
【AP】令和6年秋午後問6データベースの解説(応用情報技術者試験)

このNoteでは「応用情報技術者試験 令和6年秋午後問6(データベース)」を解説します。
問題構成は流れはいつもの通り「仕様→ER図→SQL」。設問は完答選択肢がちょっと不安。そしてSQLが超地雷でした。
問題を選ぶ時に、SQLまで必ず見てください。
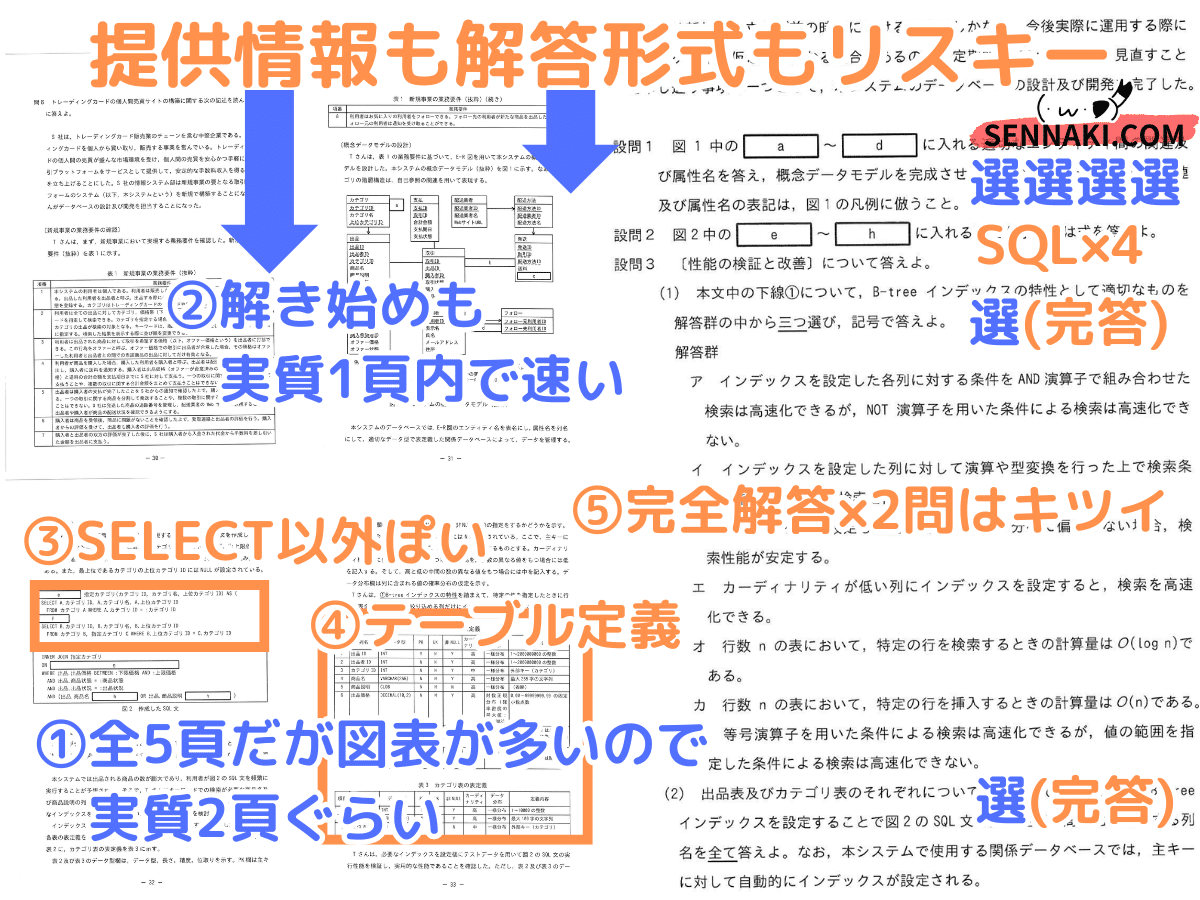
頑張れば6割は超えるかもですが、私が試験会場で解いても5割は切りませんが、6割超えるかは疑問です。

ER図の難易度がデスペレベルになりました(設問1(1)a, d)。SQLに「RECURSIVE」が出ました(設問2e, f)。さらに文字列連結「||」が出ました(設問2h)。
全体的に難易度が上がりました。前々からAPのDBは不安定だと思っていました。「DB切り」の準備はしてください。
このNoteでは、私がIT以外の学生時代にAPに独学合格した経験と、大学・IT専門学校で応用情報技術者試験の対策授業を担当した経験を詰め込んで作りました。
それでは始めましょう!
※このNoteは後日有料になります。お早めにお読みください。その後はマガジンに追加されます。マガジンも値上げしますので、お早めにご購入ください。
設問1(1) | 問題文の仕様から書き起こす
a:自分に1対多「→」
b:1対1「ー」
c:追跡番号
d:1対多「→」
必ず正解してください。
ER図は、仕様(問題文)を元に作成されます。どんなエンティティ(表に相当)を作るのか、エンティティに入れるべき項目、エンティティ同士の個数対応も、全て問題文に書かれています。
今回は表1にまとめて書かれていました。
設問1(1)a | 階層=自己回帰リレーション
a:自分に1対多「→」
「カテゴリ」エンティティを問題文から探します。
表1項番1「カテゴリは~階層化されている」より、自身にリレーションを繋げます。子カテゴリの親カテゴリもカテゴリにだから。
あとは、1対1「ー」か1対多「→」か。
個数対応の記述を問題文から探しましたがなし。一般常識で考えて、「1つ」の親カテゴリに「複数」の子カテゴリが属するので1対多と判断。
APで自己回帰が出たのは初かも。デスペでは常識です。APの難易度が上がったかもですね。>【デスペ用】ER図のまとめNote
設問1(1)b | 注文と発送の個数対応は基礎
b:1対1「ー」
「取引」と「発送」の関係を探します。ネット通販すると分かりますが、「1度」の注文で「複数」の商品を購入して、発送が「個別(複数)」だったり「一括」だったりしますよね。
個数を示す言葉が見所です。
表1項番5「一つの取引に関する商品を分割して発送すること~はできない」なので、1対多を否定しています。1対1の「ー」。
よくあるパターン。受注と受注明細は1対多。受注と発送は1対1だったり1対多だったり。今回は取引と発送が1対多でした。
以下のエンティティと個数対応のとこだけ見てくださいね。



設問1(1)c | 追加で記録する項目も基礎
c:追跡番号
発送に記録すべき情報がないか探します。
よくあるのは、届いたかどうかの「配達フラグ」とか。注文発送の問題を解いてると、段々予想が付きます。
表1項番5「発送した商品の追跡番号を管理」。図1の他のエンティティにないのを確認して、確定。
私はメルカリを使っているんですが、発送した/されたら、問合せ番号が表示されます。購入者も出品者も輸送の状態が見れます。

IPAの試験では「日頃の経験」で正解・納得できることも多いです。例えば、2段階認証やリスクベース認証。googleさんへのログインで経験がありますよね。>長文問題の解法テクニック6の2
設問1(1)d | リレーションを2本引く場合
d:1対多「→」
既に一本引かれていて驚いたかもですね。今回のa(自己)と同じで今回はちょいムズめ。
表1項番8にフォローの記述がありますが、なぜ2本なのか。図1のフォローEに利用者IDが2つあり、利用者Eには1つなので、2本引くんだろうな、でOK。
個数対応。フォローの特性を考えるとすぐです。
上の「→」から解釈。「1人」の利用者は「複数」の利用者をフォローする。
下の「→」の解釈。「1人」の利用者は「複数」の利用者からフォローされる。
これも設問1(1)aの自己回帰と同じで、デスペの基礎レベル。デスペでは同じエンティティに2本引くこと結構あるんです。「キット」「セット」を作ったときは下図の通り(連関エンティティと云います)。
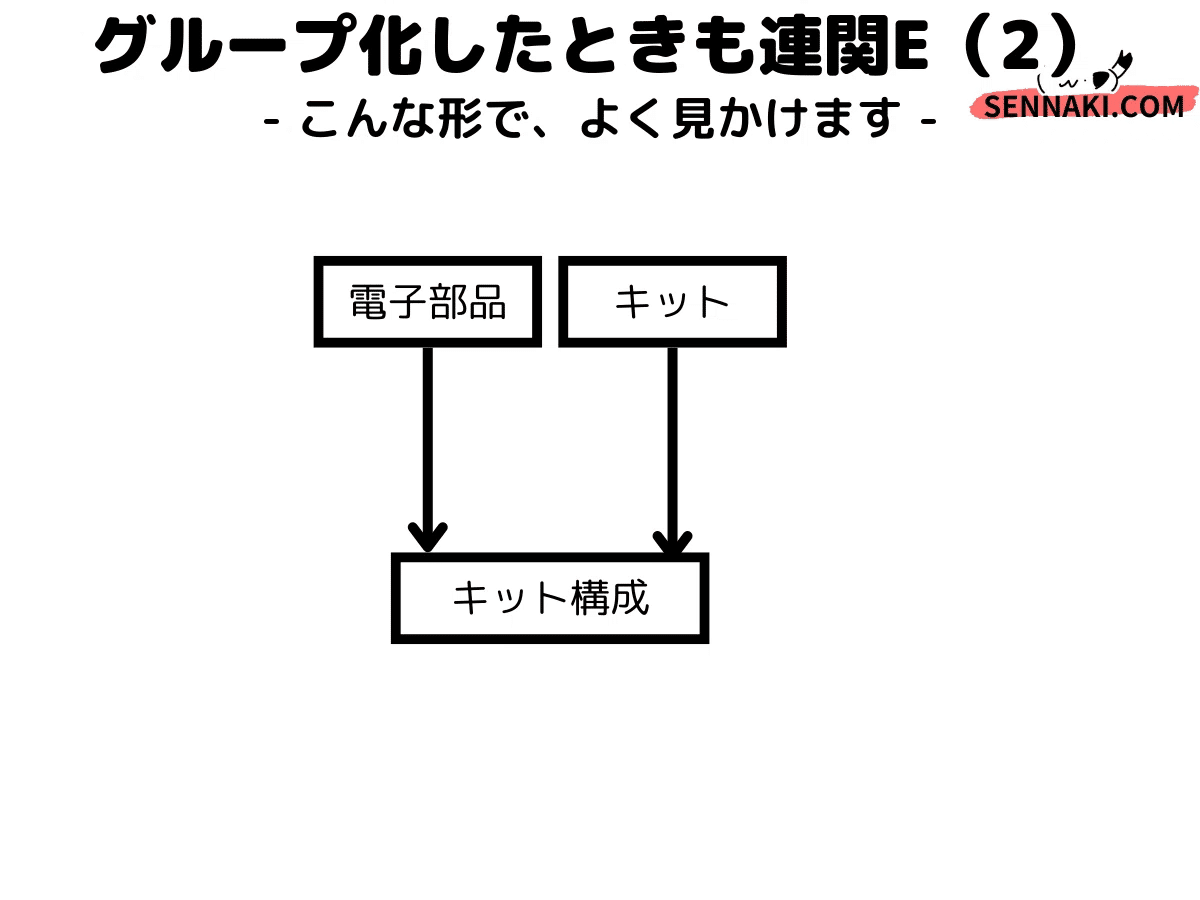
ER図には色んな形があるので、パターンを知っておくと良いです。>デスペ用のER図まとめNoteより
補強 | DBだけ「読み方」が違う
私は問題文の線引き方法を決めています。
四角囲み:システム名、組織名
丸囲み:数値
アンダーライン:要旨を構成
▼印:怪しいポイント
読みながら、解く時に必要になる情報にタグ付けしているようなもの。
アンダーラインは読み返す時に便利、丸囲みは計算問題が出た時に数値を一気にピックアップ、▼印は「これ危ないでしょ」「これ後で問われるでしょ」と予測しているので、解答になる場合が多いです。
特に▼印は、セキュリティ問題で有効。「USBメモリ」「IDを共有」「~の設定をしていない」「全て」など、いかにもアブナイので、後で問われる可能性大ですから。>長文問題を読むテクニック3の3
さてDBの話。マーキングの意味を少し変えます。
四角囲み:システム名、組織名、エンティティや項目
丸囲み:数値・個数
アンダーライン:要旨を構成
▼印:怪しいポイント
データベース設計の問題は大抵「問題文→スキーマ→ER図→SQL文」。よって問題文の時点で、エンティティ・項目・個数対応の情報を拾いやすくしておきます。
四角囲みは、「エンティティ(表)にしそうだな」「項目にするでしょ」と思ったらします。項目は、まとめて書かれますが、1つ2つぽつんと離れて書かれることもあります。
丸囲みは、ER図の個数対応のため。「一意」「1つの」「複数の」「まとめて」などがキーワード。
例えば今回設問1(1)bは、1対1になると示唆しています。表1項番5「一つの取引に関する商品を分割して発送すること~はできない」。「一つ」「分割~できない」に注目。
設問2(1)h | SQLの連結記号
h:LIKE '%' || :キーワード || '%'
手が込んでましたね。知るかーいと、思いますよね。
ワイルドカード「%」「_」と連結演算子「||」。
キーワードの仕様は表1項番2「キーワードは、商品名及び商品説明を部分一致で検索」。部分一致。
つまり検索キーワードが「イヤホン」なら、「ワイヤレスイヤホン」も「イヤホンカバー」も「ワイヤレスイヤホンカバー」も拾いたい。そして「イヤホン」だけも拾いたい。
DBで任意の文字列を指すのは「_」と「%」。「ワイルドカード」と云います
_:1文字の任意の文字
%:0文字以上の任意の文字or文字列
つまり。
_イヤホン
Aイヤホン
%イヤホン
イヤホン
Aイヤホン
ABイヤホン
※更に前に文字がついてOK
イヤホン%
イヤホン
イヤホンA
イヤホンAB
※更に後に文字がついてOK
よって「%イヤホン%」とできれば勝ち。これが今までの旧FEやAPの話。
今回は「埋込み変数」を使っているので、「:キーワード」も入れ込みたいですがそのままではエラー。SQL文を解釈するデータベースのプログラム的な話です。どこが文字でどこが特殊記号でどこが変数なのか、を混乱しないように伝えねばなりません。
そこで今回登場したのが、連結演算子「||」。
「%イヤホン%」のイヤホンを変数にしたいので、 「||」で文字列「%」と変数「:キーワード」を繋げているんです。
次で少し詳しく解説しますね。
補強 | 色々な連結記号
文字列と変数をつなげたい時、SQLでは「||」を使いました。
エクセルでは「&」、Pythonでは「+」を使います。
エクセルやスプレッドシートで、A1セルに1、A2セルに2があるとき、A3セルに「=A1&"+"&A2」とすると、「1+2」が出力されます。

Pythonでは「+」で連結。なお「print(f"{a1}+{a2}")」という記述法もあります。

記号は違いますが、日常の中に「変数と文字列の結合」は潜んでいましたね。経験ある方も多いかなと。
なお、C言語だと「||」はOR、Linuxコマンドだと「|」はコマンドを繋げる記号です。>【セキスペ用】Linuxの基礎(パイプライン)
設問2(1)g | WHERE句の最初は結合条件かも
g:出品.カテゴリID = 指定カテゴリ.カテゴリID
出品表(FROM句)と指定カテゴリ表を結合(JOIN)しています。
図1を見て、出品表にカテゴリIDあり。図2のWITH句。指定カテゴリ表にカテゴリIDあり。よって、カテゴリIDで紐づけて結合していると判断。
なお、指定カテゴリ表には、上位カテゴリIDもありますが、不要。RECURSIVEで上位も全て抜き出しているので。
複数の表を結合するSELECT文の場合、WHERE句の最初に結合条件を書きます(他の例を見たことがありません)。複数の表が出てきた時は、最初に疑うようにしてみてくださいね。
設問2(1)e, f | 再帰的SQL
e:WITH RECURSIVE
f:UNION ALL
知るかーい!と。
まず最小限で行きます。乱暴ですが。
WITH句は一時的なテーブルを作る
WITH RECURSIVE句で再帰SQLを作る
再帰SQLでの結合はいつもUNION ALL
要は、今後「再帰SQL」と来たら「WITH RECURSIVE」「UNION ALL」に決め打ち。
私はとりあえず正解できるレベルで留めます。
本当は、あの表とこの表がどう結合して~と学ぶのが勿論良いです。しかし、また試験にでるのか、正解するのに理解が必要か、理解するまでの時間と手間、を考えて。あくまで資格合格を目的とした話です。データベースを使える技術者を目指すなら、どこかで理解してくださいね。
補強 | DBの難易度が上がってる
APのSQL後半って、FETCHとCURSORを書いていれば大抵正解でした。しかしR05秋ではWINDOW関数が出たし、今回はRECURSIVE。おいおい、難易度爆上がりじゃん。
R05秋のWINDOW関数はHELPが書いてあったので、まだ良かったんですよ。

逆に言えば、知らなくてもそのまま書けば正解できるので、作問者側としては良くないんですが。今回はノーヒントで来ましたね。
せめて選択肢にしてくれれば良かったのに。recursiveは英単語で「繰り返す」って意味で予測できます。他の選択肢を理解しておけば消去法でも解答できるので。今回の奇襲記述は理不尽です。
私の解説逃げですが。SQLの動作を全て考えたり理解してたら時間が足りません。例えば、SELECT, ORDER, GROUPの処理順とか。結構色んなルールがあるんです。
本当は知ってないとダメなんですが、資格合格/学習コスパを考えて、ほどほどで留めます。
気になる方や「全部理解しないなんて技術者として何事か」な方は、お手数ですが、ご自分で調べてください。
良さそうな参考サイトさんを上げておきますね。
参考1, 参考2, 参考3, 参考4, 参考5, 参考6, 参考7, 参考8, 参考9
色んな書き方/見せ方をされているので、ご自分に合いそうなものから読んでいけば宜しいかと。
ER図の自己回帰・2本繋ぎで難易度が上がり、SQL文のRECURSIVEでも難易度が上がりました。ダブル上りは珍しいし、えぐいですね。
APのDB難易度が上がり過ぎていると、5年前から思ってましたが。「DB切り」は選択肢に入れねばなりませんね。秋がヤバイ気がしています。
設問3(1)
正答は、ア, ウ, オ
これもなかなか難しい上に、完全解答だから得点は困難ですね。
各選択肢の理由付けだけでも。
ア:正しい:インデックスは探す工夫です。ANDなら探す条件を重ねるので速くなり得ます。NOTは「それ以外」なので探す範囲の絞り込みにインデックスが効きにくい。
イ:誤り:インデックスは検索速度をあげる工夫なので、データの型は無関係。インデックスの方法とデータの分布の相性が検索速度に影響します。
ウ:正しい:偏りがないと木構造がキレイに維持されるので、計算量が節約できます。
エ:誤り:カーディナリティ(値の種類数)が低いと、B-Treeの多くの子にまとめる特性が発揮されません、B-Treeは3個以上の子を持てる木です。
オ:正しい:B-treeは2分探索木なのでO(log n)。データ数(n)が多くなっても上昇量が緩やか。
カ:誤り:O(n)は線形探索など。データ数(n)が多くなるとそのまま計算時間も多くなる。
キ:誤り:B-Treeはソートしたデータを木構造に格納しているので、値の範囲を指定すれば辿りやすい。
次にB-Treeについて、少し理解していきます。
B-Tree(B木)では、データを木構造にして格納します。この時点で計算量はO(log n)系。O(n)ではないです。オとカが決着。
木構造には、色んな種類があります。良く例で見るのは、子が2つまでの「二分木」。深さを全て同じにする「平衡木」。これらの性質を組み合わせて、色んな種類の木があります(wikipedia)。
B-Treeは、「多分木」で「平衡木」。子を3個以上持てて、全ての深さが同じになっている構造。
多くの子を持てるので、カーディナリティ(値の種類数)が高くても、まとめて子にできます(図解はwikipedia)。エが決着。
平衡木なので分布が偏っていると平衡木にする処理が大変です。ウが決着。
厳密でないですが、こんな感じで一応決着とさせて下さい。色々調べましたが、分かり易く理解が進んだサイトさん。参考サイト, 参考サイト
なお木構造は探索だけでなく、ソート(並び替え)にも使われますし、迷路のデータ化にも使われます(AIのG検定に出ます)。午前問題を見てください。FEH27春問6, APH24秋問6(ソート)
設問3(2)
出品表:カテゴリID, 出品価格
カテゴリ表:上位カテゴリID
図2SQLの高速化なので、SQL文で探している列を抜き出します。
WITH RECURSIVE
カテゴリ.カテゴリID:1発目のWHRE句
カテゴリ.上位カテゴリID:2発目のWHERE句
SELECT文
出品.カテゴリID: ON句(空欄g)
出品.出品価格:WHERE句
出品.商品状態:WHERE句
出品.出品状況:WHERE句
出品.商品名:WHERE句
出品.商品説明:WHERE句
候補は8個。
設問文のただし書き「主キーに対して自動的にインデックスが設定されている」。
表2出品表の主キーは出品ID(PKがYなので)。表3カテゴリ表の主キーはカテゴリID。これらはインデックス済みなので、解答には書きません。カテゴリ表のカテゴリIDが主キーなので、候補からなくなり、候補は6個。
次はカーディナリティが「低」を削ります。商品状態や出品情報は1~3の3種類なのでインデックスの効果が薄いですから。
With RECURSIVE
カテゴリ.カテゴリID:主キーなのでカテゴリ.上位カテゴリID:中
SELECT文
出品.カテゴリID:中
出品.出品価格:高
出品.商品状態:低出品.出品状況:低出品.商品名:高
出品.商品説明:高
ここからアバウトでごめんなさい。商品名と商品説明って何でも書けますよね。しかも検索がLIKEで部分一致なので、結局全部覗いてキーワードがあるか判定するしかない。削ります。
残り3個。
カテゴリ.上位カテゴリID:中
出品.カテゴリID:中
出品.出品価格:高
カテゴリは、カーディナリティが中ですが、今回のメイン。利用者は必ずカテゴリで探します(表1項番2)。分布も一様分布でB-Tree向き。
よって「カテゴリ.上位カテゴリID」と「出品.カテゴリID」を採用。
出品価格は、カーディナリティが高いのでインデックスしたい気持ちが強いです。分布が一様分布ではないですが、B-Tree木はソート済みで格納します。よって値で絞り込むのは得意分野。
以上より、ノーヒント問題な上に、アバウトな解説で申し訳ないですが、模範解答の理由付けとさせてください。
「こうあるべきだ!」とおっしゃる方はご自分の意見を貫けば良いと思います。ただ、試験の採点は模範解答(+おそらく追って別解を検討)でされるので、失点はご了承ください。私は「模範解答に寄せた解答を書くにはどう考えるか」を軸に解説しています。
「こうあるべきだ!」は自分の実務で成せば良い。試験は得点して合格せねば、と「私は」考えています。
まとめ
お疲れ様でした!
解説がイマイチで、もやもやが残ったり、逆に横道にそれた補強が目障りだったかもと思います。すみません。他の解説サイト/動画さんなどご自分で調べて頂ければと思います。お手数おかけします。
今回は「私は復習をこれぐらいで留めておく」という話が多かったのが特徴的でした。
引き続き過去問演習をしていって合格してくださいね。でわでわ。
\全ての無料Noteへのリンク!/
\全てのAP系Noteが読めます/
いいなと思ったら応援しよう!
