【Power BI】学研まんがを66冊読んでデータ分析してみた

はじめに
学研のまんがでよくわかるシリーズを読んで勝手に評点をつける、という趣味を1年くらい続けています。
データが溜まってきたので、今まで読んだ66冊分のデータをPower BIで分析してみようと思い立ちました。66冊というキリがいいのか悪いのかわからないタイミングに意味はなく、Power BIを使って分析をアウトプットしたい欲求が強くなっただけです。
作成過程の説明がだいぶ長くなってしまったので、作成過程はいいから完成品が見たいって方は目次から「完成品」へどうぞ。
最終イメージ
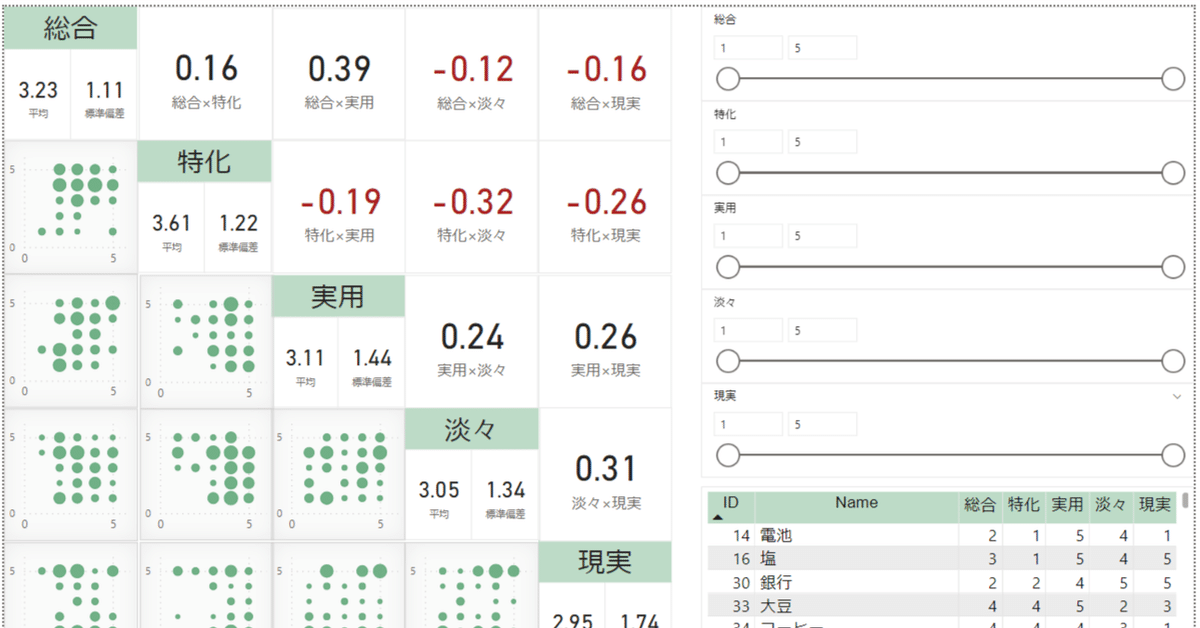
最終的なできあがりのイメージは、5つの評価軸を使った散布図行列です。こういうの。

表の右上側には、相関係数を記載しましょう。上図では、左上から右下のラインを中心に、X軸・Y軸を反転させた散布図を記載していますね。
各グラフには、散布図ではなくバブルチャートを使います。学研まんがの評点は1~5の5段階しかありません。2つの評点を組み合わせて取りうる値が5×5=25個しかなく、同じポイントに複数の点が重なりますが、散布図では重なりを表現できないため。バブルチャートを使うことで、バブルのサイズで3つ目の要素=点の重なりを表現できます。

評価軸は下記の5つ。[角カッコ]が分析時の列名になります。
総合[総合]:読んでほしいほど高い
テーマ[特化]:特化しているほど高い
実用性[実用]:生活に役立ちそうなほど高い
ストーリー[淡々]:物語が淡々としているほど高い
ファンタジー[現実]:物語が現実的なほど高い
ファンタジーじゃないほどファンタジー評点が高くなるという設計ミスがありますが、今さら修正できないのでそのままです…
データ準備
データ読み込み
今まで読んだ学研まんがの評価データは、すべてNotionにまとめてあります。Notionを使い始める前に読んだ分も、noteの投稿からNotionに転記してあります。育休中にやってました。

NotionのデータベースをPower BIのソースにすることはできません。CSVファイル経由で取り込みます。
Power Platformを駆使すれば自動化可能ですが、技術力不足でいったん断念。Power AutomateのNotionコネクタを使ってデータベースを取得するところまではできたんですが、そのJSONデータから各プロパティを抜いてくるのがうまくいかず…
Notionのエクスポート機能を利用すると、データをCSVファイルに出力できます。



CSVファイルを、Power BI Desktopで読み込みます。


データ整形
Power Queryを使って、データを整形していきます。左ペインからデータビューに切り替えて、データの変換をクリック。


データ整形した箇所は、下記の6点です。DAX式に倣って、列名を[角カッコ]で囲んで表記しています。
[NO.]列の名前を[ID]に変更する
[各評点]の列名から「a.」「b.」などの文字列を削除する
[ID], [Name], [各評点]以外の列を削除する
[ID], [各評点]を整数型に、[Name]をテキスト型に変更する
[Name]から「のひみつ」の文字列を削除する(置換)
[総合]がnullの行を削除する
太字で表記したところは、データ整形をしないとこのあとの視覚化に影響がありそうな箇所です。[ID], [各評点]は、数値の型にすることで、平均値や標準偏差などの計算ができるようになります。[総合]がnullの行は、読みたいと思ってNotionに記載したけどまだ読んでいないもの、つまり未評価なので、データ分析からは除外します。
型の変更ボタンやフィルターをクリックするなど、ノーコードでひととおりのデータ整形ができます。ノーコードでありながら、画像中央やや上あたりにコードっぽいモノ(M言語)が書かれているのが見えますね。M言語をバリバリ使いこなせれば、複雑な処理を実装したり、処理の合理化ができたりするようです。

Power Queryで「閉じて適用」を押すと、Power BIのデータビューにも反映されます。これでようやくデータの下準備ができました。

メジャー作成
Power BIでは、元データから計算した「メジャー」を作成し、分析に利用することができます。今回は2種類のメジャーを作成しました。
2つの評点の組み合わせ
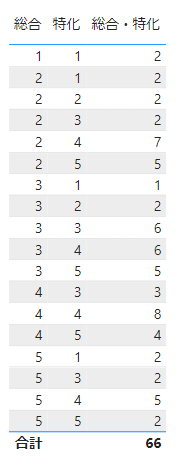
散布図のビジュアルのサイズ欄に量的データを入れることで、バブルチャートとして表示することができます。今回サイズ欄に入れるのは、2つの評点の組み合わせてそれが出現する回数を示すデータです。現状ではそのデータを持つ列がないので、メジャーを作成しましょう。
総合・特化 =
COUNTX('学研まんが_notion_20230814',
CONCATENATE([総合], [特化]))DAX式のCONCATENATE関数・COUNTX関数を使って、総合・特化メジャーを作成しました。CONCATENATE関数で総合列と特化列を連結して、21、35などの値を生成します。そして、その値がいくつ出現するかをCOUNTX関数でカウントしています。COUNTX関数は、ExcelにおけるCOUNTIF関数みたいなものですね。
総合・特化メジャーを作成したことで、総合と特化の各組み合わせがいくつ出現するかをデータ化することができました。他の組み合わせについても同じように作成してあります。
2つの評点の相関係数
2つの評点の相関係数も、メジャーを作成する必要があります。相関係数を計算するDAX関数は存在しないため、クイックメジャーで先人の知恵を借りました。使い方、合ってるかな…


ビジュアル作成
データの準備ができたら、グラフを作成していきます。Power BIでは、各種グラフのことをビジュアル(視覚化)と呼んでいます。ビジュアルを集めたものがレポートで、ページはExcelのシートみたいなものです。

バブルチャート
まずはバブルチャートをひとつ作ってみます。Power BIでのバブルチャートは、散布図のバリエーションのひとつとして扱われているので、視覚化ペインで散布図を選択。X軸・Y軸・サイズにデータを設定します。バブルが表示域からはみ出さないように、各軸は最小値0・最大値6で設定しています。

見た目を整えたら、5項目の組み合わせ=10パターン分のバブルチャートをコピペで作成していきます。スペースの都合上、各バブルチャートはかなり小さくなってしまうので、余計な情報を削ぎ落とす必要があります。

カード
全体の対称軸(左上から右下)には、項目名と、平均・標準偏差を列記します。また、全体の右上側には項目同士の相関係数を表示します。単一の数値を表示する場合に使うのは、カードの視覚化。せっせとコピペして並べて、を繰り返していきます。

相関係数が負の値の場合、テキストの色を赤に変更しました。Excelの条件付き書式のような設定です。基準にするフィールドは、各カードごとに変更する必要があります。

その他
ページの右の方が空いているので、スライサーとテーブルを追加しました。スライサーがあることで、総合が5のものに絞って調べる、などの分析が可能。テーブルは、具体的なデータを確認するときに便利です。

完成品
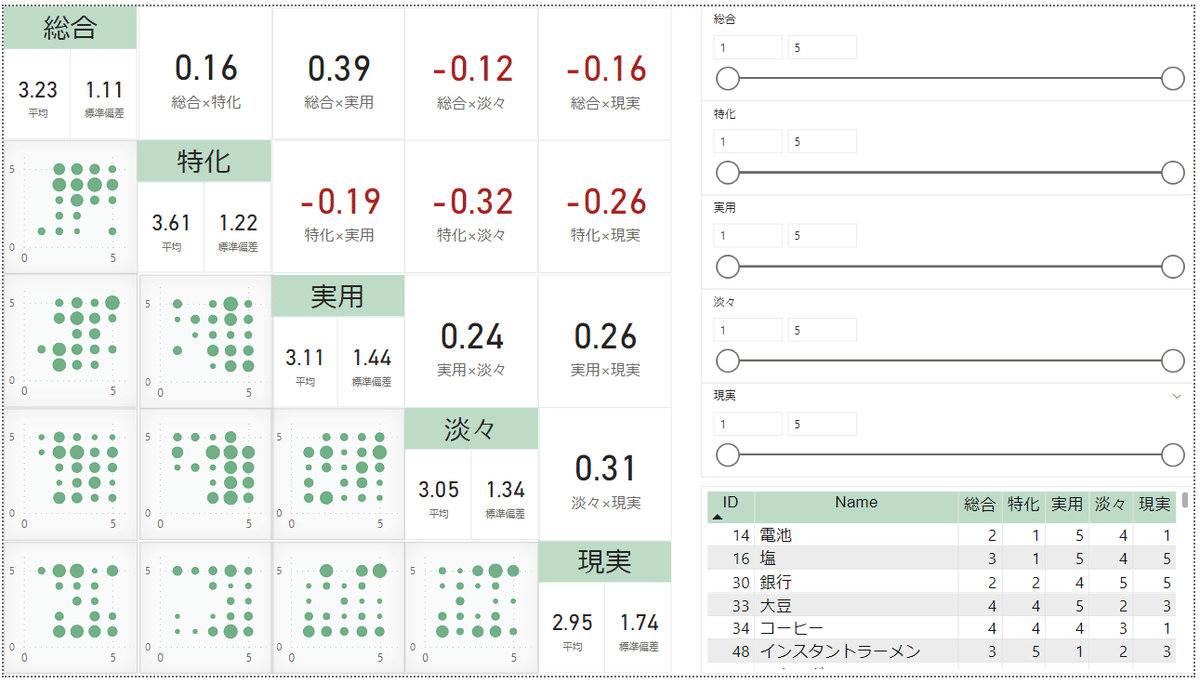
学研まんがの評点データをレポート1枚にまとめることができました。空いてたから入れただけの右下のテーブルが結構便利。フィルターやソートも効くので、データを簡単に確認することができます。
一方、メインであるはずのバブルチャートが思っていたより仕事してない感じがしますね… 数値で確認できる相関係数の方がわかりやすいです。バブルチャートで傾向を観察するには、データが不足しているor5段階では狭すぎるのかもしれません。
評点の組み合わせの相関係数について考察
評点の組み合わせ10個のうち、強い相関係数を示している3個について考察してみました。
総合×実用(正の相関 0.39):実用性が高い作品ほど、総合評価が高い傾向にあります。生活に役立ちそうなほど、読後の満足感が高いと言えます。
特化×淡々(負の相関 -0.32):テーマが汎用的だと、様々な説明にページを割く必要があり、ストーリー展開にかけられるページが減ると考えられます。
淡々×現実(正の相関 0.31):ファンタジーモノの場合、タイムリープして歴史上の人物に会ったり、妖精との出会いや別れが描かれたりするため、ストーリーが起伏に富んだものになると考えられます。
総合5の作品の傾向

スライサーを使えば、各評点でフィルターして分析することも簡単です。上図は、総合評価が5のものをフィルターして表示したものです。総合5の傾向としては、実用寄り(平均が4.27と高め)で、現実かファンタジーのどちらかに振り切っている(現実5と現実1に集中している)ものが多いようですね。
おわりに
データの準備に手こずりました。CONCATENATE関数で連結するとか、クイックメジャーで相関係数を作るとか、もっと使い慣れないと自信が持てないですね。修業あるのみ。
データ分析って、仮説を立てるのと、データ準備とで8割くらい占めてる印象です。今回はビジュアル作りでも試行錯誤してましたが、やはり準備が大切。
評価に影響を与えていそうな項目は他にも挙げられます。ID以外はデータを取っていないので、これらが強い影響を与えていると考えるなら、ちゃんとデータを取る必要があります。
出版年月日(ID):新しい作品ほど、SDGsの推しが強い傾向
構成:ウェルテ作品はハズレがない
絵師:好みは多少ある
ページ数:一部の特別編は短編扱い
散布図行列を作りたいときは、Rを使う方が簡単そう。10月からの「社会人のためのデータサイエンス演習」でRを学ぶ予定なので、学研まんが分析R版も作るかもしれません。
#図解 #読書 #書評 #最近の学び #PowerBI #PowerPlatform #Notion #データ #データ分析 #分析 #データサイエンス #散布図 #散布図行列 #相関 #学研 #学研まんが
いいなと思ったら応援しよう!
