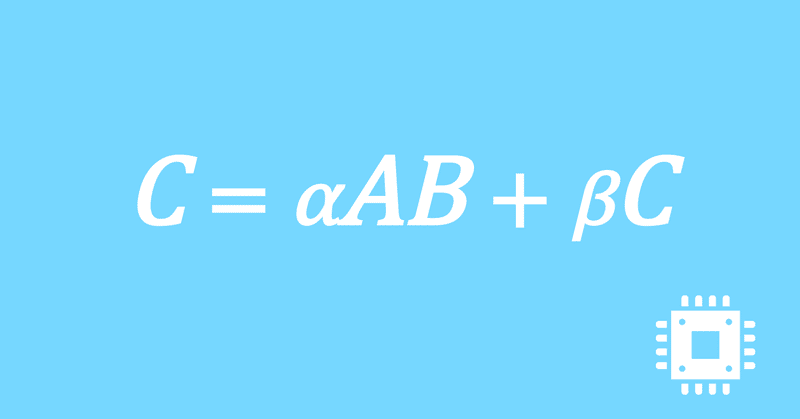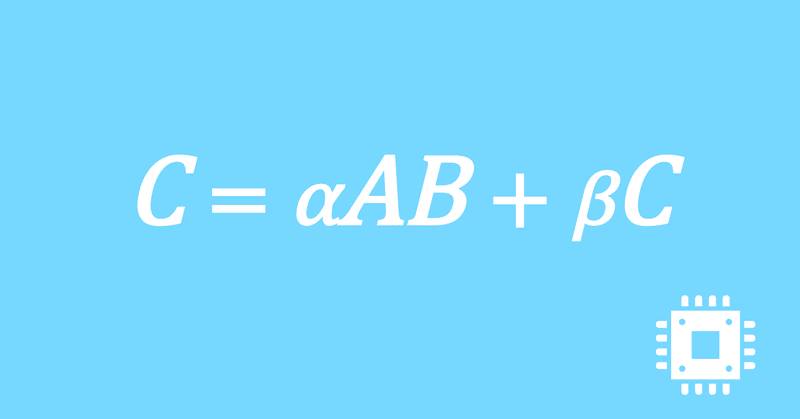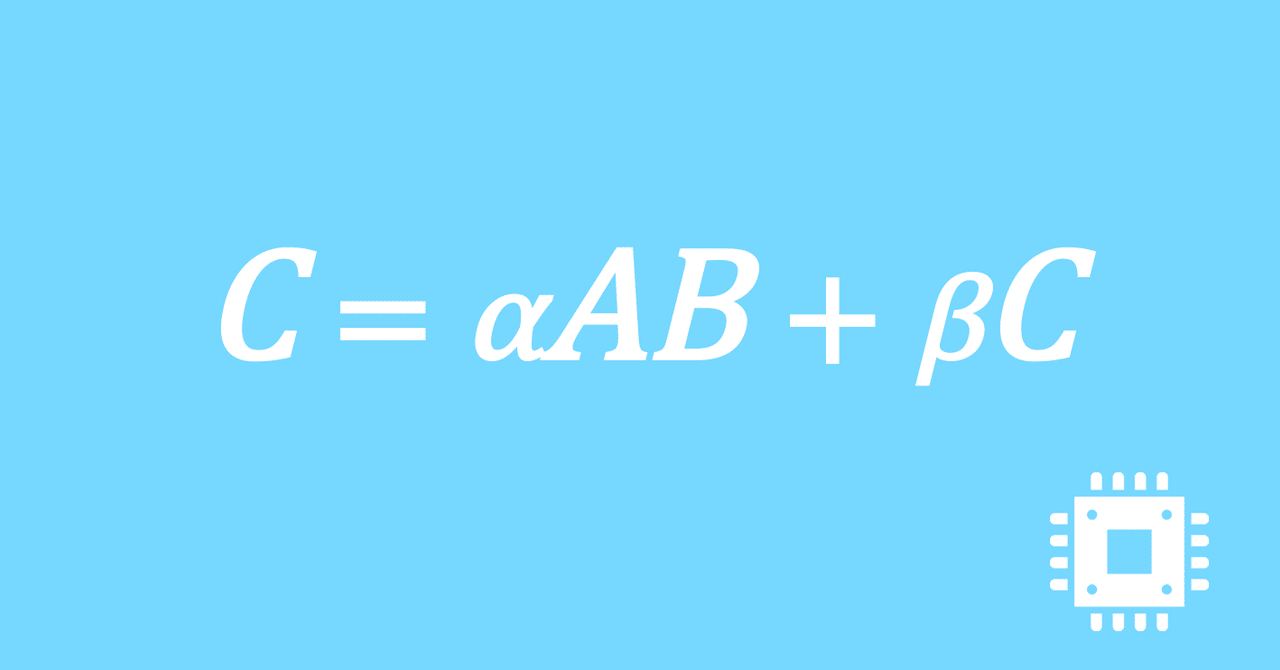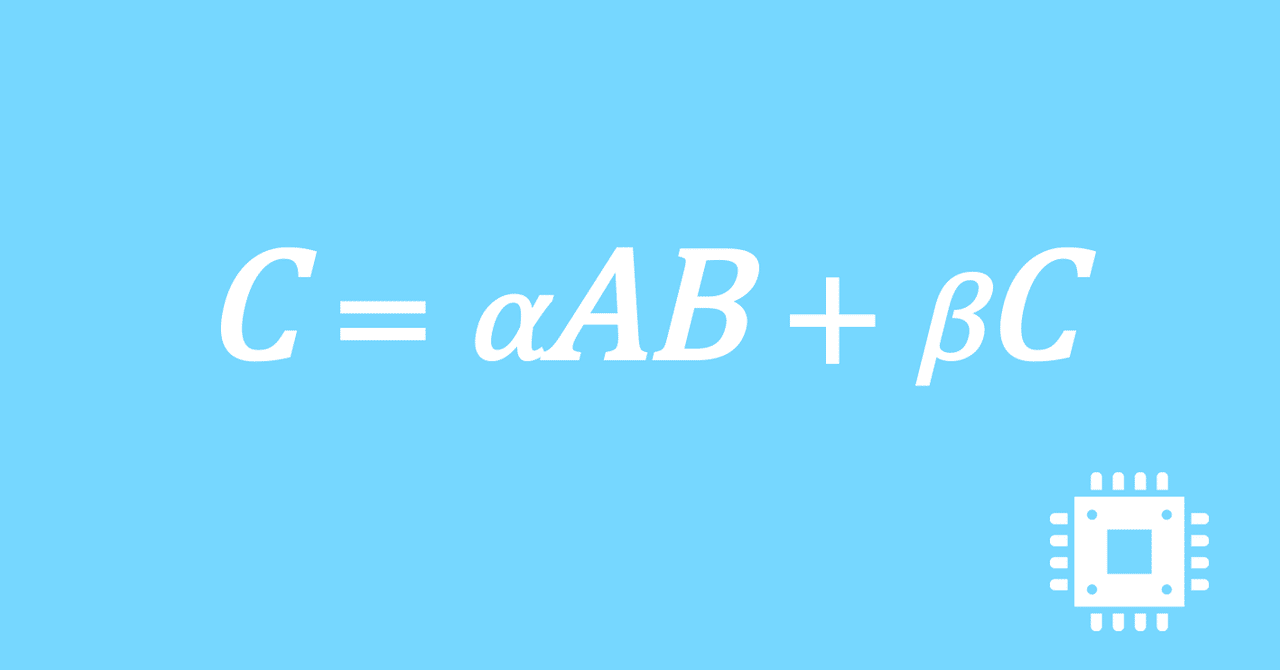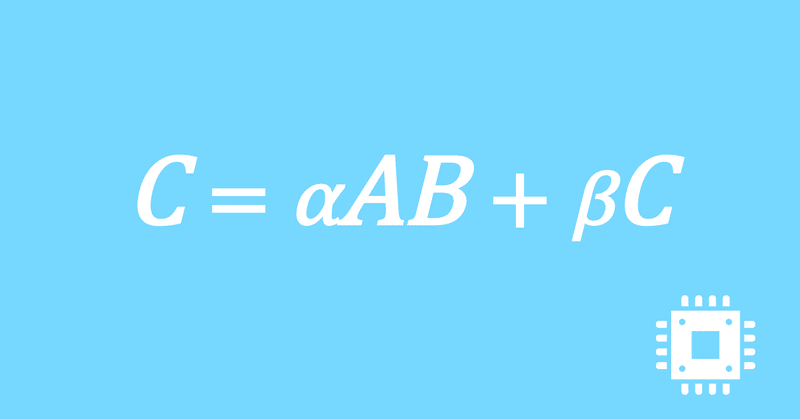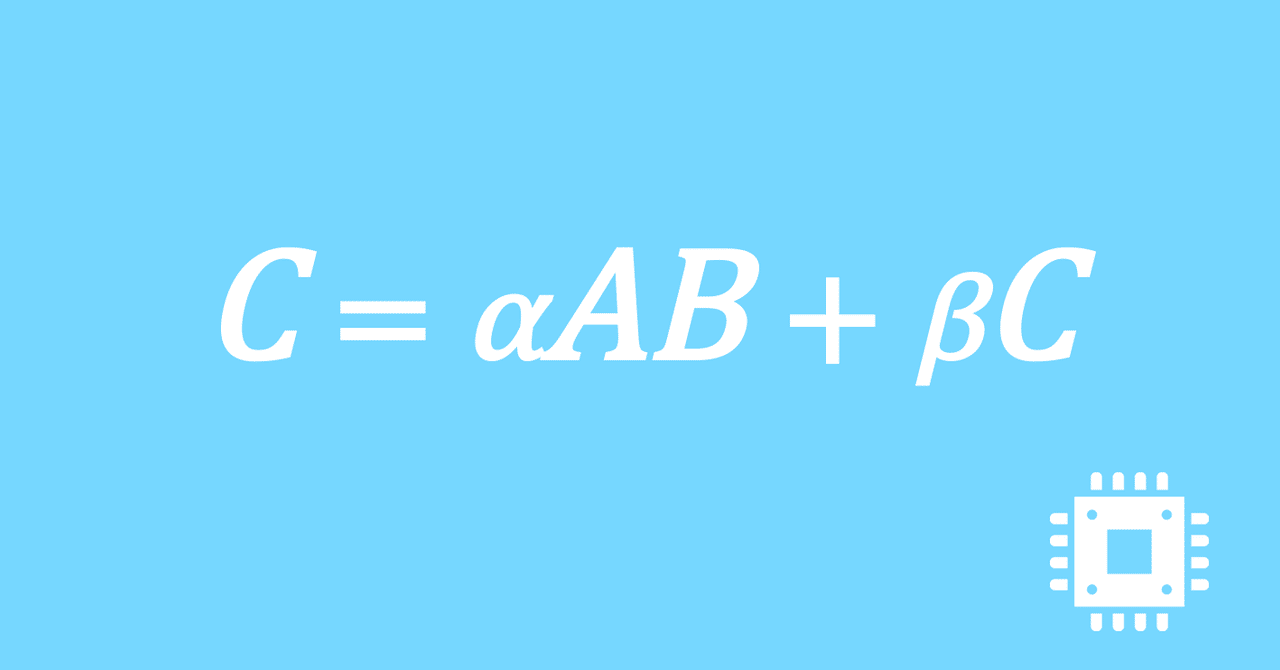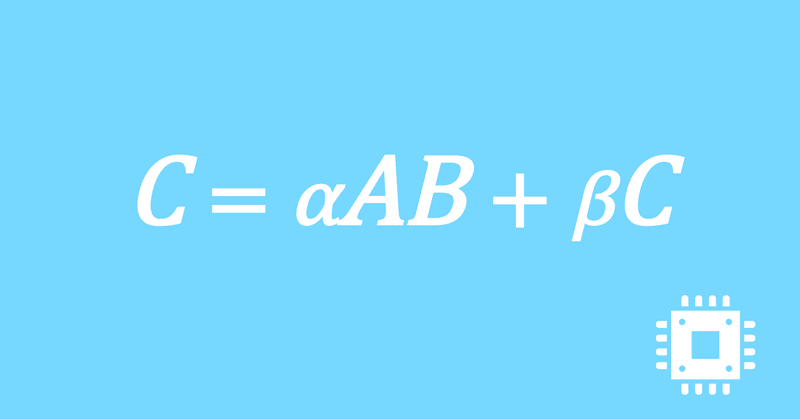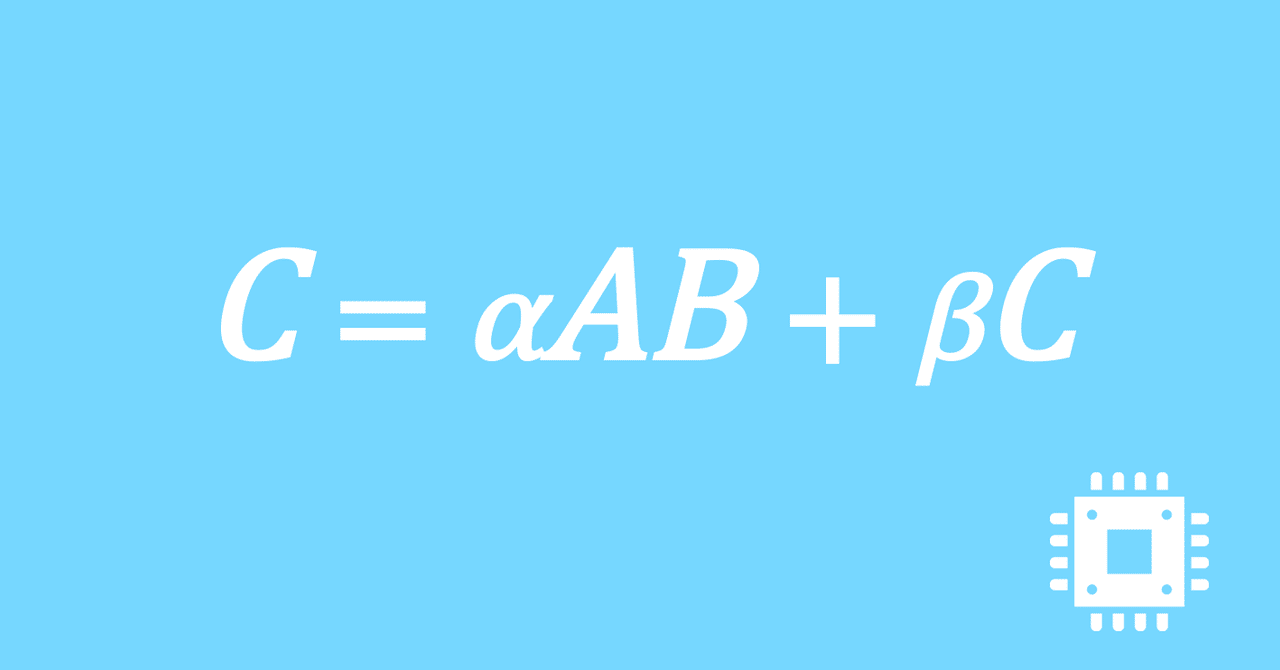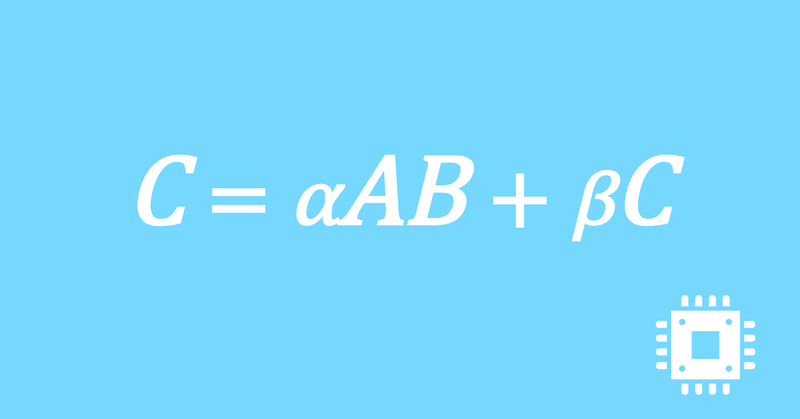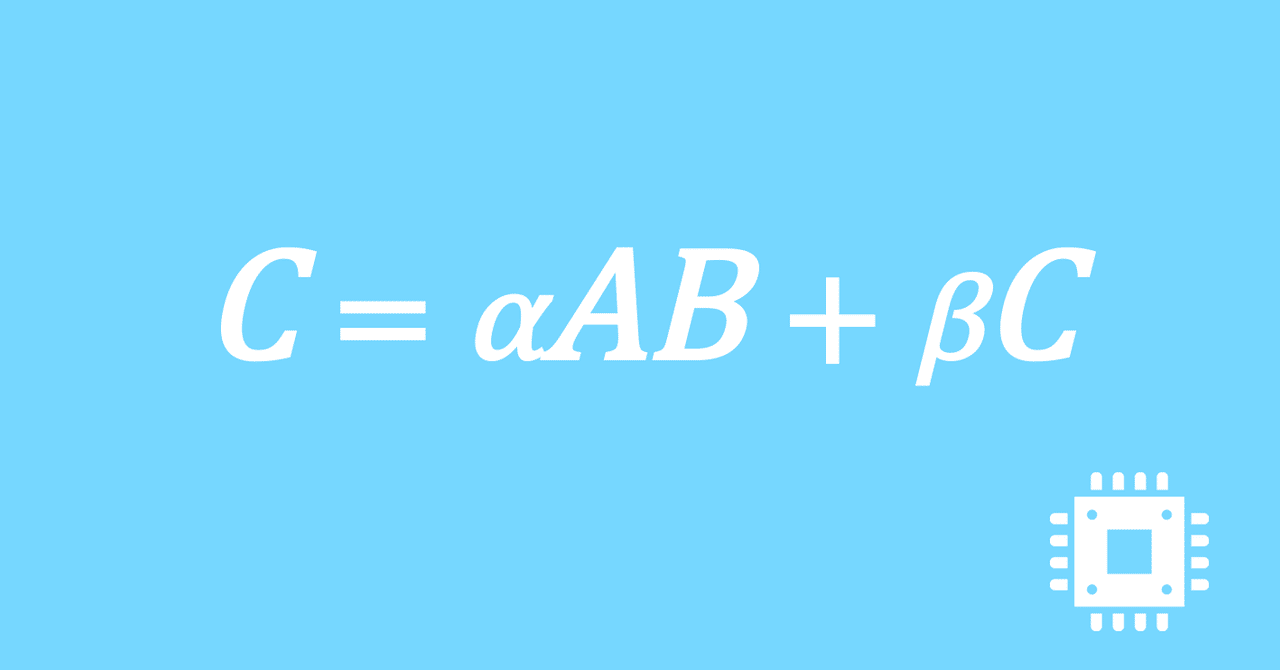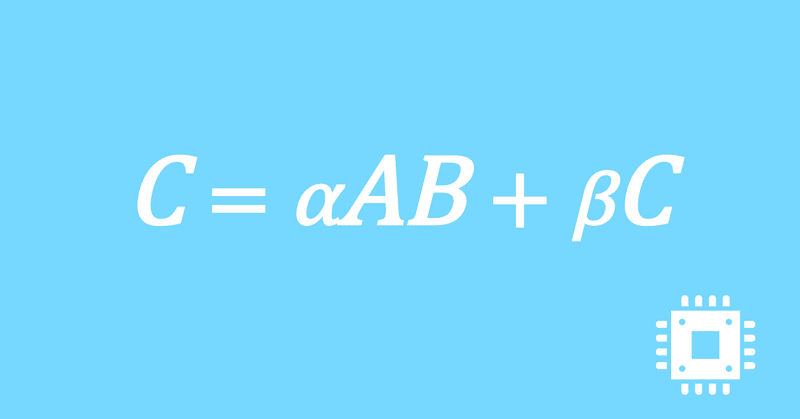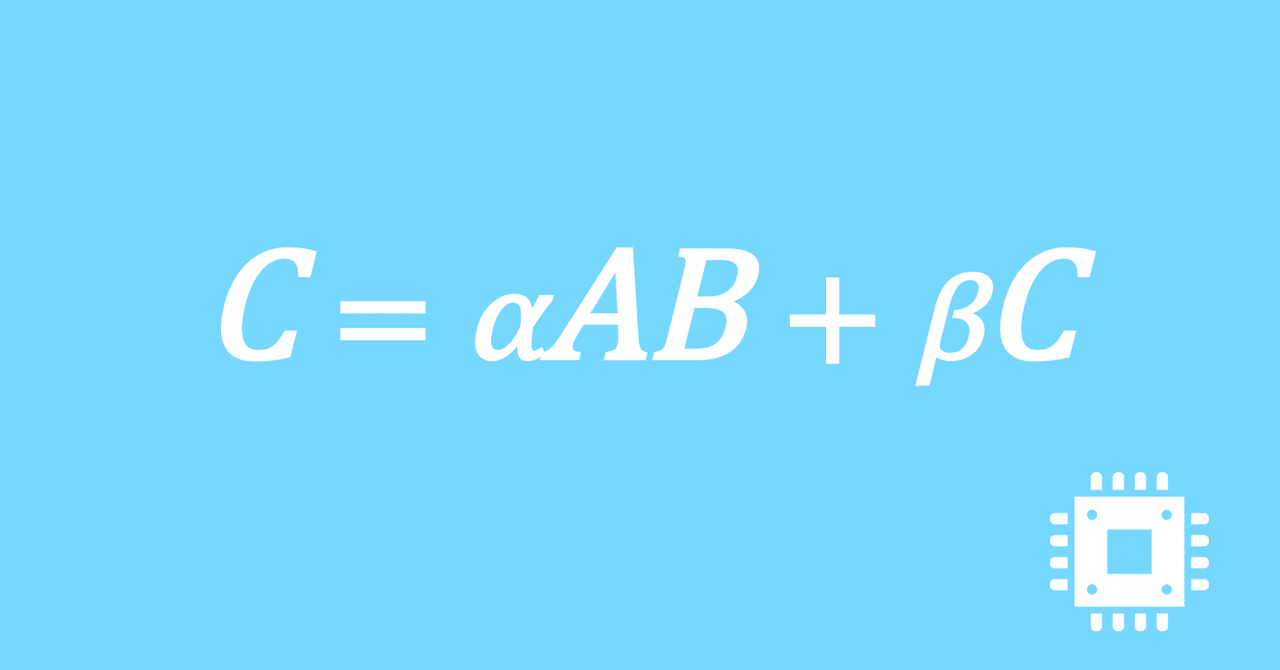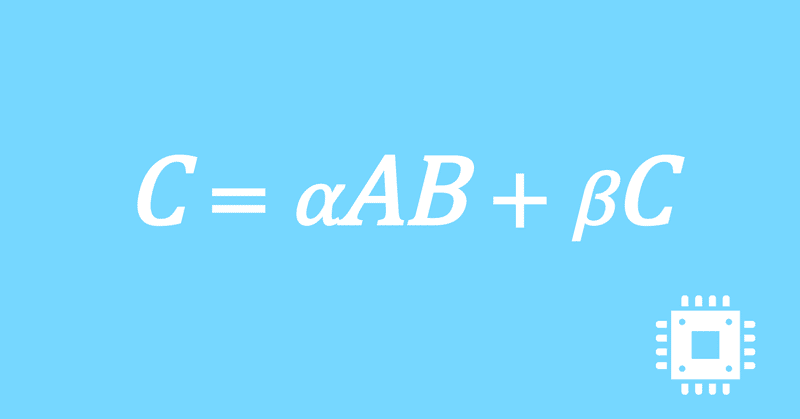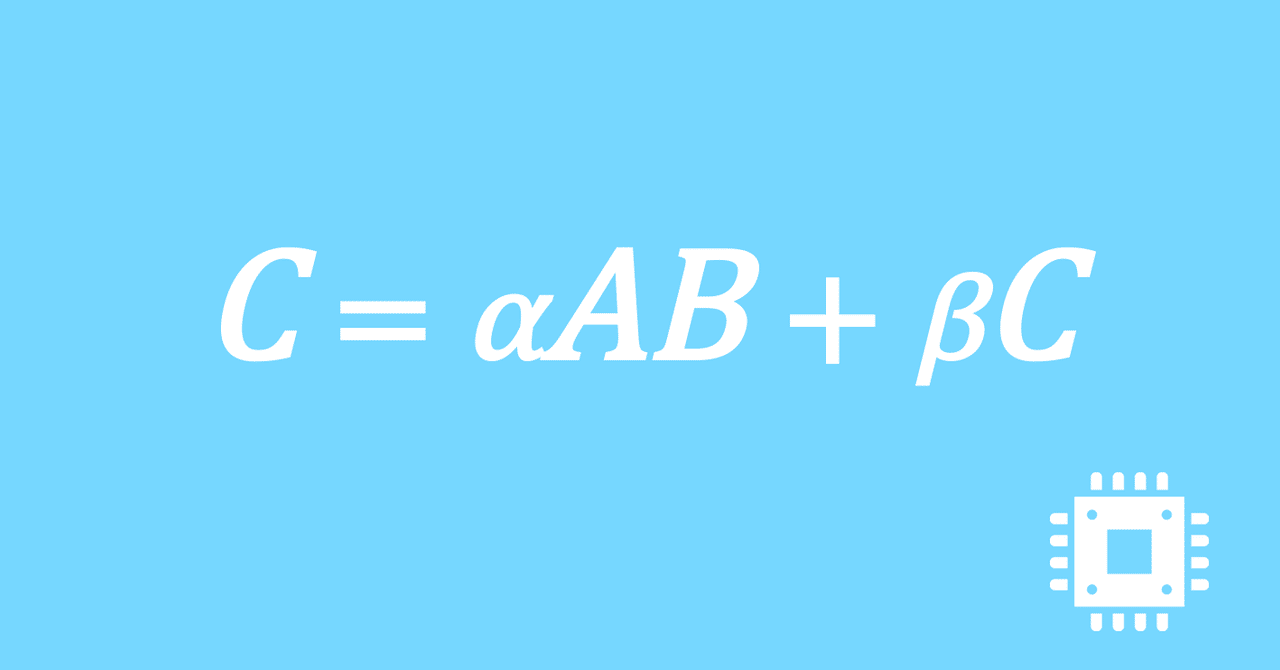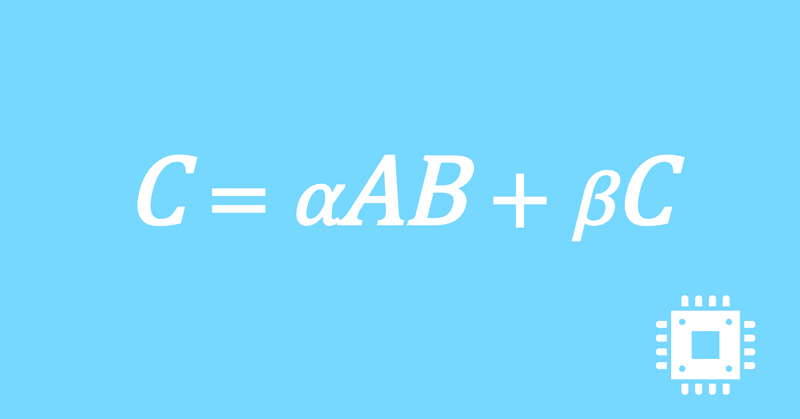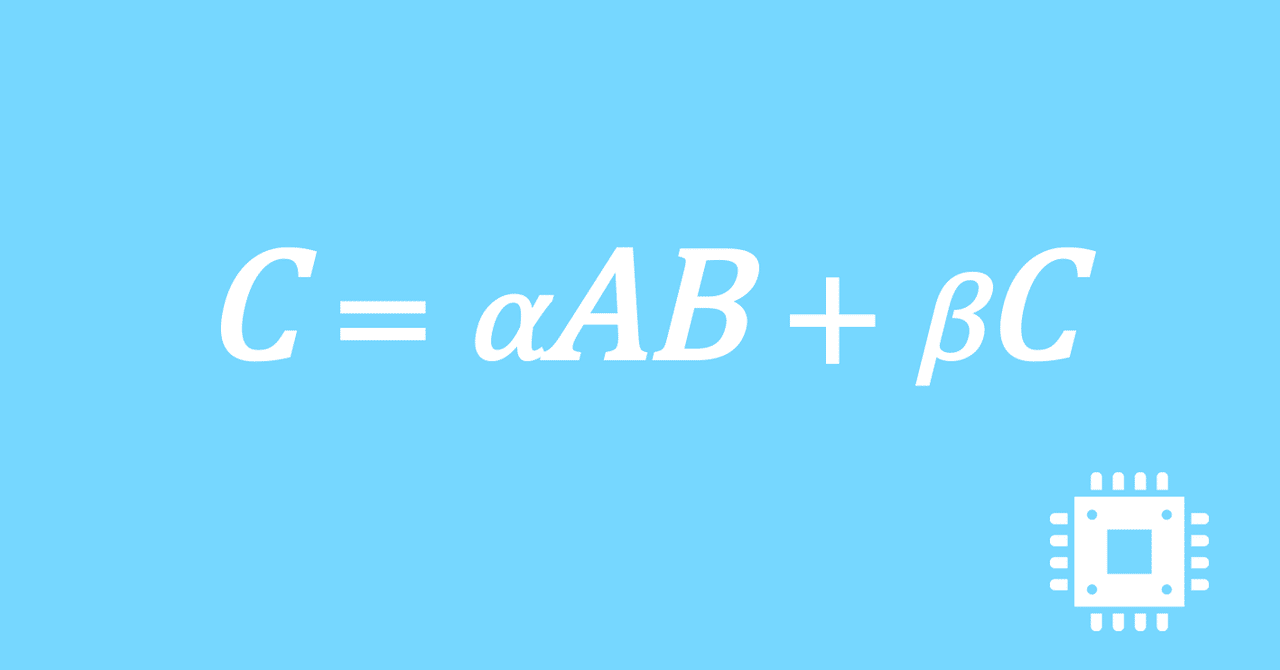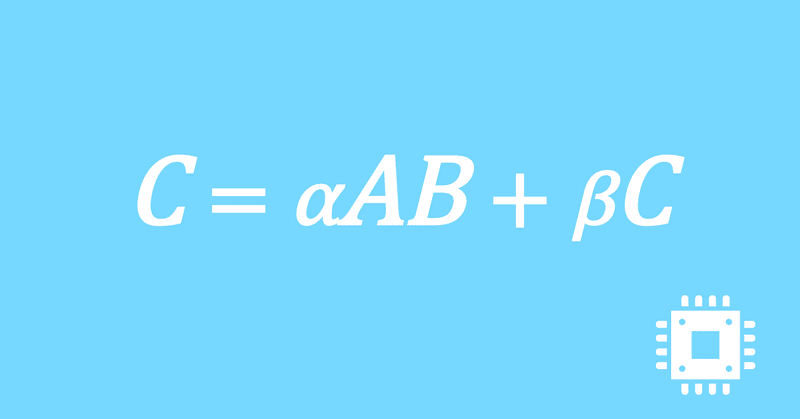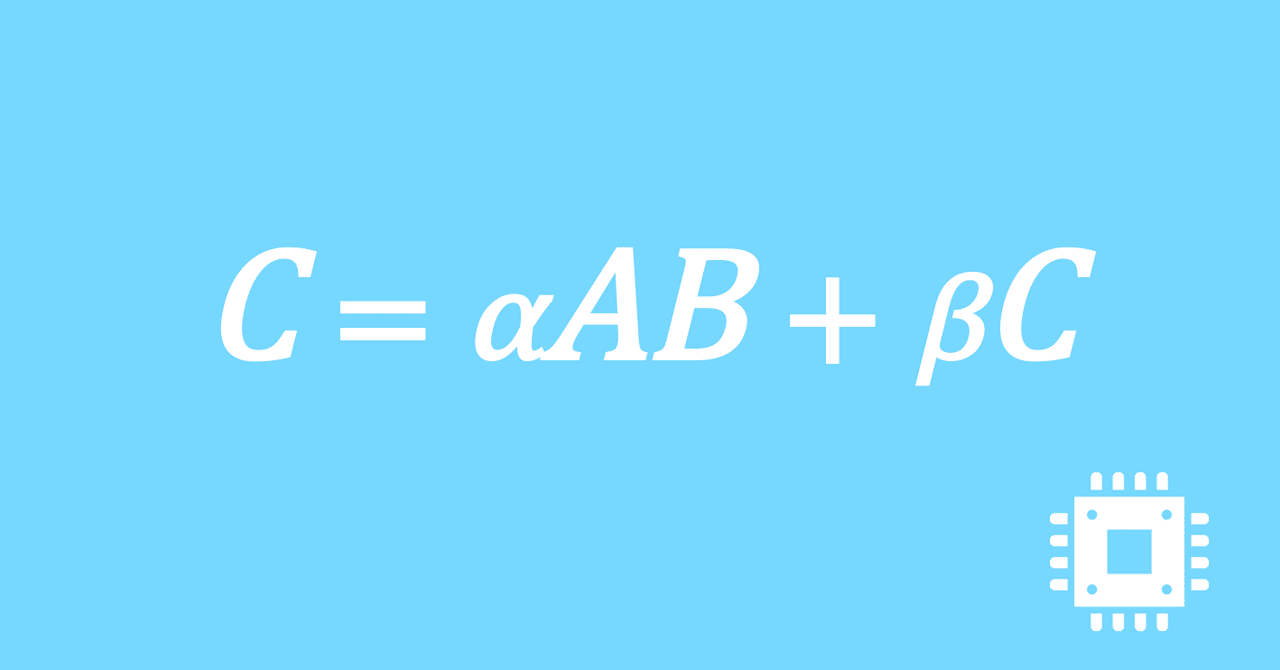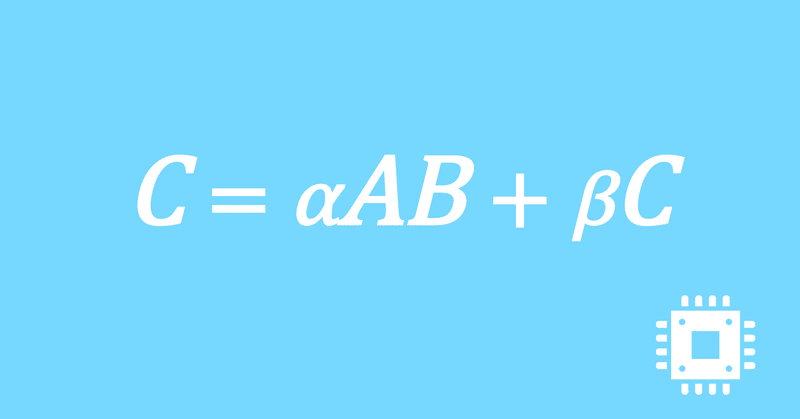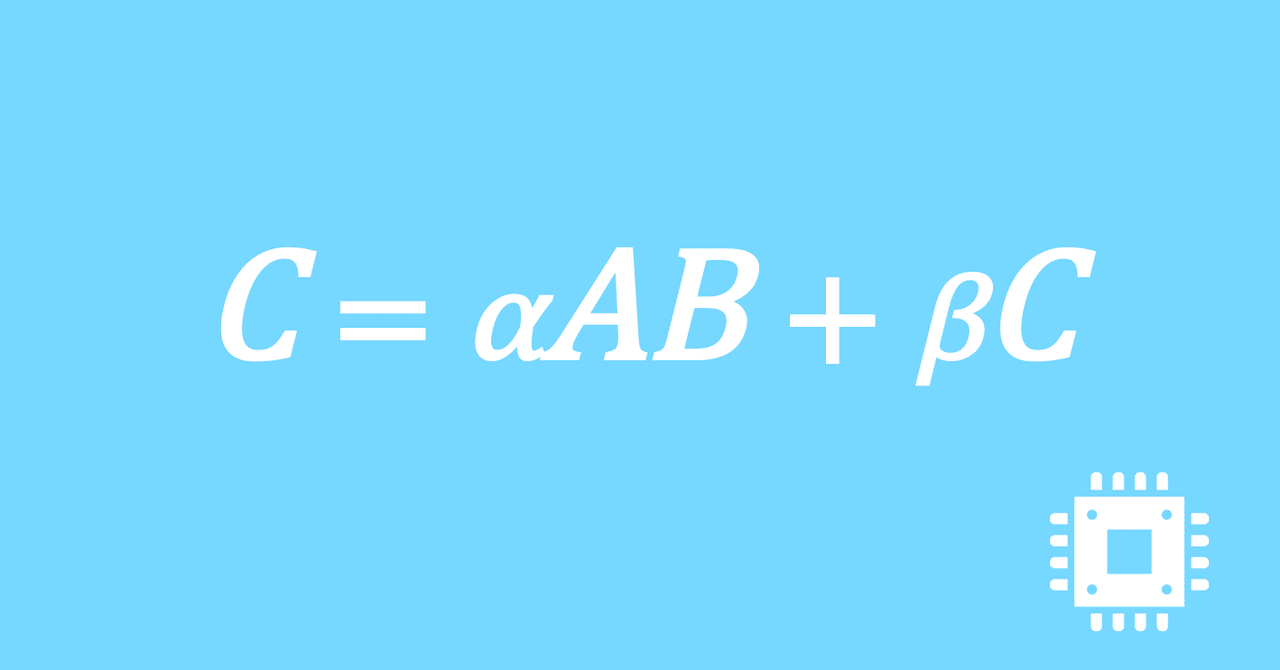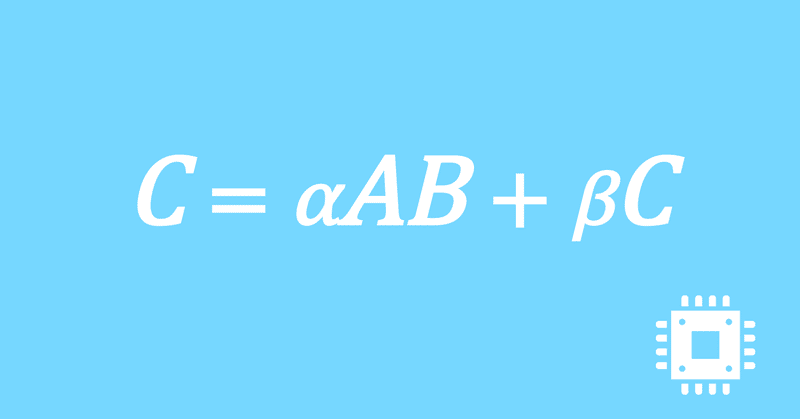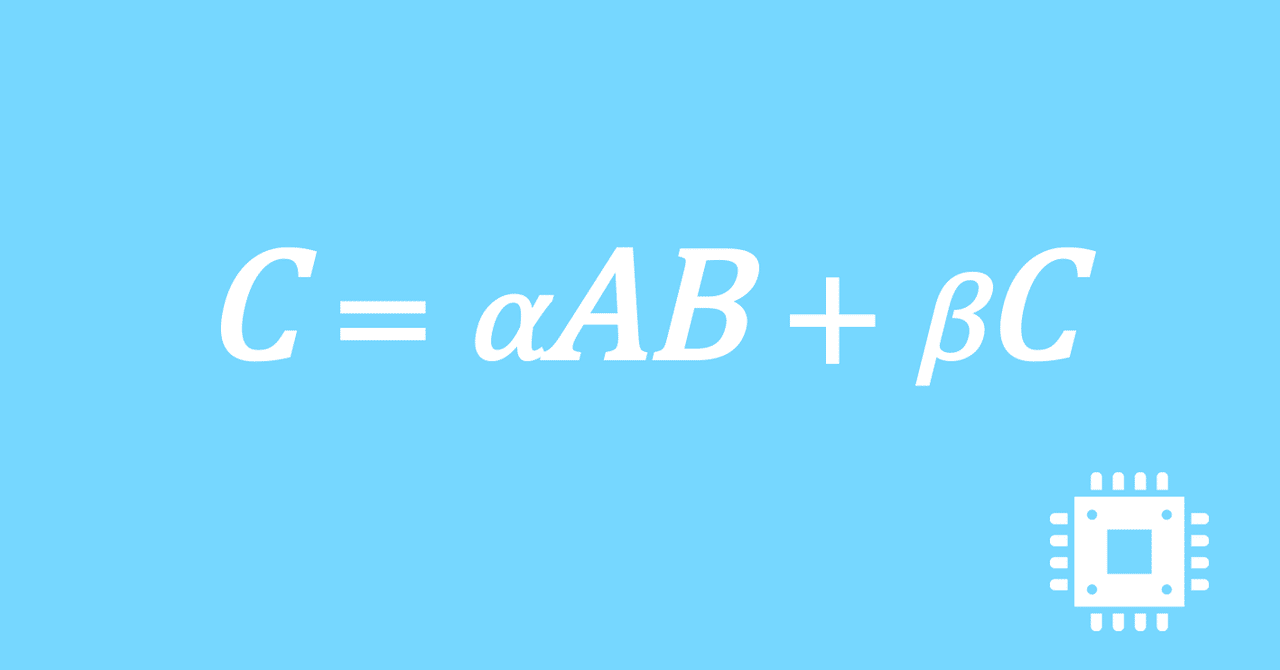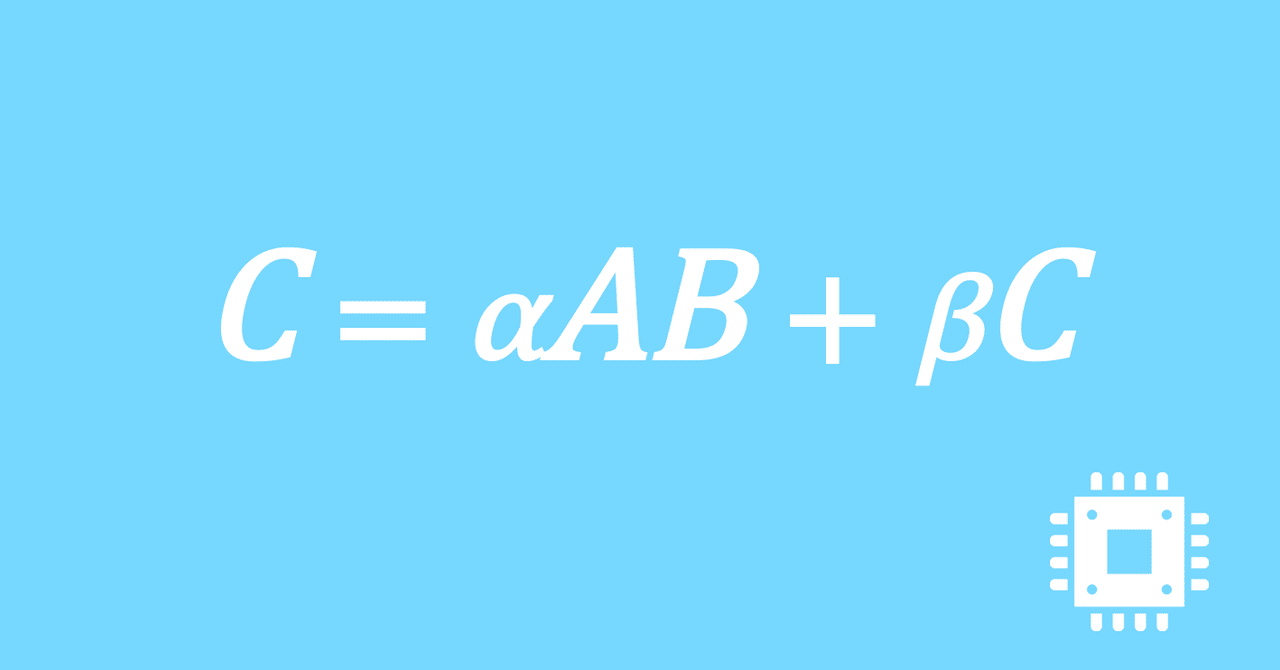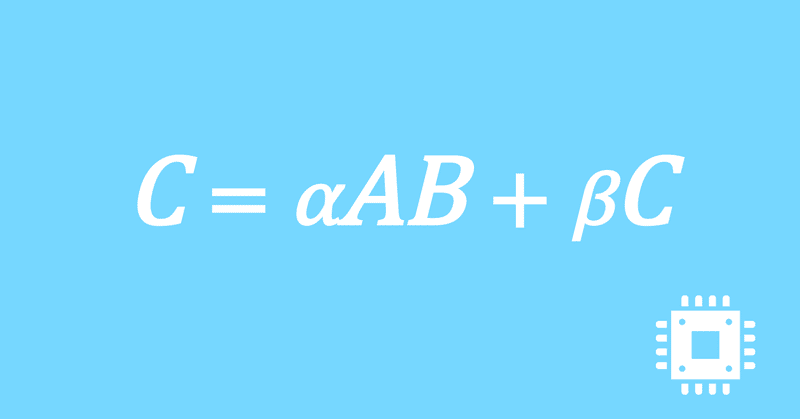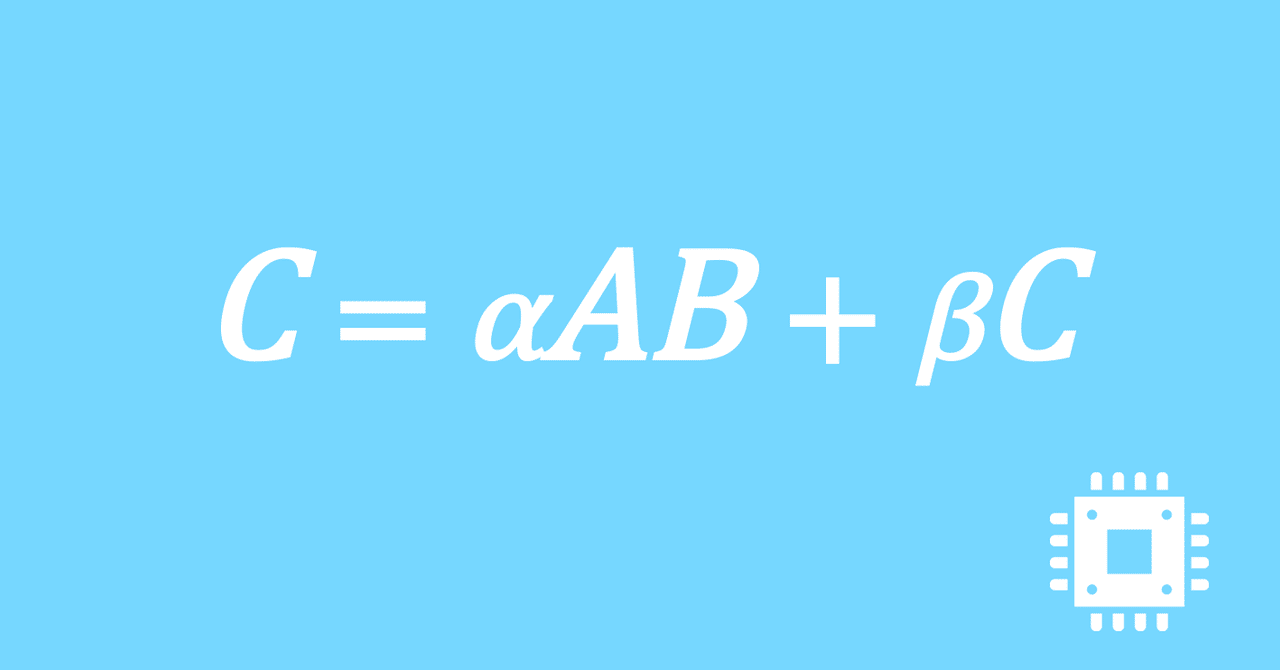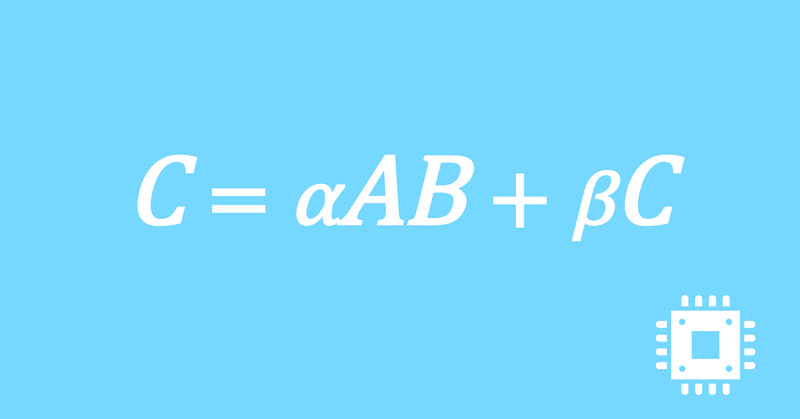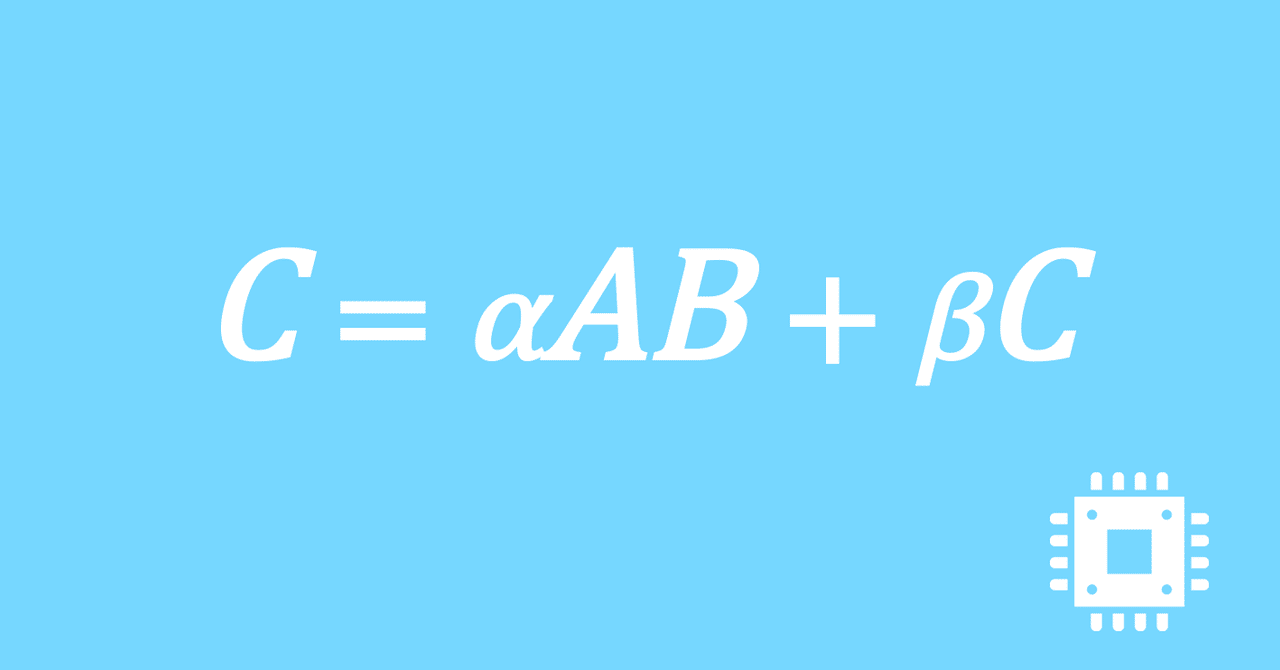やまもと
物理学博士/MBA。大手IT企業勤務する研究者です。最近は経営学や組織心理学の周辺を研究しています。
以前は、量子化学シミュレーション開発/HPCエンジニアをしていたので、その時に学習した技術を中心に書くつもりです。[FB] https://bit.ly/35ygatu
マガジン
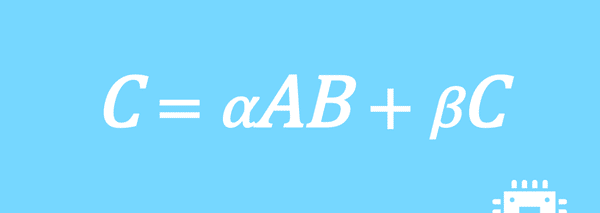
行列積計算を高速化してみた

やまもと
- 30本
数値計算ライブラリBLASに含まれる行列積ルーチンDGEMMを高速化していく手順を記した記事「行列積計算を高速化してみる」の章ごとに分割した記事をまとめたマガジンです。元の記事は20万文字以上になってしまったため、分割に踏み切りました。元記事が有料(560円)なので、分割した記事も一部有料(100円/記事)になっています。全記事を購入いただくと合計1000円になるため、元記事の方がお得になっています。

超高性能プログラミング技術のメモ
やまもと
- 15本
ハイパフォーマンスコンピューティング(HPC)で必要とされる高速なプログラムを書くための技術です。普通のプログラマーには、あまり必要ではありません。