
StanとRでベイズ統計モデリングをPyMC Ver.5で写経~第10章「10.2.2 正の値を持つパラメータ」前編

第10章「収束しない場合の対処法」
書籍の著者 松浦健太郎 先生
この記事は、テキスト第10章「収束しない場合の対処法」・10.2節「弱情報事前分布」の 10.2.2項「正の値を持つパラメータ」の PyMC5写経 を取り扱います。
この記事は10.2.2項の前半部分、model8-4.stanの改造のところまでを扱っています。
テキストは第10章で 収束に向けた工夫を取り扱っています。
座学や数式モデルのみの掲載項があれば、Stanコードの掲載項もあります。
PyMC化は主にStanコードが明示されているモデル式を対象にして実施します。
したがいまして、10.2.1「(-∞, ∞)の範囲のパラメータ」の写経は省略しました。
はじめに
StanとRでベイズ統計モデリングの紹介
この記事は書籍「StanとRでベイズ統計モデリング」(共立出版、「テキスト」と呼びます)のベイズモデルを用いて、PyMC Ver.5で「実験的」に写経する翻訳的ドキュメンタリーです。
テキストは、2016年10月に発売され、ベイズモデリングのモデル式とプログラミングに関する丁寧な解説とモデリングの改善ポイントを網羅するチュートリアル「実践解説書」です。もちろん素晴らしいです!
「アヒル本」の愛称で多くのベイジアンに愛されてきた書籍です!
テキストに従ってStanとRで実践する予定でしたが、RのStan環境を整えることができませんでした(泣)
そこでこのシリーズは、テキストのベイズモデルをPyMC Ver.5に書き換えて実践します。
引用表記
この記事は、出典に記載の書籍に掲載された文章及びコードを引用し、適宜、掲載文章とコードを改変して書いています。
【出典】
「StanとRでベイズ統計モデリング」初版第13刷、著者 松浦健太郎、共立出版
記事中のイラストは、「かわいいフリー素材集いらすとや」さんのイラストをお借りしています。
ありがとうございます!
PyMC環境の準備
Anacondaを用いる環境構築とGoogle ColaboratoryでPyMCを動かす方法について、次の記事にまとめています。
「PyMCを動かすまでの準備」章をご覧ください。
10.2.2 正の値を持つパラメータ 前編
10.2.2項の前編では、標準偏差の弱情報事前分布を扱っています。
インポート
### インポート
# 数値・確率計算
import pandas as pd
import numpy as np
import scipy.stats as stats
# PyMC
import pymc as pm
import arviz as az
# 描画
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.family'] = 'Meiryo'
# ワーニング表示の抑制
import warnings
warnings.simplefilter('ignore')
逆ガンマ分布・半t分布・半正規分布
従前より標準偏差・分散のパラメータの事前分布に使われてきた逆ガンマ分布と、推奨する半t分布・半正規分布について、分布の形状を確認します。
まずはじめに、逆ガンマ分布の確率密度関数を描画します。
テキスト図10.2に相当します。
### 逆ガンマ分布の確率密度関数の描画 ◆図10.2
## 設定値
alphas = [0.1, 0.001]
betas = [0.1, 0.001]
colors = ['tab:blue', 'tab:red']
linestyles = ['-', '--']
x_maxs = [10, 0.01]
## 確率密度関数の算出&描画処理
# 描画領域の設定
fig, ax = plt.subplots(1, 2, figsize=(8, 3), sharey=True)
# 2つのaxesへ描画を繰り返し処理
for i, xmax in enumerate(x_maxs):
# 2つの逆ガンマ分布の確率密度関数の描画を繰り返し処理
for alpha, beta, color, ls in zip(alphas, betas, colors, linestyles):
# x軸の値の算出
x_val = np.linspace(0, xmax, 10001)
# 逆ガンマ分布の確率密度関数(y軸の値)の算出
y_val = stats.invgamma.pdf(x_val, a=alpha, loc=0, scale=beta)
# 逆ガンマ分布の確率密度関数の描画
ax[i].plot(x_val, y_val, color=color, ls=ls,
label=f'invGamma({alpha},{beta})')
# 修飾
ax[i].set(xlabel='$y$', ylabel='Probability density')
ax[i].grid(lw=0.5)
# 全体修飾
ax[0].legend()
plt.tight_layout();【実行結果】

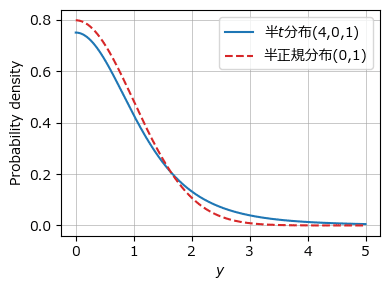
続いて半t分布と半正規分布の確率密度関数を描画します。
テキスト図10.3に相当します。
### 半t分布と半正規分布の確率密度関数の描画 ◆図10.3
# 描画領域の設定
plt.figure(figsize=(4, 3))
ax = plt.subplot()
# x軸の値の設定
x_val = np.linspace(0, 5, 1001)
# 半t分布の確率密度関数の算出&描画
half_t_val = stats.t.pdf(x_val, df=4, loc=0, scale=1) * 2
ax.plot(x_val, half_t_val, color='tab:blue', label='半$t$分布(4,0,1)')
# 半正規分布の確率密度関数の描画&描画
half_norm_val = stats.halfnorm.pdf(x_val, loc=0, scale=1)
ax.plot(x_val, half_norm_val, color='tab:red', ls='--', label='半正規分布(0,1)')
# 修飾
ax.set(xlabel='$y$', ylabel='Probability density')
ax.grid(lw=0.5)
ax.legend()
plt.tight_layout();【実行結果】

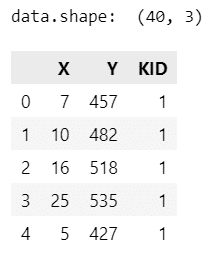
データの読み込み
第8章 8.1「階層モデルの導入」で使用したテキストファイル data-salary-2.txt を読み込みます。
### データの読み込み ◆データファイル8.1 data-salary-2.txt
# X:年齢-23, Y:年収, KID:勤務会社ID
data = pd.read_csv('./data/data-salary-2.txt')
print('data.shape: ', data.shape)
display(data.head())【実行結果】

PyMCのモデル構築
Pythonで実装します。
テキストでは model8-4.stan のモデルを改造しています。
PyMC化の際、model8-4.stan のモデルは発散を含んでいるため、同じ結果になるであろう model8-3.stan のモデルでPyMC化することにします。
model8-3.stan や model8-4.stan のPyMC化に関しては、以前の記事をご覧ください。
改造前後の推論結果を比較するので、model8-3.stan改造前と改造後の2つのモデルを構築します。

model8-3.stan改造前
モデルの定義です。
### モデルの定義 ◆モデル式8-3 model8-3.stan 改造前
with pm.Model() as model3:
### データ関連定義
## coordの定義
model3.add_coord('data', values=data.index, mutable=True)
model3.add_coord('kaisha', values=sorted(data.KID.unique()), mutable=True)
## dataの定義
# 目的変数 Y
Y = pm.ConstantData('Y', value=data['Y'].values, dims='data')
# 説明変数 X
X = pm.ConstantData('X', value=data['X'].values, dims='data')
# 説明変数 KIdx 会社インデックス
KIdx = pm.ConstantData('KIdx', value=k_idx.values, dims='data')
### 事前分布
a0 = pm.Uniform('a0', lower=-10000, upper=10000)
b0 = pm.Uniform('b0', lower=-10000, upper=10000)
sigmaA = pm.Uniform('sigmaA', lower=0, upper=1000)
sigmaB = pm.Uniform('sigmaB', lower=0, upper=1000)
sigmaY = pm.Uniform('sigmaY', lower=0, upper=10000)
ak = pm.Normal('ak', mu=0, sigma=sigmaA, dims='kaisha')
bk = pm.Normal('bk', mu=0, sigma=sigmaB, dims='kaisha')
### 線形予測子
a = pm.Deterministic('a', a0 + ak, dims='kaisha')
b = pm.Deterministic('b', b0 + bk, dims='kaisha')
mu = pm.Deterministic('mu', a[KIdx] + b[KIdx] * X, dims='data')
### 尤度関数
obs = pm.Normal('obs', mu=mu, sigma=sigmaY, observed=Y, dims='data')MCMCを実行します。
### 事後分布からのサンプリング 1分20秒
with model3:
idata3 = pm.sample(draws=1000, tune=1000, chains=4, target_accept=0.8,
nuts_sampler='numpyro', random_seed=1234)【実行結果】省略
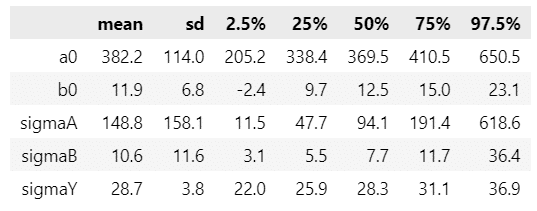
事後分布の要約統計量を算出します。
算出関数を定義します。
### mean,sd,2.5%,25%,50%,75%,97.5%パーセンタイル点をデータフレーム化する関数の定義
def make_stats_df(y):
probs = [2.5, 25, 50, 75, 97.5]
columns = ['mean', 'sd'] + [str(s) + '%' for s in probs]
quantiles = pd.DataFrame(np.percentile(y, probs, axis=0).T, index=y.columns)
tmp_df = pd.concat([y.mean(axis=0), y.std(axis=0), quantiles], axis=1)
tmp_df.columns=columns
return tmp_df要約統計量を算出します。
### 要約統計量の算出・表示
vars = ['a0', 'b0', 'sigmaA', 'sigmaB', 'sigmaY']
param_samples = idata3.posterior[vars].to_dataframe().reset_index(drop=True)
display(make_stats_df(param_samples).round(1))【実行結果】
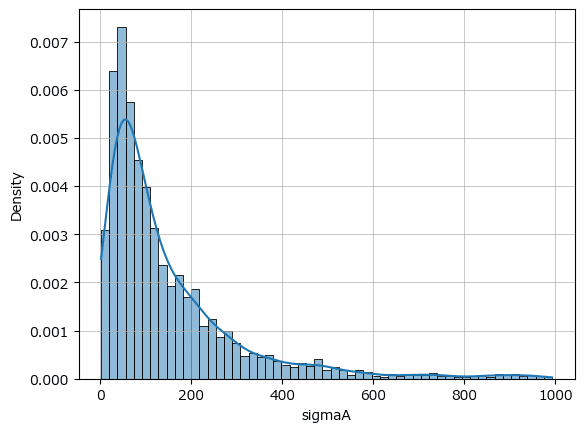
$${\sigma_a}$$のMCMCサンプルのヒストグラムと密度関数を描画します。
テキスト図10.4左に相当します。
### sigmaAのMCMCサンプルのヒストグラムと密度関数の描画 ◆図10.4左
sns.histplot(param_samples['sigmaA'], kde=True, stat='density')
plt.grid(lw=0.5);【実行結果】

model8-3.stan改造後
モデルの定義です。
sigmaA の従う確率分布を半t分布に変えています。
### モデルの定義 改造後
with pm.Model() as model4:
### データ関連定義
## coordの定義
model4.add_coord('data', values=data.index, mutable=True)
model4.add_coord('kaisha', values=sorted(data.KID.unique()), mutable=True)
## dataの定義
# 目的変数 Y
Y = pm.ConstantData('Y', value=data['Y'].values, dims='data')
# 説明変数 X
X = pm.ConstantData('X', value=data['X'].values, dims='data')
# 説明変数 KIdx 会社インデックス
KIdx = pm.ConstantData('KIdx', value=k_idx.values, dims='data')
### 事前分布
a0 = pm.Uniform('a0', lower=-10000, upper=10000)
b0 = pm.Uniform('b0', lower=-10000, upper=10000)
sigmaA = pm.HalfStudentT('sigmaA', nu=4, sigma=100) # <=== 修正点
sigmaB = pm.Uniform('sigmaB', lower=0, upper=1000)
sigmaY = pm.Uniform('sigmaY', lower=0, upper=10000)
ak = pm.Normal('ak', mu=0, sigma=sigmaA, dims='kaisha')
bk = pm.Normal('bk', mu=0, sigma=sigmaB, dims='kaisha')
### 線形予測子
a = pm.Deterministic('a', a0 + ak, dims='kaisha')
b = pm.Deterministic('b', b0 + bk, dims='kaisha')
mu = pm.Deterministic('mu', a[KIdx] + b[KIdx] * X, dims='data')
### 尤度関数
obs = pm.Normal('obs', mu=mu, sigma=sigmaY, observed=Y, dims='data')モデルの定義内容を見ます。
### モデルの表示
model4【実行結果】

### モデルの可視化
pm.model_to_graphviz(model4)【実行結果】

MCMCを実行します。
### 事後分布からのサンプリング 1分
with model4:
idata4 = pm.sample(draws=1000, tune=1000, chains=4, target_accept=0.98,
nuts_sampler='numpyro', random_seed=1234)【実行結果】省略
Pythonで事後分布からのサンプリングデータの確認を行います。
Rhatの確認から。
テキストの収束条件は「chainを3以上にし$${\hat{R}<1.1}$$のとき」です。
### r_hat>1.1の確認
# 設定
idata_in = idata4 # idata名
threshold = 1.01 # しきい値
# しきい値を超えるR_hatの個数を表示
print((az.rhat(idata_in) > threshold).sum())【実行結果】
収束条件を満たしています。

トレースプロットを描画します。
### トレースプロットの表示
var_names = ['a0', 'b0', 'sigmaA', 'sigmaB', 'sigmaY', 'a', 'b', 'mu']
pm.plot_trace(idata4, compact=True, var_names=var_names)
plt.tight_layout();【実行結果】

事後分布の要約統計量を算出します。
### 要約統計量の算出・表示
vars = ['a0', 'b0', 'sigmaA', 'sigmaB', 'sigmaY']
param_samples2 = idata4.posterior[vars].to_dataframe().reset_index(drop=True)
display(make_stats_df(param_samples2).round(1))【実行結果】
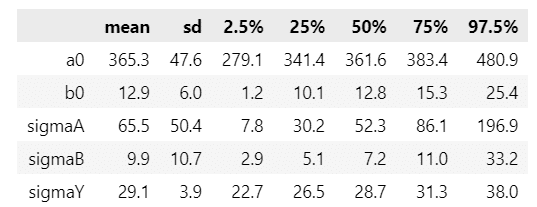
(参考:改造前モデルの事後分布の要約統計量)
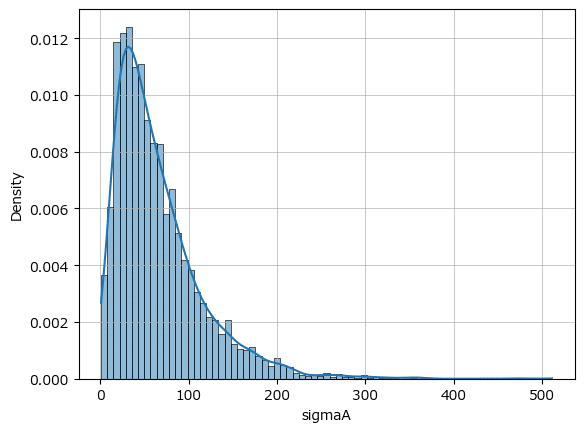
$${\sigma_a}$$のMCMCサンプルのヒストグラムと密度関数を描画します。
テキスト図10.4左に相当します。
### sigmaAのMCMCサンプルのヒストグラムと密度関数の描画 ◆図10.4右
sns.histplot(param_samples2['sigmaA'], kde=True, stat='density')
plt.grid(lw=0.5);【実行結果】
改造前モデルのヒストグラムとよく似た形状に見えますが・・・。
改造前・後の比較
改造前・後の$${\sigma_a}$$のMCMCサンプルのヒストグラム&密度関数を横並びにして描画します。
テキスト図10.4に相当します。
### σ_aのMCMCサンプルのヒストグラムと密度関数の描画 ◆図10.4
# 描画領域の設定
fig, ax = plt.subplots(1, 2, figsize=(8, 4), sharex=True, sharey=True)
# 無情報事前分布(一様分布)を使った場合のMCMCサンプルのヒストグラムの描画
sns.histplot(param_samples['sigmaA'], kde=True, stat='density', ec='white',
ax=ax[0])
ax[0].set(title='Uniform(0,1000)', xlabel=r'$\sigma_a$',
ylabel='probability density')
ax[0].grid(lw=0.5)
# 弱情報事前分布(半t分布)を使った場合のMCMCサンプルのヒストグラムの描画
sns.histplot(param_samples2['sigmaA'], kde=True, stat='density', ec='white',
ax=ax[1])
ax[1].set(title='HalfStudentT(4,100)', xlabel=r'$\sigma_a$')
ax[1].grid(lw=0.5)
plt.tight_layout();【実行結果】
改造後はバラツキが小さくなったようです。

10.2.2 項の前編は以上です。

シリーズの記事
次の記事
前の記事
目次
ブログの紹介
note で7つのシリーズ記事を書いています。
ぜひ覗いていってくださいね!
1.のんびり統計
統計検定2級の問題集を手がかりにして、確率・統計をざっくり掘り下げるブログです。
雑談感覚で大丈夫です。ぜひ覗いていってくださいね。
統計検定2級公式問題集CBT対応版に対応しています。
Python、EXCELのサンプルコードの配布もあります。
2.実験!たのしいベイズモデリング1&2をPyMC Ver.5で
書籍「たのしいベイズモデリング」・「たのしいベイズモデリング2」の心理学研究に用いられたベイズモデルを PyMC Ver.5で描いて分析します。
この書籍をはじめ、多くのベイズモデルは R言語+Stanで書かれています。
PyMCの可能性を探り出し、手軽にベイズモデリングを実践できるように努めます。
身近なテーマ、イメージしやすいテーマですので、ぜひぜひPyMCで動かして、一緒に楽しみましょう!
3.実験!岩波データサイエンス1のベイズモデリングをPyMC Ver.5で
書籍「実験!岩波データサイエンスvol.1」の4人のベイジアンによるベイズモデルを PyMC Ver.5で描いて分析します。
この書籍はベイズプログラミングのイロハをざっくりと学ぶことができる良書です。
楽しくPyMCモデルを動かして、ベイズと仲良しになれた気がします。
みなさんもぜひぜひPyMCで動かして、一緒に遊んで学びましょう!
4.楽しい写経 ベイズ・Python等
ベイズ、Python、その他の「書籍の写経活動」の成果をブログにします。
主にPythonへの翻訳に取り組んでいます。
写経に取り組むお仲間さんのサンプルコードになれば幸いです🍀
5.RとStanではじめる心理学のための時系列分析入門 を PythonとPyMC Ver.5 で
書籍「RとStanではじめる心理学のための時系列分析入門」の時系列分析をPythonとPyMC Ver.5 で実践します。
この書籍には時系列分析のテーマが盛りだくさん!
時系列分析の懐の深さを実感いたしました。
大好きなPythonで楽しく時系列分析を学びます。
6.データサイエンスっぽいことを綴る
統計、データ分析、AI、機械学習、Pythonのコラムを不定期に綴っています。
統計・データサイエンス書籍にまつわる記事が多いです。
「統計」「Python」「数学とPython」「R」のシリーズが生まれています。
7.Python機械学習プログラミング実践記
書籍「Python機械学習プログラミング PyTorch & scikit-learn編」を学んだときのさまざまな思いを記事にしました。
この書籍は、scikit-learnとPyTorchの教科書です。
よかったらぜひ、お試しくださいませ。
最後までお読みいただきまして、ありがとうございました。