テキスト埋め込みモデルはローカルで動かせるのか?サーベイ

こんにちは.
今回は,テキスト埋め込みモデルはローカルで動かせるもので十分な性能が出るのか調査してみました.
このテキスト埋め込みモデルは,RAGやLLMの性能の根本を決めるコンポーネントの一つであります.
Sentence Transformers
前提知識として,テキストを埋め込みと呼ばれるベクトル表現に変換するためのライブラリとしてSentence Transformersがあります.
この埋め込みに変換する利点は次の通り.
テキストの類似度算出ができる
分類やクラスタリングができる
セマンティック検索ができる
Multilingual-E5
こちらのサイトから,上記のモデルについて考察します.
このモデルは,Leaderboardでも好成績を収めており,`multilingual-e5-large-instruct`は分類,クラスタリング,検索などのデータセットによるタスクの平均で64.41であり,12位となっています.`multilingual-e5-base`は1.11GBのモデルサイズで59.45のスコアで51位,`multilingual-e5-small`は0.47GBで57.87のスコア,64位です.
$$
\begin{array}{|r|l|r|r} \hline
rank & Model & Model Size(GB) & Average(56 datasets) \\ \hline
1 & SFR-Embedding-Mistral & 14.22 & 67.56 \\ \hline
12 & multilingual-e5-large-instruct & 1.12 & 64.41 \\ \hline
36 & multilingual-e5-large & 2.24 & 61.50 \\ \hline
41 & text-embedding-ada-002 & - & 60.99 \\ \hline
51 & multilingual-e5-base & 1.11 & 59.45 \\ \hline
64 & multilingual-e5-small & 0.47 & 57.87 \\ \hline
\end{array}
$$

Maxトークン数について,adaは8192ですが,e5系は512です.
Multilingal-e5-largeでクルマのパンフレットを外部データとして動かした実装はこちらです.
デフォルトのチャンクサイズが1024になっているため,そのままだとインデックスを作成する際にout of rangeになる可能性があります.設定を変更しましょう.
実行した結果,いつものデータだとRAMを消費しきって実行できませんでした.
そこで,カローラスポーツ前期の簡易的な諸元表のみをドキュメントにして実行しましたが,それでもメモリサイズをオーバーしてしまいました.
そこで,次のような簡易ドキュメントで試しました.
from llama_index.core import SimpleDirectoryReader
from llama_index.core import Document
texts = ["私の名前は木村です.", "私の口癖は「ちょ,待てよ!」です.", "私は歌とダンスが得意です."]
documents = [Document(text=t) for t in texts]
print("documents :", documents)きちんと読み込めたようです.
DEBUG:llama_index.core.node_parser.node_utils:> Adding chunk: 私の名前は木村です.
DEBUG:llama_index.core.node_parser.node_utils:> Adding chunk: 私の口癖は「ちょ,待てよ!」です.
DEBUG:llama_index.core.node_parser.node_utils:> Adding chunk: 私は歌とダンスが得意です.クエリ応答の速度自体は良好です.

貴方の特技は何?と聞いてみました.

私の名前は木村です.という文とかなり僅差で私は歌とダンスが得意です.が勝っています.もう少し類似度が離れてほしいですね.
ドキュメントが読み込めなかった原因をもう少し探る必要がありますが,ここでいったん切ります.
Sentence Transformersライブラリによる実装
このライブラリはテキストを埋め込むライブラリです.
簡単に実装できるので,お試しください.
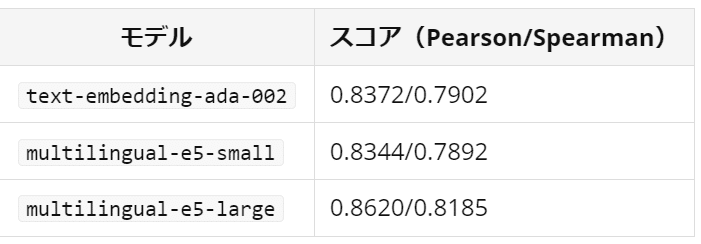
マルチリンガルE5の日本語での評価
続いてはこちらのサイトより.
E5とは
E5はEmbEddings from bidirEctional Encoder rEpresentationsから来ているそうです.無理やりすぎるし,なんならrepresentationsに「e」もう一個ありますけど,,,笑
Web上から収集した大規模なテキストペアのデータセットからcontrastive learningしたのち,NLIやMS Marcoなどの高品質なデータセットで学習をしているようです.
性能としてはadaを上回る性能が報告されています.
ただし,シーケンス長は短いです.
完全にローカルでRAG
こちらの記事を参考にすると,APIにたよらずRAGシステムが実装できます.
モジュールのimportのみ抜粋します
import logging
import os
import sys
from llama_index import (
LLMPredictor,
PromptTemplate,
ServiceContext,
SimpleDirectoryReader,
VectorStoreIndex,
)
from llama_index.callbacks import CallbackManager, LlamaDebugHandler
from llama_index.embeddings import HuggingFaceEmbedding
from llama_index.llms import LlamaCPP
# ログレベルの設定
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG, force=True)これだけで実装できるのはLlamaIndexのアブストラクトの恩恵が大きいですね.しっかりtext embeddingモデルと,LLMをローカルモデルにすることができます.
# LLMのセットアップ
model_path = f"models/ELYZA-japanese-Llama-2-7b-fast-instruct-gguf/ELYZA-japanese-Llama-2-7b-fast-instruct-q8_0.gguf"
llm = LlamaCPP(
model_path=model_path,
temperature=0.1,
model_kwargs={"n_ctx": 4096, "n_gpu_layers": 32},
)
llm_predictor = LLMPredictor(llm=llm)# 実行するモデルの指定とキャッシュフォルダの指定
embed_model_name = ("intfloat/multilingual-e5-large",)
cache_folder = "./sentence_transformers"
# 埋め込みモデルの作成
embed_model = HuggingFaceEmbedding(
model_name="intfloat/multilingual-e5-large",
cache_folder=cache_folder,
device=EMBEDDING_DEVICE,
)それぞれこちらの部分です.
ただし,元記事ではllama-indexのバージョンが0.9.13であり,現在の0.10世代では使用できない部分もあるので,ご注意ください.
番外編: text-embedding-3
ここまでは主にmultilingual-e5とadaを比較していましたが,OpenAIから新しい埋め込みモデルもリリースされています.
詳しくはまだ調べていないので,より詳しいサイトの参照をお勧めします.