RAGの性能を向上したいサーベイ

2024/05/16
こんにちは。
今回はRAGの性能を一つ上に高めるための最近の手法について一気にまとめていきます。論文レベルと解説記事レベルの両刀でまとめることを目標としています。
RAGAS
と、いきなりRAGの手法に入るのではなく、評価指標として提案されてそこそこ有名なこちらの論文から紹介します。
こちらの記事を参考にしています。
論文はこちら。
RAGASとは
RAGシステムを評価する手法であり、2023年9月にイギリスのカーディフ大学の研究者らにより提案されました。メリットは、人力に頼らず自動で評価できる点です。
問題意識
回答精度向上のためには、その評価が必要となりますが、「正しいドキュメントを検索できているか」、「検索情報に基づく回答か」、「質問への回答になっているか」という様々な視点からの評価が必要となります。この問題に対処したのがこのRAGASです。
手法
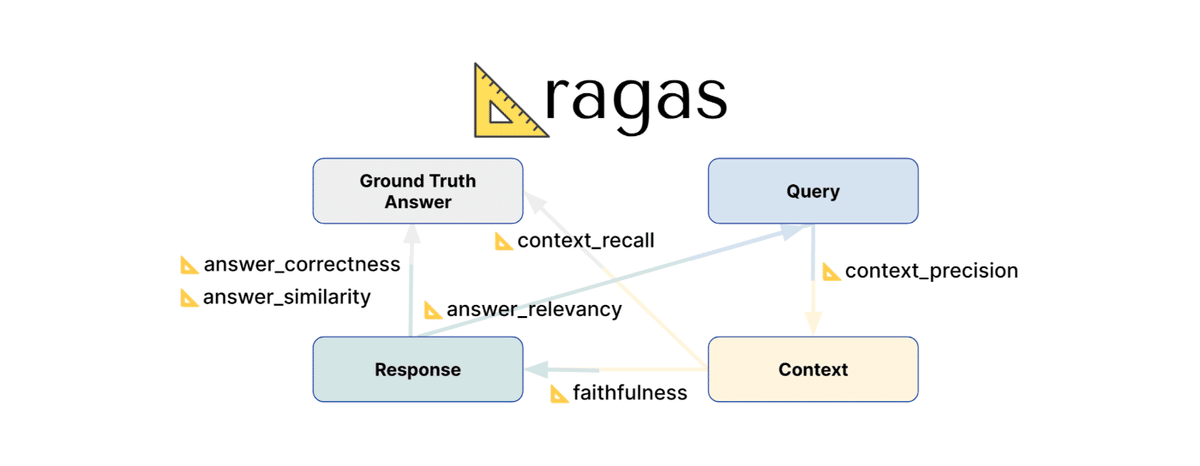
RAGASの論文では、3つの指標での自動評価が提案されています。現在は、8個ほどの評価指標があります。
Faithfulness(忠実性):検索したドキュメントに基づいて回答を生成できているか
Answer Relevance(回答の関連性):生成した文章が元の質問への回答になっているか
Context Relevance(文脈の関連性):質問に関連するドキュメントを検索できているか
この手法で重要な点は、RAGの評価を複数のパートに分類したことと、それぞれのパートでLLMを活用して自動で評価できるようにした点です。
結果

「WikiEval」というデータセットで検証した結果では、RAGASによる自動評価が人間の評価と高い一致率を示しており、FaithfulnessとAnswer Relevanceで高精度であることが確認されています。
正し、文脈の関連性の評価は比較的難しく、検索したドキュメントが長い場合に精度が下がりやすいです。
Self-RAG
https://zenn.dev/knowledgesense/articles/67dd2a41fc4d0b
https://arxiv.org/abs/2310.11511
概要
Self-RAGは、ワシントン大学などの研究者らによって2023年10月に提案されたRAGの性能を高めるための手法です。
回答品質の向上と、幻覚を減らすことが目的とされています。
優位点として、文書のレトリーバルが必要かどうか、取得してきた文書からの生成品質を自分自身でチェックする機能を取り入れる点です。誤っているか、無意味な内容は回答に利用されない仕組みになっています。
手法

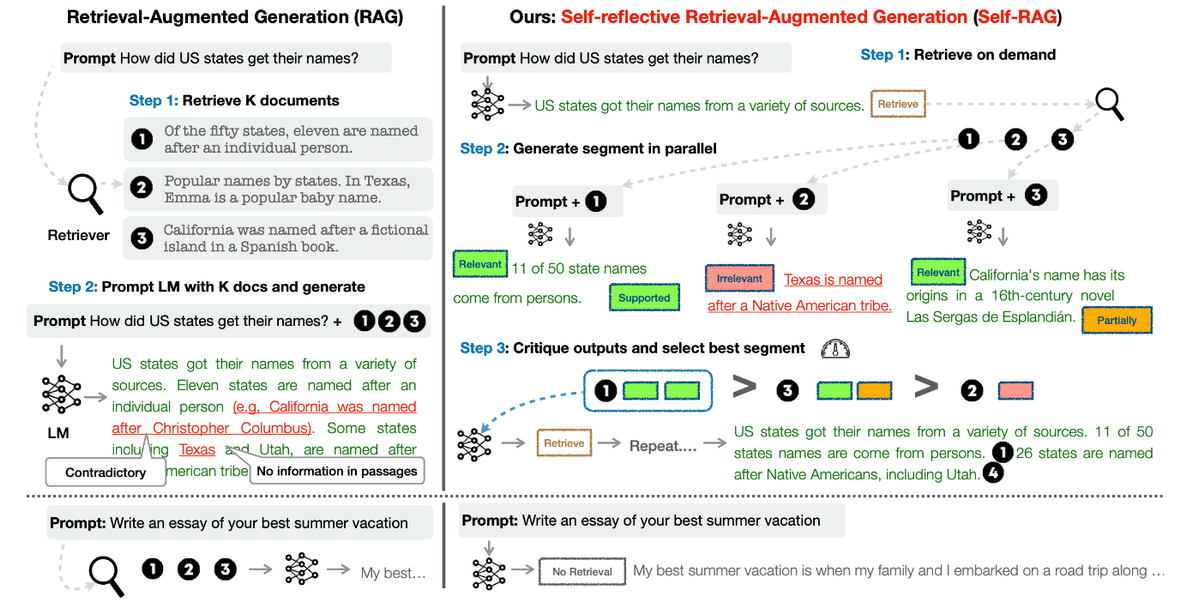
本論文では、
文書検索の必要性を判断
取得ドキュメントを批判的に選別する
という手法を提案しています。ポイントは以下の4つです。
LLMをファインチューニングし文章の生成の途中でreflection tokenを混ぜ込めるようにする
Self-RAGでは、独自にファインチューニングしたモデルを生成に利用します。ユーザーの質問に対し、まず検索の要否を自己判断
不要と判断した場合は文書検索はせず、独自の知識だけで回答を生成します。以下、検索した場合を説明します検索で取得した複数の文書を基に、それぞれ回答生成
それぞれのドキュメント1つずつ+元の質問をもとに、LLMが複数の回答を生成します。回答を評価、最も良い応答を選択
生成された複数の回答について、質問にして関係あるか、証拠になるか、有用かどうかを判断し、最もスコアの高い回答を採用します。
具体的なアルゴリズムは次のとおりです。

1. 入力: 入力プロンプトxと先行生成y<t, 出力: 次の出力セグメントyt
2. 生成器Mは(x, y<t)が与えられると[検索]の必要性を推測する
3. [検索]が必要なら->
3.1 検索器Rを用いて(x,yt-1)に基づき関連テキスト文書Dを検索
3.2 生成器Mは、x,dに基づき[IsREL]を推測、Dの各dについてx,d,y<tに基づきytを推測
3.3 生成器Mは[IsSup]と[IsUse]をx,yt,Dの各dに基づき推測する
3.4 [ISREL],[ISSUP],[ISUSE]に基づきytをランクづけ
4. [検索]が不要なら->
4.1 生成器Mgenはxに基づいてytを推測
4.2 生成器Mgenはx,ytに基づいて[IsUse]を推測
結果
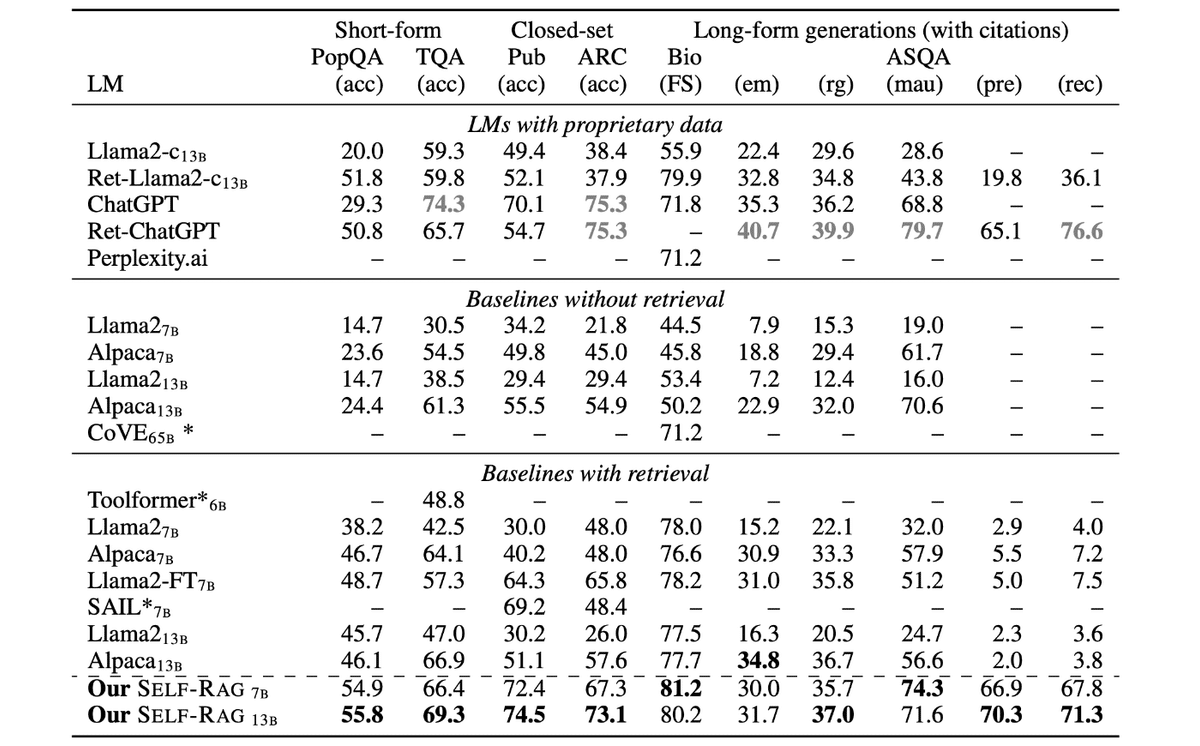
Self-RAGの評価実験は、大きく3種類のタスクで行われました。
オープンドメインQA (PopQA, TriviaQA)
選択式の推論タスク (ARC-Challenge, PubHealth)
長文生成 (Biography, ASQA)
比較対象は、パラメータ数の多いLLM、LLM+RAG、ChatGPTやLlama2-chatなどのモデルです。
結果として、Self-RAGは全てのタスクにおいてベースラインを大きく上回りました。
ARC-ChallengeやPubHealthでは70%以上の正解率
PopQAやTriviaQAでは50%以上の正解率でChatGPTを凌駕
長文生成ではChatGPTと同等以上
パラメータ数が少ないSelf-RAG 7Bが、ChatGPTやLlama2-chat 13Bを上回るケースもあり、提案手法の優位性が示されました。
CoA(Chain-of-Abstraction) Reasoning

https://arxiv.org/abs/2401.17464
概要
CoAはRAGにおいて回答精度を向上させるための手法で、Metaの研究者らにより2024年1月に提案されました。
CoAは、ユーザの質問が「複数の知識を組み合わせなければ回答できない」ような質問に対して効果を発揮します。通常のRAGでは、1回のドキュメント検索で回答に使えるドキュメントを探しますが、CoAでは問題を複数の問題に分解し、複数回のドキュメント検索を行った上で総合的な回答を生成できます。それだけでなく、類似手法であるCoTと異なり、回答時間が短く済むことが特徴です。
問題意識
RAGでは、複数回のツール呼び出しを必要とするような複雑な推論タスクでは、回答精度が悪かったり、CoTでは回答速度が遅くなるという課題があります。
手法

本論文では複数のツール、知識の呼び出しを短時間で行える手法としてchain-of-abstraction 推論を提案しています。
主なポイントは4つ。
LLMをファインチューニング。
1回の出力で複数ツールを呼び出せるようにします。
CoAでは、独自にファインチューニングしたLlama 2モデルを生成に利用します。ユーザーの質問に対し、回答に必要な複数ステップの命令を出力
複数の命令に基づき、それぞれのツールを呼び出す
外部API(ツール)を呼び出したり、ドキュメントを検索したりします。ツールからの複数の出力を組み合わせて最終回答を出す
結果

数学的タスクとWikiペディアを使ったQ&Aで、評価を行ったところ、CoAは、Chain-of-Thought(CoT)などの既存の手法と比較して、以下の成果が出ました。
正解率の向上
学習データと同じ分布のテストセット(In-Distribution)だけでなく、分布が異なるテストセット(Out-of-Distribution)でも、平均~6%の正解率向上を達成。推論速度の向上
CoAを活用したLLMエージェントは、平均~1.4倍という短時間で生成可能。
RAPTOR
RAPTORは、RAGの正確性を向上するフレームワークであり、効率的な文書の解像構造を構築するもので、2024年1月にスタンフォード大学の研究者らにより提案されました。
概要

文書を複数のレベルで要約することで、長文を含む文書を効率的に保管できる
GPT-4やUnifiedQAと組み合わせることで、3つのQAタスクで非常に高い成果を上げることができた
問題意識
LLMの性能の向上や、コンテキスト長が増加から、選択的な文書を選ばなくても必要な情報を適切に抜き出すことが可能になりつつあり、RAGで検索器などを用いて文書を選択する必要性は薄れているように思われます。
しかし、入力する文章が長大になれば、時間、金額、正確性において問題があり、検索器を用いた場合の方が良い成果があがりやすく、必要性は依然として存在します。
現在の文書の保管方法は、標準的なアプローチであり、連続的な文字列を任意の長さで分解し保管、ベクトルデータを元に検索するという手法がとられています。
しかし、このような連続的な文書の分割だけでは、文書全体の意味を捉え切ることができないという問題があります。この問題に対して、再起的な文書の要約を導入することで情報がより集約的になり広範な情報を取り扱えるようになる可能性があります。
既存手法では、文書の要約を検索対象としていても文書内での距離が遠い場合は集約ができませんでした。これに対して、RAPTORは、チャンクの意味的な近さをもとにグループ化して内容を要約する手法を採用しており、離れている場所の複合できな情報を集約できる仕組みにしています。
手法

RAPTORは、文書を保管する際にチャンクのベクトル化とグループ化、LLMによる要約を繰り返すことで文書をストックします。
文書のチャンク化
はじめに、文書を100トークン以下に分割し、チャンクとして扱います。この時、100トークン目が文書の途中であった場合、文章を丸ごと次のチャンクに保管するようにします。
チャンクのグループ化
ここからの処理は再起的な処理の一部となります。一つ前の段階で得られたチャンクを元に処理を行います。
チャンクのグループ化を行う際に特徴的な点として、チャンクが複数のグループに所属できるようにしている点です。この柔軟性により、複数のトピックが含まれていても各トピックにおいて必要な情報を含ませることができるようになります。
RAPTORで採用されている集約アルゴリズムはGaussian Mixture Models(GMMs)を元に作成されています。
GMMsでは、データを複数のガウス分布を重ねたものと捉えており、これをチャンクごとのベクトルデータに応用します。類似性を測る際には、ベクトル間の距離を使用すると適切に動作しない可能性があるため、Uniform Manifold Approximation and Projection(UMAP)を採用することで、次元削減を行いデータを使用します。
最適な分割数の決定にはBayesian Information Criterion(BIC)を使用します。これにより決定された数字を元に、Expectation-Maximizationアルゴリズムを用いて推定します。
グループに含まれるチャンクの要約
意味的に近いチャンク同士をグループ化した後は、その内容をLLMを使用して要約します。4%程度の要約に小さな幻覚が含まれていましたが、親ノードへの集約やLLMにわたすデータに含まれた際の影響はほとんど見受けられなかったと記述されています。
繰り返し
上記の作業を1つにグループがまとまるまで繰り返していきます。
検索手順
RAPTORは、要約などを含むチャンクデータに対して2種類の検索手順を提案しています。ただし、実験の結果、後述するcollapsed treeの2000トークンが最も精度が出たようです。

1. tree traversal
tree traversalという手法では以下のような手順で関連文書を取得します。
Rootの階層でコサイン類似度の近い任意の個数のチャンクを検索
取得したチャンクの子要素の中で再度コサイン類似度の近いチャンクを取り出す
2の手順を末端のチャンクに至るまで繰り返す。
取得したチャンクのうち、コサイン類似度の近い任意の個数のチャンクを取得する
2. collapsed tree
collapsed treeという手法では以下のような手順で関連文書を取得します。
階層に関係なくコサイン類似度を計算し、任意の個数のチャンクを取得する
あらかじめ設定した上限トークン数に至るまで繰り返しチャンクを取得していく
成果
RAPTORは以下の3つのデータセットで成果を検証しています。
物語文書検索タスク(NarrativeQA): 本や映画の内容を表す文章を元にしている。質問に対して答えるタスクを実行しており、いくつかの評価基準で評価している。
NLP論文の全文(QASPER):NLP論文の全文と5000個ほどの質問に対して、選択式の質問となっている。
文章に基づく多選択肢問題(QuALITY):5000トークンほどの文章の中から複数選択肢の中の正解を見つけるタスクとなっている。
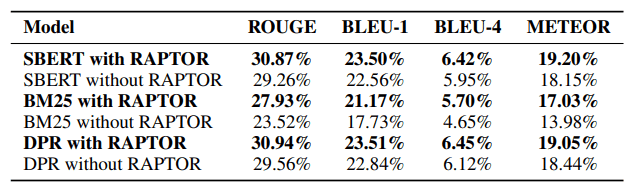


また、調査対象となっているGPT-3, GPT-4, UnifiedQAをLLMとして利用した場合であっても、BM25、DPRを使用した場合よりも高い精度が実現できているようです。
少なくとも既存のチャンク化のみの手法と比べるとRAPTORを導入することはプラスに働いていると言えそうです。
CRAG
https://zenn.dev/knowledgesense/articles/bb5e15abb3c547

https://arxiv.org/abs/2401.15884
概要
CRAGとは、Googleなどの研究者により2024年2月に提案された、「修正方検索拡張生成」と名付けられた手法です。
メリットは、幻覚を減らせることです。
これは、RAGの検索器が取得したチャンクを、生成器に渡す前に内容が正しいものなのかを自動でチェックする機能を取り入れているからです。
その結果、誤っていると判断された場合はWeb検索をして追加で知識を取得することで拡張を行います。
問題意識

大規模言語モデル(LLM)は事実と異なる内容を生成するハルシネーションの問題があります。
これに対して、外部の知識を参照することで幻覚を減らし正しい最新の情報に基づく回答をさせるしくみがRAGです。
しかし、その外部データに誤った情報があると返って悪い性能になることがあります(ゴミ箱からはゴミしか出てこない)。
手法

本論文では、RAGの検索結果を修正・改善する手法「Corrective Retrieval Augmented Generation (CRAG)」を提案しています。CRAGの主なポイントは以下の3つです。
検索評価モデルによる検索品質の判定
検索した文書の内容が入力に適しているかを、軽量な検索評価モデルで判定します。判定結果に基づいて、文書の修正や追加検索をしますWebからの知識収集
検索した文書が不十分な場合、Webを使って追加の知識を収集します。これにより、「そもそもRAGで取得してきたドキュメントが間違っていた場合」に知識を補うことが出来ます。文書の分解・再構成
検索した文書を細かく分解し、ドキュメントを減らしたり、再構成したりします。これによりノイズ情報を除去し、回答性能を高めます。
注意点として、企業が社内データを利用してRAGをするとき、Web検索したとしても結局回答に辿り着くようなドキュメントを見つけられないことも多いと思います。しかしながら、「このドキュメントからは答えを導けません」と回答できるようにする(幻覚を減らす)ためのチェック機能こそが、この手法の本質だと思います。
結果

論文ではCRAGとRAGを、先行研究の「Self-RAG」とも組み合わせて検証しています。その結果、CRAGを用いることでRAGやSelf-RAGの性能の向上が示唆されています。
RAG-Fusion
概要
RAG-Fusionは、Infineon Technologiesの研究者によって2024年2月に提案されたRAGの精度向上を狙った手法です。
複数のクエリを生成してランクづけする事で、さまざまな視点から見た質問を投げかけることで正確かつ包括的な回答を返すことを狙っています。
RAG-Fusionのメリットは次のような点にあります。
正確で包括的な回答を生成できる
多角的な視点からの回答を生成できる
技術情報など専門知識の回答の品質向上
問題意識
RAGでは関連文書を検索しLLMに回答を生成させますが、製品の選定ガイドやデータシートは数百ページにわたることが多く、この中から短時間で必要な情報を見つけ出し回答を生成する必要があります。
手法

RAG-Fusionは、元のクエリを受け取ると、LLMに元のクエリを入力し類似した新しい検索クエリを生成します。その後、逆数順位融合(RRF)アルゴリズムを使用して文書を再ランク付けし、生成されたクエリと元のクエリと合わせてLLMに送信して、出力を生成します。

結果
RAG-Fusionにより、正確で包括的な回答を出力できるようになった一方で、生成されたクエリが元のクエリから逸脱し関連していない場合は、回答がずれたものになることがあります。また、回答時間がベーシックなRAGより長くなってしまう点も課題です。

Adaptive-RAG
https://zenn.dev/knowledgesense/articles/8c23c35fa715c9
https://arxiv.org/abs/2403.14403
概要
Adaptive-RAGは、韓国科学技術院(KAIST)の研究者らによって2024年3月に提案されました。メリットは、ユーザからの入力としてシンプルな質問と複雑な質問の両方が想定される場合に、そこまで遅すぎないある程度の精度の回答ができる点です。
Adaptive-RAGでは、ユーザーから質問が来たときに、RAGするべきか、複数回のドキュメント検索をするべきか、を分類して適切な手法を利用することで回答を生成します。質問の複雑さに応じて適切な粒度で検索と応答をすることで精度の高い回答を生成します。
検索が必要かどうかを判別するなど、Self-RAGに似た手法であり、論文中で速度や精度の比較がされています。
問題意識
RAGを用いることで、多くの場面でLLMの回答性能を上げることができますが、文書検索が必要ない場合は回答速度の低下や余計な文書による精度の低下が考えられます。そこで、回答生成における文書検索の必要性を判断することが求められます。
手法
Adaptive-RAGは、質問の複雑さに基づいて最適な戦略を動的に選択できます。

B: マルチステップアプローチ
C: 提案アダプティブアプローチ
主なポイントは以下の3つです。
ユーザーからの質問について、簡単、中程度、複雑の3つに分類し、それぞれの場合で最適な回答手法を適用します。
簡単な質問 → 検索なしでLLMのみで回答
中程度の質問 → LLMと1回の検索を組み合わせて回答
複雑な質問 → LLMと複数回の検索を繰り返し、推論を重ねて回答
この手法のキモは、質問の難易度を判別する分類器です。これは、T5をファインチューニングすることで構築されています。
結果

複数のオープンドメインQAデータセットを用いてモデルを評価し、その結果、従来のアプローチ(Self-RAGなど)と比較して、提案モデルが全体的な効率と精度を向上させることができたと報告されています。テストケースがSingle-stepの場合とMulti-stepの場合とを見てみると、Adaptive-RAGは複雑な質問の場合には回答生成時間を長く取る代わりに回答精度を向上しています。
まとめ
ということで、さまざまな最近提案されたRAGの精度向上に向けた手法を一覧にしました。
この記事では、ナレッジセンスさんの記事を大いに参考にさせていただきました。とっかかりとして非常にわかりやすい記事が公開されていますので、ぜひそちらもご覧ください。
それでは、ご覧いただきありがとうございました。