Aya*
コンピュータビジョンの研究をしています。
最近はマルチモーダルRAGに興味があり、LlamaIndexを使ったあれこれを投稿していく予定です。
たまに読書記録も書き込む予定です。


最近の記事


LlamaIndex v0.10のTerms とDefinitions の抽出をためす from 「Putting It All Together - Q&A」
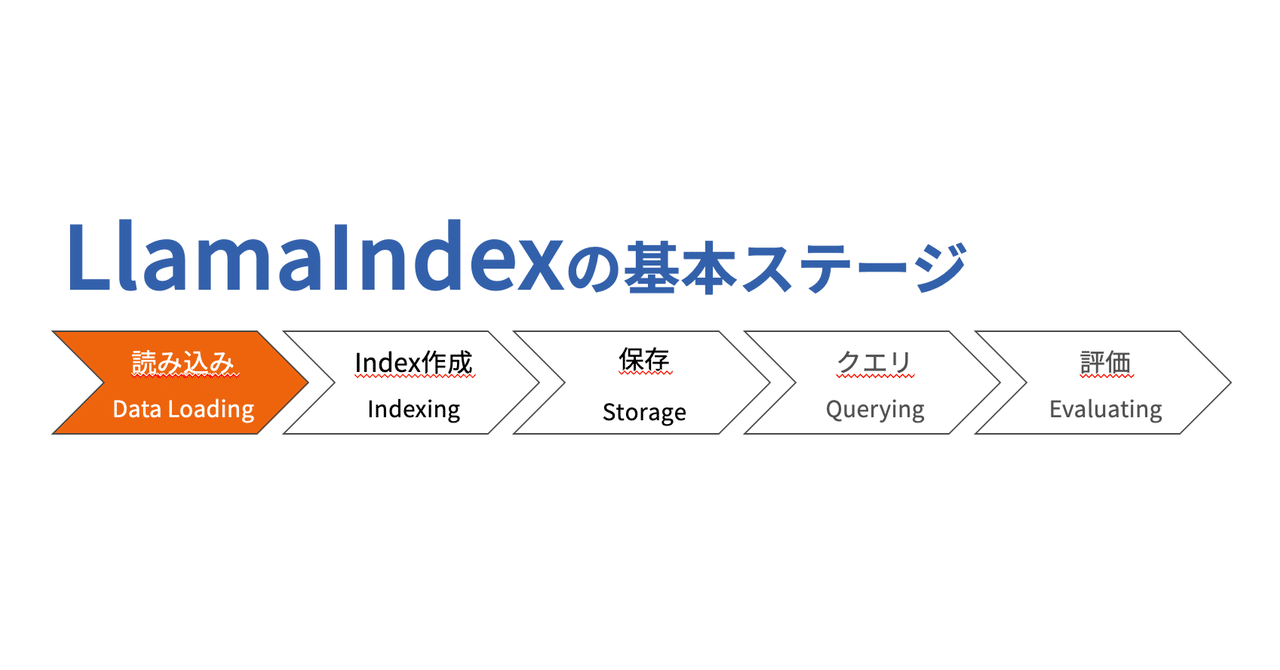
2024/02/27 こちらの公式ドキュメント(v0.10.13)を参考にQ&Aについてまとめていきます. https://docs.llamaindex.ai/en/stable/understanding/putting_it_all_together/q_and_a/terms_definitions_tutorial.html はじめにLlamaIndexには、十分に文書化された多くの使用例(セマンティック検索、要約など)があります。しかし、LlamaIndex
マガジン
記事
LlamaIndex v0.10の「Putting It All Together」のQ&Aをやってみる+PandasQueryEngine
2024/02/26 こちらの公式ドキュメント(v0.10.12)を参考にQ&Aについてまとめていきます. はじめにここまで,LlamaIndexを用いてデータをロードしインデックスを作成してクエリする一連の流れについて学んできました. ここからは,本番環境を見据えた具体的なフレームワークに落とし込むための方法についてみていきます. Putting It All TogetherLLMを用いたアプリケーションは大きく3つに分けられます. Q&A チャットボット