

2023年11月の記事一覧


LCM とかいう謎の技術を使って高速生成できるようにする(+拡張機能を作ったよ)
まずは下の映像をご覧ください
めっちゃ生成早いね!
今回はこのような高速生成を可能にするワザの紹介です
これは LCM-LoRA とかいうまったくよくわからん技術によって低ステップで生成できるようにした結果です
正直なところ意味はまったくわかりません
詳しい説明は以下の記事とかにあります(これは LCM 自体の説明だけど)
なるほどわからん!
早く使い方を教えろ!使い方は簡単で、以下の設定


Google Colab で ComfyUI を試す
「Google Colab」で「ComfyUI」を試したので、まとめました。
1. ComfyUI「ComfyUI」は、モジュール式の「StableDiffusion」のGUIです。グラフ/ノード/フローチャートベースのインターフェイスを使用して、コーディングなしに高度な「StableDiffusionパイプライン」を設計および実行することができます。
特徴は、次のとおりです。





【Stable Diffusion】「LoRA」自作をとりあえずできるようになる【Kohya’s GUI】
■記事の対象ユーザ
1.Stable Diffusion WebUIをローカルに構築して、イラスト生成しはじめた
2.LoRAが何かは知ってたり使ってたりするが、LoRAの作り方は知らない
■ようするに?
・学習用画像をあつめて加工する
・学習させるためのパラメータを設定をする
・学習させる → LoRAが出来る
学習に使うツールの準備好きなやり方で
先人の残した石碑によると幾つか方法が

Google Colab で LCM LoRA を試す
Google Colab で LCM LoRA を試したので、まとめました。
1. LCM LoRA「LCM」 (Latent Consistency Model) は、元モデルを別モデルに蒸留することで、画像生成に必要なステップ数を減らす手法です。25~50ステップかかっていた処理を4~8ステップで可能にします。
2. LCM LoRA の LoRAウェイト提供されている「LCM LoRA」

LCM LoRA の概要
以下の記事が面白かったので、かるくまとめました。
1. はじめに「LCM」 (Latent Consistency Model) は、元モデルを別モデルに蒸留することで、画像生成に必要なステップ数を減らす手法です。25~50ステップかかっていた処理を4~8ステップで可能にします。
蒸留したモデルは、より小さくなるように設計される場合 (DistilBERT、Distil-Whisperなど)と
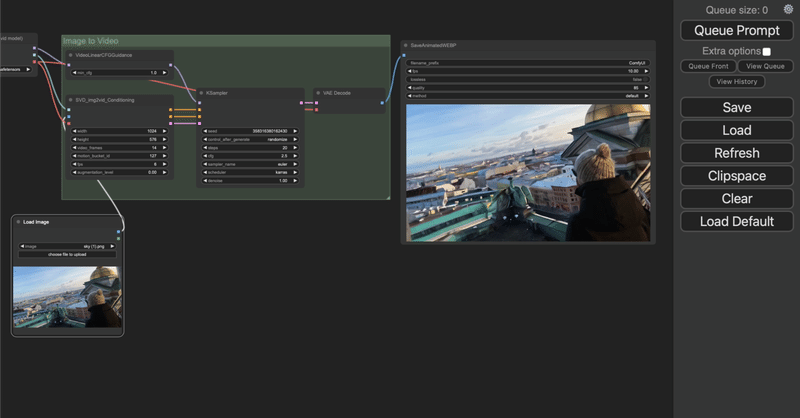
ComfyUI で Image-to-Video を試す
「ComfyUI」で Image-to-Video を試したので、まとめました。
前回
1. Image-to-Video「Image-to-Video」は、画像から動画を生成するタスクです。
現在、「Stable Video Diffusion」の2つのモデルが対応しています。
2. Colabでの実行Colabでの実行手順は、次のとおりです。
(1) セットアップ。
前回と同様です。
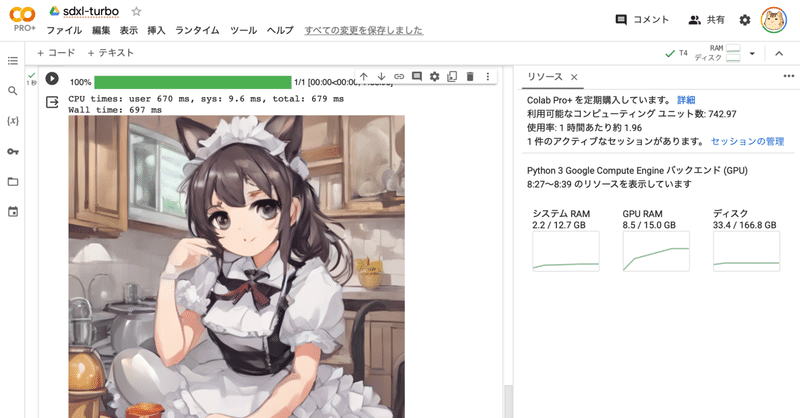
Google Colab で SDXL Turbo を試す
「Google Colab」で「SDXL Turbo」を試したので、まとめました。
1. SDXL Turbo「SDXL Turbo」は、「Stability AI」が開発した画像生成AIです。新しい蒸留技術によって、これまでにない品質のシングルステップ画像生成を可能にしました。必要なステップ数は50から1に削減されました。
2. Colabでの実行Colabでの実行手順は、次のとおりです。


日本特化の画像生成AIのJapanese Stable Diffusion XLを試してみた
SDXLなどの画像生成AIは、欧米の画像やキャプションを中心に学習しているため、基本的に英語入力が必要とされ、日本文化に根差した日本特有の物品や風景の画像を生成するのは得意ではありません。
今回、Stability AIから日本語入力が可能で、さらに日本特有のものを対象とした画像生成にも対応した日本特化の画像生成AIモデルであるJapanese Stable Diffusion XL(JSDXL

画像生成AI のリリース年表
主な「画像生成AI」「動画生成AI」のリリース年表をまとめました。
2021年1月5日 DALL-E (発表のみ)
画像生成
2022年7月12日 Midjourney
画像生成
7月20日 DALL-E 2
画像生成
7月25日 Midjourney v3
画像生成
8月22日 Stable Diffusion
画像生成
Stable Diffusion with 🧨