

2023年12月の記事一覧


WebCAM画像をキャプチャしてキャラ絵にリアルタイム変換-StreamDiffusionの凄さ
StreamDiffusionは爆速で画像生成ができることが驚異的ですが、この生成速度の速さ故に、今までとは違う可能性が広がります。今回はPCのWebカメラでキャプチャーした画像をリアルタイムで自分キャラに変換して、なりきることに挑戦しました。
StreamDiffusionリポジトリのメインに有るi2iのコードを改良して実現しています。
環境構築以下の記事で簡単に説明しています。基本的なi2


好きなキャラに別世界のコスプレを!【StableDiffusion】【複数LoRA】
株式会社Rossoのteam AIデータ分析チームです
最近、私は「Stable Diffusion」ばかりやっています。
「Stable Diffusion」は「LoRA」という追加学習モデルを使用することで、特定のキャラクターに特化した画像生成を可能にします。絵を描くことが得意ではない私にとって、この技術は二次創作のための理想的なツールとなっています。
このブログでは、お気に入りのキャラク


diffusersのアダプタ まとめ
以下の記事が面白かったので、かるくまとめました。
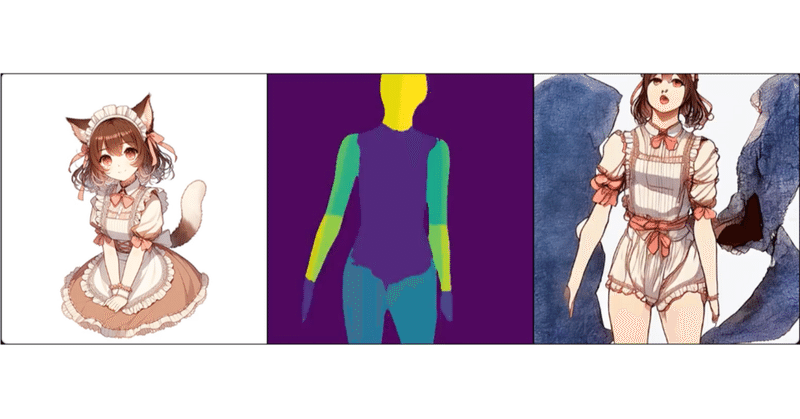
1. diffusersのアダプタ画像生成モデルをパーソナライズして、特定の被写体の画像のスタイルの画像を生成するための学習手法がいくつかあります。
これらの学習方法ごとに、「diffusers」では異なるタイプの「アダプタ」を提供しています。「アダプタ」は、そのモデルが生成する画像のスタイルや特性を調整するための追加的なコンポーネントを指しま


TensorArtの使い方
TensorArtを初めて使う人向けの簡単な解説です
①TensorArtとはhttps://tensor.art/
一言で言えば Stable Diffusion(以後SD) のWEBサービス版
SDとほぼ同じものが生成できます
ControlNet やLoRAも使えます
画像比較
実際のサービス内容
基本無料で使えます
毎日無料で作れる枚数
低画質100枚以上 高画質60枚以上

diffusers で LoRA を試す
「diffusers」で「LoRA」を試したので、まとめました。
1. LoRA「LoRA」(Low-Rank Adaptation)は、AIモデルの効率的な調整やカスタマイズのための手法です。手法は、モデルの重みを直接調整するのではなく、低ランク(小さい次元)の行列を用いてモデルの一部の重みを調整することにより、モデルの振る舞いを変更します。
この手法には、多くの利点があります。
「LoR

Google Colab で Stable Video Diffusion を試す
「Google Colab」で「Stable Video Diffusion」を試したのでまとめました。
1. Stable Video Diffusion「Stable Video Diffusion」は、「Stability AI」が開発した画像から動画を生成するAIモデルです。解像度 1024x572 で、14フレーム (2秒) または25フレーム (4秒) の動画を生成します。
2.

diffusers で ControNet の inpaint を試す
「diffusers」で「ControNet」の「inpaint」を試したので、まとめました。
1. ControlNet の inpaint「inpaint」は、画像の一部をマスクして、任意の領域のみ新しい画像を生成させることができる機能です。
2. Colabでの実行「ControlNet」で「inpaint」を行う手順は、次のとおりです。
(1) パッケージのインストール。
# パッ
Google Colab で Stable Diffusion WebUI を試す
「Google Colab」で「Stable Diffusion WebUI」を試したので、まとめました。
1. Stable Diffusion WebUI「Stable Diffusion WebUI」は、「Stable Diffusion」で画像生成するためのWebUIです。
2. Colabでの実行Colabでの実行手順は、次のとおりです。
(1) Colabのノートブックを開き、メ
Google Clolab で Magic Animate を試す
「Google Clolab」で「Magic Animate」を試したので、まとめました。
1. Magic Animate「Magic Animate」は、TikTok運営のByteDance等がリリースした、参照画像と一連のモーションから動画を生成する動画生成モデルです。
2. Colabでの実行Colabでの実行手順は、次のとおりです。
(1) パッケージのインストール。
!git


【Stable Diffusion】自作「LoRA」、反映度と学習回数について【Kohya’s GUI】
■記事の対象ユーザ
1.Stable Diffusion WebUIをローカルに構築して、イラスト生成しはじめた
2.自作LoRAを作ってみたが、どうも上手いこと反映されていない気がする
■ようするに?
作ってはみたけど1.自作の3DモデルからStableDiifusionを使い好みの画像を作成
オリジナルキャラを学習させるべく、ベースとなる3Dモデルを作成し、プロンプトとControl

LCM-LoRAについて
学習や生成をいろいろ試して分かったことをまとめます。
LCM-LoRAとは ただのLoRAです。サンプラーが変わったりCFG_scaleが1に近い値を設定しないといけなかったりとちょっと特殊ですが、結局LoRAであることは変わりません。
サンプラーについてLCMサンプラーは意外と直感的に理解できます。Euler ancestralの究極版みたいな感じです。
以下は1ステップ分の図です。左の完
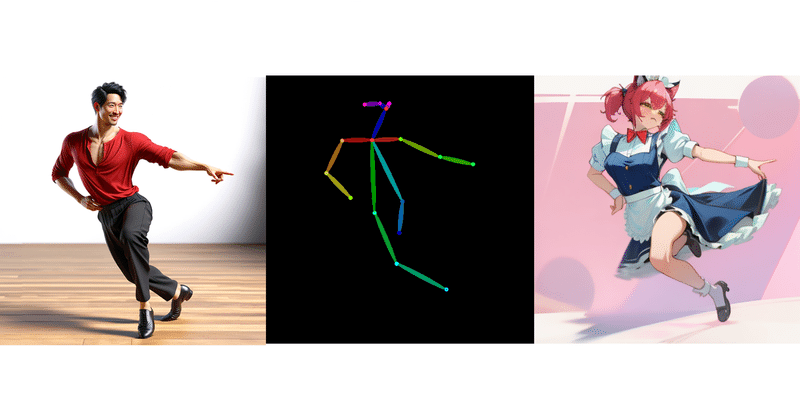
diffusers で ControlNet を試す
「diffusers」で「ControlNet」を試したので、まとめました。
1. ControlNet「ControlNet」は、「Stable Diffusion」モデルにおいて、新たな条件を指定することで生成される画像をコントロールする機能です。プロンプトでは指示しきれないポーズや構図の指定が可能になります。
2. ControlNetの更新履歴「diffusers」のControlNe

diffusers で IP-Adapter を試す
「diffusers」で「IP-Adapter」を試したので、まとめました。
前回1. IP-Adapter「IP-Adapter」は、指定した画像をプロンプトのように扱える機能です。詳かいプロンプトを記述しなくても、画像を指定するだけで類似画像を生成することができます。「Img2Img2」「ControlNet」「LCM-LoRA」など、diffusersの重要なパイプラインで利用できるように