習ができるか(Lossが下がるか)確認
を行います。
4-1. BitLlamaの修正
modeling_bit_llama.pyにおいて、BitLin
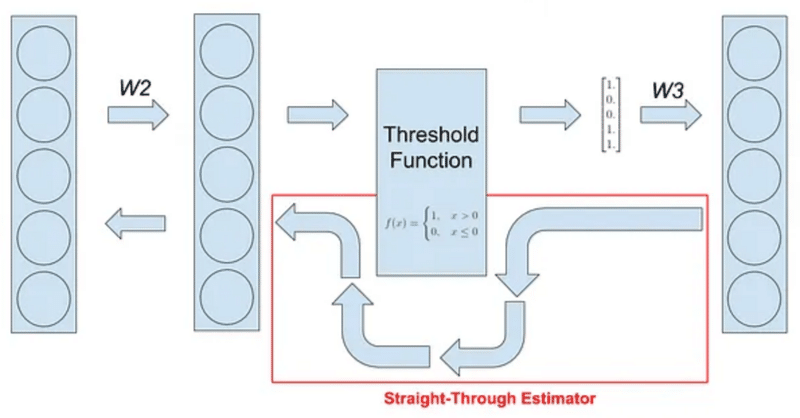
BitNetにおけるSTE(Straight-Through Estimator)の実装
はじめに現在、私は以下のような試みをしています。
BitNetとは
BitNetとはweightとactivationを量子化する手法の1つで、特にweightを{-1, 0, 1}の3値に量子化するBitNet b158はベースとしているLlama2の性能を上回ることを示し、注目を浴びました。
その実装の中で、量子化(つまりFloat16や32ではなくより離散的な値を扱う様にする処理)を行
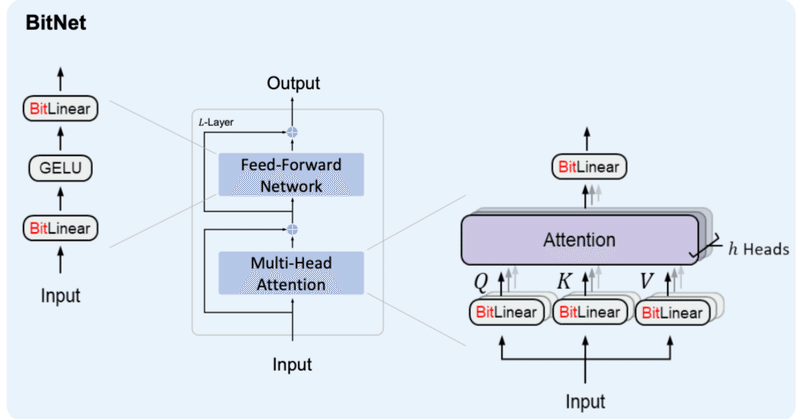
BitNet&BitNet b158の実装③
はじめにBitNetおよびBitNet b158の実装を続けていこうと思います。
ボリュームが大きくなってきたため、記事を分けることとしました。前回までの内容は以下をご参照ください。
2日連続での投稿となるので前後関係をお気をつけください。
3. BitNet b158これまでに作成したBitLinearを修正していく形でBitNet b158用のBitLinear b158を作成していきます。
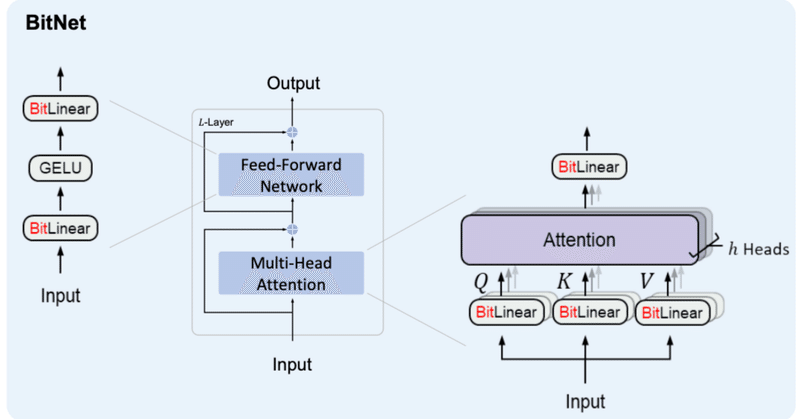
BitNet&BitNet b158の実装②
はじめに少し間が空いてしまいましたが、BitNetおよびBitNet b158の実装を続けていこうと思います。
ボリュームが大きくなってきたため、ページを分けることとしました。前回までの内容は以下をご参照ください。
2. BitNetの検証今回は、前回作ったBitNetの検証を進めていこうと思います。
検証内容としては、
BitLlamaの構築
事前学習ができるか(Lossが下がるか)確認

BitNetでMNISTを学習させて見えてきた性質
かれこれ一ヶ月弱くらいBitNetと格闘している。BitNetは、Microsoftが発明したと主張している1-Bit(1.58ビットとも言われる)量子化ニューラルネットワークのことだ。
僕はその辺に落ちてるコードを使って最初の最初はlossが2くらいまで下がったのだが、そもそもLLMはlossが1を切らないと実用性がない。
それ以降は6とか良くて5とかなのでたまたま最初に試したのがうまく行っ
BitNet&BitNet b158の実装①
はじめに先週発表された論文『The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits』は多くの人に衝撃を与えたと思います。
それまで量子化とは、有り体に言えば性能を犠牲にメモリ等のコストを抑える手法でした。しかし、BitNet b158(*)では量子化手法としては初めてオリジナルを超える性能を出す可能性を魅せてくれました。


大規模言語モデルの圧縮技術「BitNet」
最近公開されたMicrosoftの研究チームによる、大規模言語モデルの計算コストを削減する研究が、その革新的な手法で業界内外から大きな注目を集めています。この研究に興味を持ち、その背後にある技術やアプローチを深く掘り下げてみることにしました。
記事
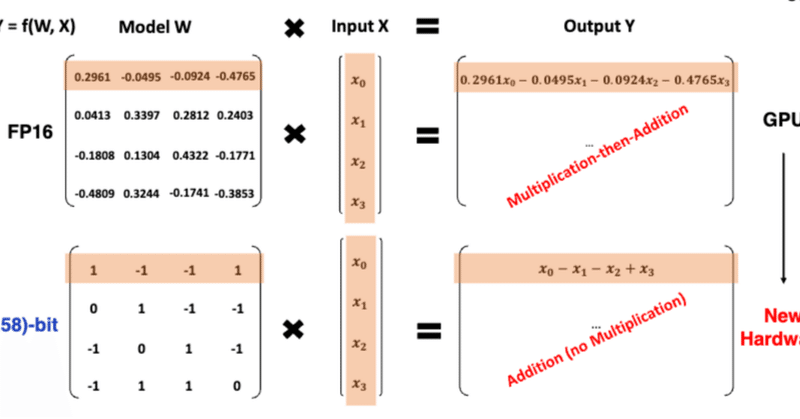
Microsoftが1.58ビットの大規模言語モデルをリリース、行列計算を足し算にできて計算コスト激減へ
https://gigazine.net/

速報:話題の 1ビットLLMとは何か?
2024-02-27にarXiv公開され,昨日(2024-02-28)あたりから日本のAI・LLM界隈でも大きな話題になっている、マイクロソフトの研究チームが発表した 1ビットLLMであるが、これは、かつてB-DCGAN(https://link.springer.com/chapter/10.1007/978-3-030-36708-4_5; arXiv:https://arxiv.org/ab
もっとみる