[Unity]多言語対応のフォント準備(Unicode領域の調査)

はじめに
Unityのゲームを多言語対応させる際に、各言語のフォントアセットをTextMeshProの標準ツール(フォントアセットクリエイター)で用意する必要がある。
フォントアセットクリエイターでフォントアセットを生成する際には、Character setを入力する必要があるのだが(添付赤枠部)、何を入力すればいいのかわからなかった。
今回はChatGPTを通して、各言語のCharacter setの入力内容(Unicode領域)を調べたので、記事にまとめた。
※また、アラビア語とウルドゥー語については注意が必要のため、必ず記事を最後まで読むこと。
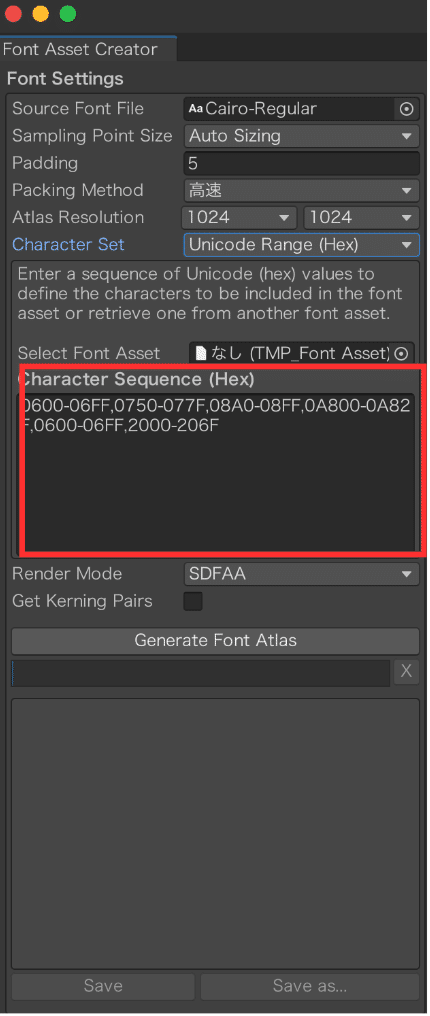
対象言語
対象言語は世界の使用人数Top10の言語(英語、中国語、ヒンディー語、スペイン語、フランス語、アラビア語、ベンガル語、ポルトガル語、ロシア語、ウルドゥー語)(下記リンク参照)+隣国の韓国語を対象とする。
各言語のUnicode領域
英語
0000-007F,0080-00FF,2000 - 206F参考:ChatGPT-3
中国語
4E00-9FBF参考:リンク
ヒンディー語
0900-097F,A8E0-A8FF,11B00-11B5F参考:ChatGPT-3
スペイン語
0000-007F,0080-00FF,0100-017F,1E00-1EFF,2000-206F参考:ChatGPT-3
フランス語
0000-007F,0080-00FF,0100-017F,1E00-1EFF,2000-206F参考:ChatGPT-3
アラビア語
0600-06FF,08A0-08FF,0600-06FF,1EE00-1EEFF,2000-206F参考:ChatGPT-3
ベンガル語
0980-09FF,A830-A83F,2000-206F参考:ChatGPT-3
ポルトガル語
0000-007F,0080-00FF,0100-017F,1E00-1EFF,2000-206F参考:ChatGPT-3
ロシア語
0400-04FF,0500-052F,2DE0-2DFF,A640-A69F,1C80-1C8F,2000-206F参考:ChatGPT-3
ウルドゥー語
0600-06FF,0750-077F,08A0-08FF,0A800-0A82F,0600-06FF,2000-206F参考:ChatGPT-3
韓国語
1100-115E,1161-11F0,3131-318E,AC00-D7A3,A960-A97C,D7B0-D7C6,D7CB-D7FB参考:リンク
注意点(アラビア語、ウルドゥー語)
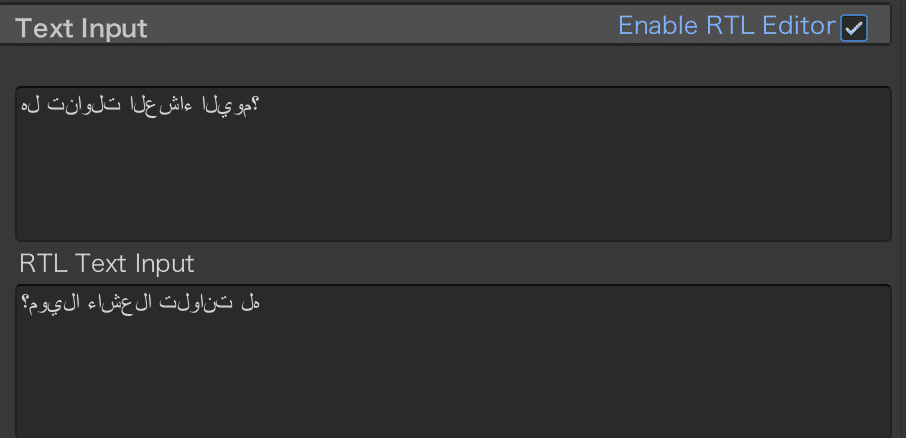
アラビア語とウルドゥー語については他の言語と違い、右から左に文字を羅列する言語であり、Unityエディターに貼り付ける段階で、左右反転してしまう。結論としては、TMP_Text>Text Input>Enable RTL Editorにチェックを入れると解決する。
例えば、「今日ごはん食べたっけ?」という日本語をアラビア語に翻訳すると、「هل تناولت العشاء اليوم؟」というように翻訳される。
一つ一つの単語の意味は理解不能だが、?マークが左端に表示されていることだけは理解できる。
google翻訳等では右から左に羅列しているのだが、これをコピーしてunityのTMP_Text内に貼り付けると、文字の羅列が左右反転してしまう。
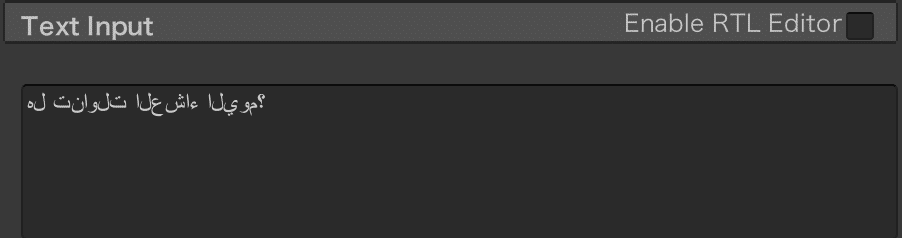
(本来左端にあるはずの?が右端に表示される)

そこで、添付画像のEnable RTL Editorにチェックを入れると、ちゃんと右から左に文字が羅列するようになる。
おわり
今回11言語のUnicode領域について調査した。日本の記事では、日本語、中国語、韓国語のUnicode領域は簡単に調べられたが、その他の言語については網羅されていなかったので、この記事が他のゲーム開発者方の一助となれば幸いです。
また、ここはこうした方が良いといったコメントがあれば、お手数おかけいたしますが、コメントよろしくお願いいたします。
あとX(旧Twitter)やってます。フォローしていただけると嬉しいです。
https://x.com/Zaki_san208/status/1824643452300333484