
InsightX Transcribe Module(ビデオ通話から文字お越し)の進化

1.InsightX Transcribe System(ビデオ通話文字お越し)の進化
近年、ベクトル化や量子化技術を含むAI分野の急速な進展により、通話音声をテキスト化してコンタクトセンターの業務効率化や高度化を図るサービスモデルが国内外で多く誕生しています。
InsightXではもともと、心電図(ECG)や脳波(EEG)のEHRデータを解析する際、DOCMやHL7などのフォーマットでは十分な精度が得られないため、ベクトル規格であるM-FER(ISO/TS 11073-92001:2007、2015年に国際規格(IS) ISO 22077に準拠)を2009年から波形データの内部処理に使用してきました。ただし、「音声データをベクトル化することは可能か?」という課題については、当時、医療向けのデータセットが存在しなかったため、期待がありながらも実現には程遠い夢のような話でした。
しかし、InsightXが患者とのコミュニケーションで3Dアバターを利用したビデオ通話を目指した2020年、処理速度やデータ容量の問題が深刻化し、音声データのベクトル化が急務となりました。そんな中、2020年6月にFacebook AI(現Meta AI)が発表した音声認識フレームワーク「Wav2Vec 2.0: A Framework for Self-Supervised Learning of Speech Representations」に着目し、これを基盤に開発を開始する決断をしました。この時点では他の選択肢がなく、フレームワークの成果が未知数のまま、プロジェクトをスタートさせたのです。
具体的には、ビデオ通話の音声信号を直接入力として受け取り、文章や文脈表現を出力するEnd-to-Endモデルの設計に取り組み始めました。

2.膨大なマンパワーを使う文字起こし VS "Wav2Vec 2.0"
従来の音声認識では、音声データセットに文字起こしされたラベルを付けることが必須でした。この文字起こし作業は主に人力による手作業で行われており、高精度な音声認識モデルを構築するための大規模なデータセットを作成するには、莫大な労力と時間が必要とされてきました。
動画サイトで使用される自動字幕生成のように、音声から文字起こし(キャプション)を自動で生成する手法も存在します。しかし、医療アプリケーションの用途では、精度の課題が大きく、その結果、データセットとしての信頼性に不安が残るのが現状です。
こうした事情から、数千時間規模の文字起こし付き音声データを利用できる公開データセットは非常に限られ、医療向けとなるとゼロです。
昨日、ILUが日本語において最も多様なバリエーションやアセットを保有しているということでご相談させて頂きましたが、残念ながら医療アプリに適したデータセットはお持ちではありませんでした。

3.InsightX TranscribeでWav2Vec 2.0を選択した理由
Wav2Vec 2.0を選択した最大の理由は、「自己教師あり学習」と「オープンソース」である点です。具体的には、大規模な音声データセットによる事前学習済みのモデルを活用することで、用意する文字起こし付き音声データを最小限に抑えられる点が特徴です。また、自己教師あり学習を用いることで、ラベル付けされていない音声データ(つまり、ただの音声データ!)からでも学習を行うことが可能です。
Wav2Vec 2.0のフレームワークでは、まずラベルの付いていない大規模な音声データセットで自己教師あり学習を行い、次にラベル付き音声データを用いてファインチューニングを行うというのが一般的な手法です。このプロセスにより、患者個々の話し方や文節、さらには環境に適した音声認識システムを構築することが可能になります。

4.Wav2Vec 2.0で生成する音声バイオマーカーの可能性
音声データを活用した病気の検知や診断(音声バイオマーカーの利用)は、近年ヘルスケア分野で大きな注目を集めています。特に、特定の病気に関連する音声の特徴を機械学習モデルで解析し、早期診断や症状モニタリングに役立てる研究が、世界中で進められています。
声信号の時間-周波数特徴(例えば、メル周波数ケプストラム係数など)をベクトル化することで、以下のような病状の判別や予測が可能になります:
パーキンソン病: 初期症状として現れる音声の震え、単調さ、話す速度の低下、発音の不明瞭さなどを検出。
てんかん: 発作の直前や発作中に音声(息遣いや話し方)が変化する現象を観察・分析。
うつ病・不安障害: 声の高さ(ピッチ)、話す速度、抑揚の少なさなどを特徴として解析し、感情的な落ち込みや不安の程度を判定。
その他:心音で心疾患、呼吸音から肺疾患の有無など判別に役立つ可能性。
InsightXのような患者支援アプリケーションでは、これらのベクトル化音声バイオマーカーを取り入れることで、発作の予測や精神的ケアの質向上が期待されます。

5.InsightX Transcribeでのテスト実装
下の図に示すように、テストモデルのトレーニングは2つのフェーズで構成されています。
最初のフェーズは自己教師あり学習で、ラベルなしのデータを使用して実行され、可能な限り最適な音声表現を生成することを目的としています。このプロセスは単語埋め込み(word embedding)と似た考え方です。単語埋め込みも、自然言語の最適な表現を得ることを目指していますが、主な違いはWav2Vec 2.0がテキストではなく音声データを扱う点です。
2つ目のフェーズは教師あり微調整で、ラベル付きデータを使用してモデルに特定の単語や音素を予測させるように学習させます。なお、「音素」という言葉に馴染みがない場合は、特定の言語で通常1文字または2文字で表される、最小の音の単位と考えるとわかりやすいでしょう。

前述のように、このモデルの主な利点は、少量のラベル付きデータを使用しながら、自己学習によって非常に優れた音声表現を獲得し、最先端の結果を達成できる点です。
たとえば、巨大なLibriVoxデータセットを使用してモデルを事前トレーニングした後、LibriSpeechデータセット全体を微調整に使用したところ、test-cleanサブセットで1.8%の単語誤り率(WER)、test-otherサブセットで3.3%のWERを達成しました。さらに、使用するデータ量を約10分の1に減らしても、test-cleanで2.0%のWER、test-otherで4.0%という優れた結果を得ることができました。


6.InsightX Transcribeとしての実装
最終モデルのアーキテクチャは、次の 3 つの主要部分で構成されます。
生の波形入力を処理して潜在表現Zを取得する畳み込み層
トランスフォーマーレイヤー、文脈化された表現の作成 – C
出力Yへの線形投影

これが最終的な微調整後の実証モデルです。本番環境での開発準備が整いました。このモデルの「魔法」とも言える部分は、トレーニングの最初のフェーズである自己教師ありモードにあります。このフェーズでは、出力予測を生成する線形投影を使用せずにトレーニングが行われます。
InsightXにおける音声表現の主なアイデアは、Fig-4に示されている「コンテキスト表現C」に対応しています。事前トレーニングの基本的なコンセプトは、BERTと似た仕組みを採用しています。具体的には、トランスフォーマーモデルの入力の一部をマスクし、そのマスクされた潜在的な特徴ベクトル表現(z、t)を推測することを目的としています。ただし、このシンプルなアイデアに対照学習を組み込むことで、さらに改良を加えたモデルとなっています。

7.Contrastive LearningL(対照学習)
対照学習とは、入力データを2つの異なる方法で変換し、それらが同じオブジェクトであるかどうかをモデルが認識できるように訓練する概念です。
Wav2Vec 2.0において、1つ目の変換はトランスフォーマー層によって行われ、2つ目の変換は量子化によって実現されます(この量子化については後述で詳しく説明します)。
形式的には、マスクされた潜在表現z, tに対して、その正しい量子化表現 qtを、他の量子化表現の中から正確に推測できるようなコンテキスト表現 c, tを得ることを目指します。この内容を正確に理解することは重要です。必要であればここで一度立ち止まり、考え直してみてください。
自己教師あり学習に用いられるモデルの詳細な変形バージョンについては、Fig-4をご参照ください。


8.量子化(Quantization)
量子化とは、連続的な空間内の値を、離散的な空間内の有限個の値に変換する重要なプロセスです。
では、このプロセスを自動音声認識(ASR)にどのように実装できるでしょうか?
例えば、1つの潜在音声表現ベクトル z、t が2つの音素をカバーしていると仮定します。
言語内の音素の数は有限で、さらにすべての可能な音素の組み合わせの数も有限であるため、それらを同じ潜在音声表現で完全に表現することが可能になります。
加えて、それらの数も有限であるため、すべての可能な音素の組み合わせを含むコードブック(辞書)の作成も出来ます。そして、量子化とは、このコードブックから適切なコードワードを選ぶプロセスに還元されます。
しかし、すべての可能な音声の数を考えると、その総数は膨大であることが想像できます。この問題を解決し、学習と使用を容易にするために、今回のモデルでは G個のコードブック を作成しました。
各コードブックには V個のコードワード が含まれています。量子化された表現を作成するためには、それぞれのコードブックから最適なコードワードを選択します。
次に、選択されたベクトルを連結し、線形変換を適用することで量子化された表現がFig-5のように得られます。

これは分類タスクであるため、各コードブックから最適なコードワードを選択するには、ソフトマックス関数が自然な選択となります。では、なぜGumbelソフトマックスが通常のソフトマックスよりも優れているのでしょうか?これには、ランダム化と温度 τという2つの改善点があります。
ランダム化により、モデルはトレーニング中に異なるコードワードを選択し、その重みを更新する可能性が高くなります。特に、トレーニングの初期段階では、コードブックのサブセットのみを使用することを避けることが重要です。
温度は時間の経過とともに2から0.5に下げられるため、ランダム化の影響は次第に小さくなります。
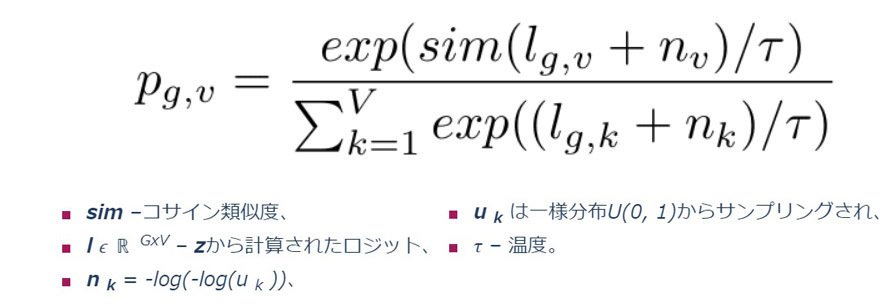

9.マスキング処理
マスキングは2つのハイパーパラメータ(p=0.065 および M=10)で定義され、次の手順で実行されます。
潜在音声表現 Z の空間から、すべての時間ステップを取得します。
前のステップからのベクトルの比率 p を使用して、置換せずにサンプリングします。
選択された時間ステップが開始インデックスとなります。
各インデックス ii に対して、連続する M 個の時間ステップがマスクされます。
次の図に示すように、開始インデックスとしてオレンジ色でマークされた2つのベクトルをサンプリングしました。

次に、選択された各ベクトルから始めて、M=10 個の連続した時間ステップがマスクされます。このスパンは重複する可能性があり、スパン間のギャップは3つの時間ステップに相当するため、最終的に14個の連続した時間ステップがマスクされます。

最後に、コントラスト損失はマスクの中央時間ステップに対してのみ計算されます。

10.トレーニング目標

トレーニングの目標は、対照損失と多様性損失という2つの損失関数の合計です。現時点では、対照損失についてのみ説明しています。
この損失関数は、K + 1 個の量子化候補表現q' ∈ Q tの中から正しい量子化表現q t を予測するようにモデルをトレーニングする役割を担います。セットQ t は、ターゲットq tと、他のマスク時間ステップから均一にサンプリングされたK個のディストラクタで構成されます。

文字 κ はトレーニング中に一定である温度です。Sim はコサイン類似度を表します。関数Lmの主要部分はソフトマックスに似ていますが、スコアの代わりにコンテキスト表現c tと量子化表現 q間のコサイン類似度を取ります。最適化を容易にするために、その分数に-logも付けます。
多様性損失は、正則化手法の一種です。著者らは、各コードブックにV =320 個のコード ワードを含むG =2 個のコードブックを設定しました。理論的には、320*320=102400 個の量子化表現が可能です。ただし、モデルが実際にこれらすべての可能性を使用するかどうかはわかりません。そうでない場合、たとえば各コードブックから 100 個のコード ワードを使用するように学習するだけで、コードブックの潜在能力全体が無駄になります。多様性損失が役立つのはそのためです。これはエントロピーに基づいており、次の式で計算できます。

エントロピーは、データ分布が均一なときに最大値をとります。この場合、すべてのコードワードが同じ頻度で使用されていることを意味します。これにより、トレーニング例のバッチ全体にわたってすべてのコードブックのエントロピーを計算し、コードワードが同じ頻度で使用されているかどうかを確認できます。このエントロピーを最大化すると、モデルがすべてのコードワードを活用するようになります。最大化は、多様性損失である負のエントロピーの最小化に相当します。
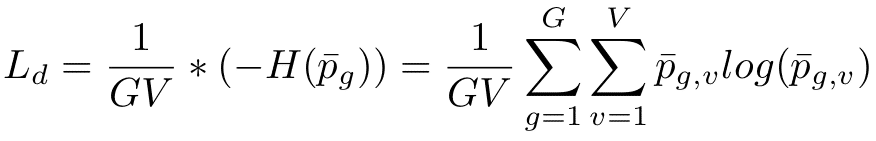

11.最終微調整
Wav2Vec 2.0 の微調整フェーズには特筆すべき発見はないため、オリジナル論文ではこの部分にあまり注目していません。故にトレーニング段階では、量子化は使用されません。
その代わりに、ランダムに初期化された線形投影レイヤーがコンテキスト表現 CCC の上に追加されます。次に、モデルは標準的なコネクショニスト時間分類(CTC)損失と、この記事の範囲外であるSpecAugmentの修正バージョンを使用して微調整されます。興味深いことに、著者らはマスキングを放棄しませんでした。マスキングは依然として正規化手法として有効に機能するためです。

12.まとめ
Wav2Vec 2.0 は、対照学習の考え方に基づいた自動音声認識の自己教師ありトレーニングアプローチを使用します。膨大な未加工(ラベルなし)のデータセットで音声表現を学習することで、満足のいく結果を得るために必要なラベル付きデータの量を削減することができます。
この記事の主なポイント:
Wav2Vec 2.0 は自己教師あり学習を活用して日本語処理にも十分応用が出来るとおもいます。
畳み込み層を使用して生の波形を前処理し、その後トランスフォーマーを適用して、コンテキストに応じた音声表現を強化します。
その目的は、2つの損失関数の加重和を最小化することです:
対照損失
多様性損失
量子化は、自己教師あり学習においてターゲットを作成するために使用されます。

13.余談
国内でWav2Vec 2.0を使用して小規模モデルを実践したい場合、自己教師あり学習に必要な音声ファイルの入手に関して、いくつか注意が必要です。LibriVoxは日本語版の蔵書数が少ないため、実用的ではありません。一方で、Amazon系のAudibleは、昨年10月時点で2万冊以上の蔵書があります。AudibleをAmazonで契約し、少し工夫することで音声データを利用する方法や、AWS Transcribeを活用する方法が考えられます。
【おすすめのデータセット】
MozillaのCommon Voice:無料で約3.5万件、総時間約4,000時間分のMP3フォーマットのデータセットの入手が可能です。(利用して良かったら寄付も忘れずにお願いします)↓↓↓↓↓↓↓
小規模なモデルであれば、訪問ケアなどの用途にも活用可能です。ただし、プライバシー保護を最優先に考える必要があり、セキュリティ対策がアプリ制作コストの3/4を占める場合もあります。そのため、慎重な検討が求められます。
また、AWSのサービスには医療に特化したAmazon Transcribe Medicalもありますが、日本語対応がまだ不十分で、残念ながら現時点では実用的ではありません。
14.参考文献
[1] Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli. (20th Jun 2020). wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. CoRR, abs/2006.11477. https://arxiv.org/pdf/2006.11477.pdf
[2] Aerin Kim. (30th Sep 2018). The intuition behind Shannon’s Entropy. Towards Data Science. https://towardsdatascience.com/the-intuition-behind-shannons-entropy-e74820fe9800
[3] Entropy (information theory). Wikipedia. https://en.wikipedia.org/wiki/Entropy_(information_theory)
[4] Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. https://arxiv.org/abs/1810.04805
[5] Speech Recognition on LibriSpeech test-clean. Papers With Code. https://paperswithcode.com/sota/speech-recognition-on-librispeech-test-clean
※このプロジェクトは、スマート グロース運用プログラムの一環として、欧州地域開発基金の下にある欧州連合の資金から共同出資を受けています。
いいなと思ったら応援しよう!
