

2023年9月の記事一覧


LangChainでストリーミングを有効にしつつ、会話やRAGのトークン消費数を計測する方法
はじめにこんにちは、@_mkazutakaと申します。今日は、LangChainでストリーミングを有効にしつつ、会話やRAGのトークン消費数を計測する方法について紹介します。
LangChainを使用するときのトークン消費量は、以下のドキュメントに記載されているように `get_openai_callback` 関数を利用すれば簡単に取得できます。しかしこれには注意点があり、この関数はストリーミ


RAGの解説: LLMとベクトルデータベースを活用したアプローチのまとめ
Retrieval Augmented Generation(RAG)は、AIと特に大規模言語モデル(LLM)の分野で注目されている新しい技術です。この記事では、RAGが何であり、どのようにLLMの性能を高めるのか、具体的な実用例とともに解説します。ベクトルデータベースの活用方法や、RAGを実装する際のポイントも紹介します。
1. Retrieval Augmented Generation(R


独自知識を組み込んだチャットボットを作る - OpenAI + Llamaindex + Gradioで遊んでみる
データミックスの代表の堅田です。シルバーウィークの1日を使って、気になっていたLlamaindexとGradioを触ってみました。
注意
できるだけ平易な言葉で、かつ技術ワードを避けながら記載しています。その結果、厳密性に欠いた説明になっている部分もありますが、ご容赦ください。
いずれのライブラリ・サービスも記事作成時点のものです。それらがアップデートされることで、記載したコードが動かない、


RAG評価ツール ragas を試す
RAG評価ツール「ragas」を試したので、まとめました。
1. ragas「ragas」は、「RAG」 (Retrieval Augmented Generation) パイプラインを評価するためのフレームワークです。「RAG」は外部データを使用してLLMのコンテキストを拡張するLLMアプリケーションです。「ragas」はこのパイプラインを評価して、パフォーマンスを定量化します。
2. Co
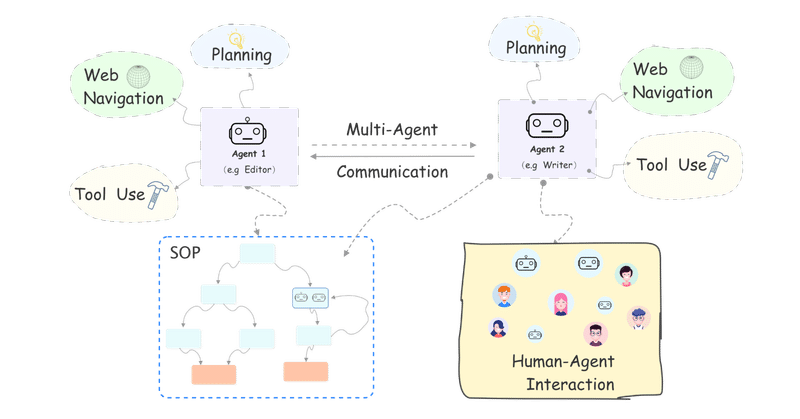
自律言語エージェントを構築するためのフレームワーク Agents を試す
自律言語エージェントを構築するためのフレームワーク「Agents」を試してみたので、まとめました。
1. Agents の概要「Agents」は、自律言語エージェントを構築するためのフレームワークです。
「コンフィグファイル」に自然言語で設定を記述するだけで、「言語エージェント」または「マルチエージェントシステム」をカスタマイズし、「ターミナル」「Gradio」「バックエンドサービス」にデプロ

【勉強メモ】RAG を使用したチャットボット: LangChain の完全なチュートリアル Chatbots with RAG: LangChain Full Walkthrough
Chatbots with RAG: LangChain Full Walkthrough(GPTにて要約)要約
このビデオでは、開始から終了まで、リトリーバル拡張生成(RAG)を使用してチャットボットを構築する方法が詳しく説明されています。このビデオでは、チャットボットの構築について何も知識がないと仮定し、OpenAIのGPT 3.5モデルとLangChainライブラリを使用して、新しいイベン

Google Colab で DeepSpeed によるLLMのフルパラメータの指示チューニングを試す
「Google Colab」で「DeepSpeed」によるLLMの (LoRAではなく) フルパラメータの指示チューニング (Instruction Tuning) を試したので、まとめました。
前回
1. DeepSpeed「DeepSpeed」は、深層学習モデルの学習や推論の処理を高速かつメモリ消費を抑えて実現することができるライブラリです。
HuggingFaceでサポートしている「De
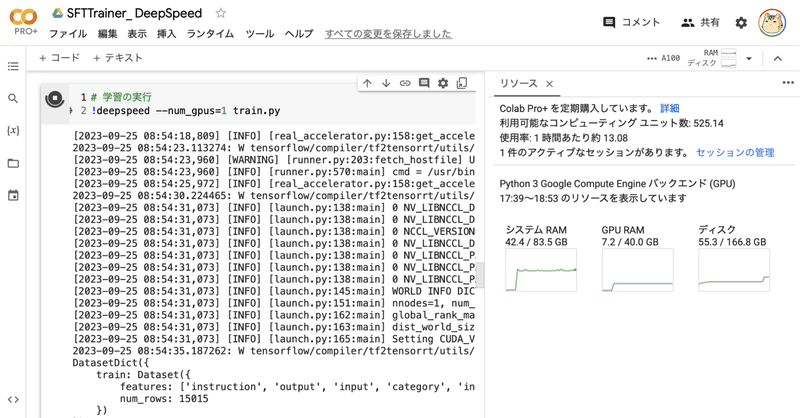
Google Colab で SFTTrainer によるLLMのフルパラメータの指示チューニングを試す
「Google Colab」で「SFTTrainer」によるLLMの (LoRAではなく) フルパラメータの指示チューニング (Instruction Tuning) を試したので、まとめました。
前回
1. モデルとデータセット今回は、LLMとして「OpenCALM-small」、データセットとして「databricks-dolly-15k-ja」を使いました。
2. ファインチューニング前

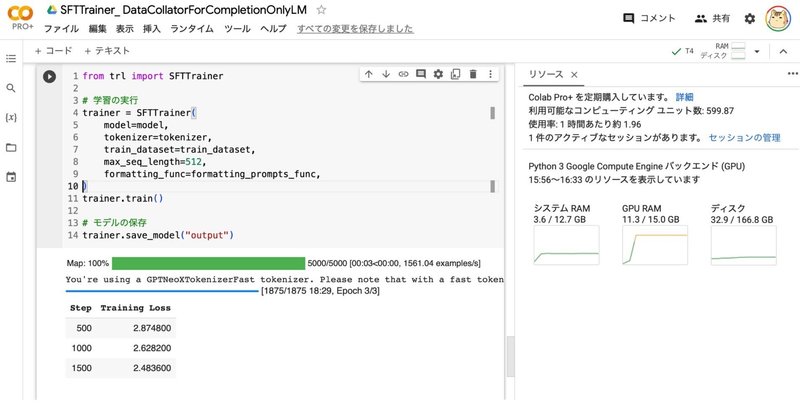
Google Colab で SFTTrainer によるLLMのフルパラメータのファインチューニングを試す
「Google Colab」で「SFTTrainer」によるLLMの (LoRAではなく) フルパラメータのファインチューニングを試したので、まとめました。
1. SFTTrainer「SFTTrainer」は、LLMを「教師ありファインチューニング」 (SFT : Supervised Fine Tuning) で学習するためのトレーナーです。LLMの学習フレームワーク「trl」で提供されてい

Text generation web UI で Xwin-LM-13B-V0.1-GPTQ を試す。
「Text generation web UI」で「Xwin-LM-13B-V0.1-GPTQ」を試したので、まとめました。
1. Xwin-LM-13B-V0.1-GPTQnpaka 大先生が Google Colab で Xwin-LM を動かしていたので、私はローカルの Text generation web UI で Xwin-LM を動かしてみるチャレンジです。
shi3z さんは
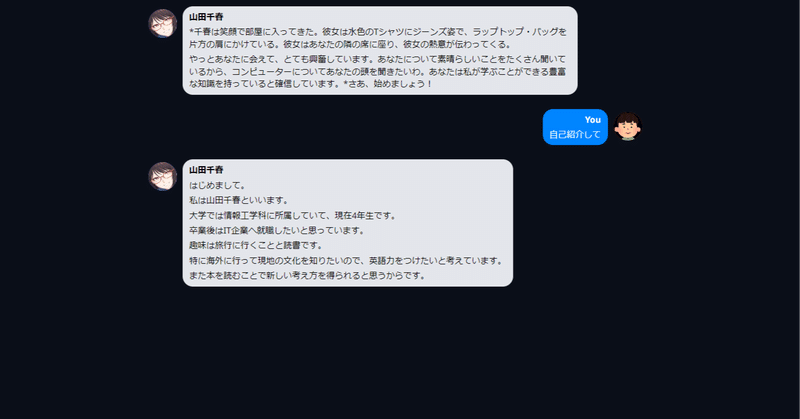
text-generation-webuiでELYZA-japanese-Llama-2-7b-fast-instructとのチャットを考える
text-generation-webuiにはデフォルトでChiharu Yamadaという謎の美少女とチャットできるプリセットが搭載されています
ModeをChatにすると、LLMにはどのようなプロンプトが渡っているのでしょうか。
左下のハンバーガーメニューから「send to default」または「send to notebook」を選ぶと、実際にLLMに渡っているプロンプトを確認するこ

text-generation-webuiで、ELYZA-japanese-Llama-2-7n-fast-instructをExLlamaでロードし、LoRA適用してみる
text-generation-webuiで、ELYZA-japanese-Llama-2-7n-fast-instructをExLlamaでロードし、LoRA適用してみます。
Exllamaでモデルをロードするために、以下のGPTQモデルをお借りします。
Download model or LoRA画面にdahara1/ELYZA-japanese-Llama-2-7b-fast-instr