
ノーコードでわかる Embedding/RetrievalーーChatGPTなど生成AIの精度向上法「RAG」入門その3(一部訂正・追加あり)

こんにちは!
ノリトです。ClaudeやChatGPT使ってますか?
RAGで業務知識を教え込めば、生成AIは仕事に使えます。
RAGには2種類あり、知識ベースをデータベースで与える外部RAGと、プロンプトに入れて与える内部RAGがあります。
この記事では、外部RAGに使うEmbedding(エンベディング、埋込)とRetieval(リトリーバル、取得)の根本、そして、外部RAGと内部RAGの性能の違いについて説明します。
この根本がわかれば、生成AIは魔法ではなく単なる技術だということが分かります。
エンジニアやプログラマでなくても理解できるよう、ノーコードで説明いたしますので、この森に入ってきて下さい。
4月1日に記事を一部訂正、追記いたしました。
不十分な理解で申し訳ありませんでした。
2.2 外部RAGに使う簡易検索手法=ベクトル検索
3.3 性能は?
に訂正、追記がありますので、ご確認下さい。
追記により、なぜ次元数が重要であるのか、より分かりやすくなっています。
この記事は、大阪のIT専門学校「清風情報工科学院」の校長・平岡憲人(ノリト)がお送りします。
なお、清風情報工科学院では、生成AIを若者に教えたい、生成AIを教育に活用して能力開発したい、というスタッフを募集しております。
清風情報工科学院では、情報処理系の講師を急募しております。
ご興味のある方はこちらの記事を御覧ください。
1.RAGとは
ChatGPTやClaudeなどの大規模言語モデルに含まれていない情報を、外部から与えて、より適切な回答を生成させる技術がRAGです。
自然言語を処理できるベクトルデータベースなどで知識ベースを情報検索して大規模言語モデルに与えます。
最近は、大規模言語モデルが一度に処理できるテキスト(コンテキストウィンドウという)の量が増えたため、知識ベースそのものを大規模言語モデルに与えることも可能になってきています。
1.1 RAGの基本概念
自然言語を理解し回答を自然言語で生成できる大規模言語モデルは、事前に大量の情報を学習しています。
その情報に基づいて、回答を生成します。
しかし、その情報には限りがあり、また最新の情報は含まれず(カットオフ)、さらに社外に公開されない情報となると事前学習情報に含みようがないという問題があります。
これに対し、RAGは、Retrieval Augmented Generationの略で、検索拡張生成とよばれる技術です。
大規模言語モデルに含まれていない情報を、外部から大規模言語モデルに与えて、より適切な回答を生成させるために使います。

ユーザーのプロンプトに応じて、知識ベースを検索し、その検索結果をシステムの内部でプロンプトに加え、それを大規模言語モデルに渡して回答を生成します。
例えば、ユーザーからの商品への問い合せがあった際、企業の製品のリストやその詳細な仕様、トラブル対応事例などを調べたうえでユーザーに回答を生成したい、という時には、RAGを使う必要があります。
1.2 外部RAGと内部RAG
ChatGPTが登場した当初(2022年11月30日)、大規模言語モデルはわずかなテキストを処理できるだけでした。
ChatGPTの大規模言語モデル(GPT)が一度にユーザーから受け取れる情報の量(コンテキストウィンドウという)は、1,024トークン(日本語でほぼ1000文字、当初)しかありませんでした。
その後、4,096トークン、8,192トークン、一部モデルでは16,385トークンとなり、現在は128,000トークンのモデルまであります。
また、AnthropicのClaudeシリーズは、200,000トークンが売りで、GoogleのGemini 1.5 Proは1,000,000文字の処理が可能と発表しています。
3章で紹介する知識ベース(日本語学校の特徴リスト)は、38校分で5092文字です。
これだと初期のChatGPTでは処理ができませんし、4000文字制限のあるPerplexityやCopilotではデータが入りません。
逆に、5092文字が38校のデータだと、200,000トークンなら1500校程度となり、1,000,000文字なら7500校程度の情報までコンテキストウィンドウに入ります。
日本語学校の数は全国で800校程度ですので、各校の情報をもう少し詳しくしても、全校分収録できてしまいます。
こうなると、わざわざベクトルデータベースをつくらなくとも、大規模言語モデルのプロンプト内に外部データを入れて、検索も生成もさせてしまったらどうか、という発想がでてくるのです。
本記事では、ベクトルデータベースなどを外部に作り、外部のデータベースの検索結果(Retrieval結果)から大規模言語モデルが知識を得て回答を生成するRAGを外部RAGと呼んでいます。
一方、大規模言語モデルのコンテキストウィンドウに外部データベースを取り込み大規模言語モデルで直接検索も回答生成もしてしまうRAGを内部RAGと呼んでいます。
2.Embedding/Retievalとは
ChatGPTなどの生成AIを、仕事に使うには、仕事固有の情報を生成AIに取り込む必要があります。
それに成功すれば、次の記事のようなことが可能になります。
ただ、「Embedding(エンベディング)」という横文字が横たわっています。
その正体は簡単な技術なので、霧を晴らして進みましょう。
2.1 Embeddingとは自然言語のベクトル化のこと
これまで、情報の検索にはデータベースが使われていました。
ただ、従来の検索には少し弱点があります。
同じ言葉で検索しないとヒットしないことです。
同じものごとでも、いろんな言い方で表現できます。
例えば、机、テーブル、デスクは概ね同じものですが、字面は違います。
「リンゴ」と「林檎」のような表記の違いや、「自動車」と「車」のような表現の違いで、検索できなくなってしまうのでは困ります。
本来情報検索は「似たようなもの」を見つけ出す必要があるのです。
「似たようなもの」を探す技術のひとつが、Embeddingです。
その正体は、自然言語をコンピュータの内部表現であるベクトルという多数の数の塊に変換することです。
例えば、動物-機械軸、人間-獣軸というような2次元に言葉を並べます。
すると、言葉はその座標(数値の組合せ)で表せるようになります。
似たような言葉は近くに、そうでない言葉が遠くような空間です。

Embedは、埋め込むという意味の言葉です。
生成AIに埋め込む、というニュアンスです。
ただ、実際には、数値化する、ベクトル化するという技術なので、単純に「ベクトル化(Vectorization)」と表現してもらいたかったです。
学ぶ際、専門用語の言葉でつまづくことが多いので。
例えば、VoyageAIの「voyage-large-2」というモデルで、次の言葉をベクトル化します。

これは大阪の日本語学校の特徴のデータベースです。
学校の特徴の言葉をベクトル化すると、次のようにそれぞれ1536個の数値の塊になります。

コンピュータというのは、言葉よりも、こういう数値の塊のほうが「理解できる」というのですから、不思議な代物です。
1536個という数は、次元数といい、数値の個数を表します。
数値が多いほど、言葉の細かいニュアンスまで表現できると理解すればよいです。
なお、数値は、-1から1までの実数になっています。
<技術情報>
Embeddingは、自然言語を単語に分け、似たような単語をグループ化し、その単語のグループの配列で言葉を表す技術です。
Embeddingで大変なのは、自然言語を単語に分け、似たような単語をグループ化し、その単語のグループの配列で言葉を表す部分です。
ただ、この処理はパッケージ化され、一般公開されています。
これが Embeddings APIと呼ばれているものです。
次元数はモデルによって違います。
ベンダー モデル名 次元数 日本語対応
OpenAI text-embedding-3-large 3072 ◯
OpenAI text-embedding-3-small 1536 ◯
VoyageAI voyage-large-2 1536 △
VoyageAI voyage-2 1024 △
VoyageAI voyage-lite-02-instruct 1024 △
Embedding APIについては、次の資料を御覧ください。
Embeddingについては、様々なモデルがHuggingfaceに公開されています。
その使い方は次の記事を御覧ください。
私は当初、この公開モデルを使って記事を書こうとしました。
しかし、日本語の場合、Tokenizeという文を単語に分ける処理が大変で、単語化+ベクトル化と少なくとも2段階の処理が必要です。
この処理だけで記事がいくつも必要そうでした。
そこで、本記事では、EmbeddingはAPIを使ってするもの、と割り切っています。
なお、Embedding APIは有料です。
但し、この記事の後半で述べるように、本記事で取り上げたVoyageAIのモデルは当初5000万トークンまで無料という太っ腹モデルです。
2.2 外部RAGに使う簡易検索手法=ベクトル検索
Embeddingによってベクトル化した情報はどうすれば検索できるのでしょうか?
その方法は、計算です。
高等学校で学んだコサインという三角関数を使います。
言葉が置かれた空間は、近くに似た意味の言葉が来て、同じ方向にその意味の度合いがくるという特徴があります。
(以下、訂正・追記)
犬と猫が近くにあり、犬の方向にチワワやドーベルマンが、猫の方向にラグドールとシャム猫がいる犬の周辺にはチワワやドーベルマンといった犬種が、猫の周辺にはラグドールやシャム猫といった猫種が分布していると想像して下さい。
動物-機械軸、人間-獣軸で分けている場合、チワワとラグドールは少し人間より、ドーベルマンとシャム猫は少し獣よりに位置することでしょう。
(以上、訂正・修正)
そこで、ある言葉とある言葉の角度を調べれば言葉の類似度がある程度わかることになります。

この場合、チワワとドーベルマンの違いやラグドールとシャム猫の違いには目をつぶり、「要するに犬と猫だろ」と割り切って、違いを見るわけです。
(以下、削除)
また、チワワやラグドールは大人しい、ドーベルマンとシャム猫は野生っぽいという違いがあります。
その程度の違いにも注目します。
角度と距離(長さ、程度の大きさ)で表されるのが、高校で学んだ三角関数です。
似ている度合い(類似度)を、1からー1までの数値(1=完全一致、-1=正反対)で表すとします。
似ている度合いに都合が良いのが、コサイン(Cos)です。
全く同じであれば角度がゼロで数値は1になり、何とも言えないなら角度が90度で数値はゼロ、全く違うなら角度が180度で数値は-1というのが都合いいのです。
(以下、追記)

さらに、コサインは、概ね似ているものはほぼ同じ値になり、違う度合いが多くなれば値が大きく変わるという特徴があります。(詳しくは後述)
大まかな類似性を捉えるのに適しています。
(以上、追記)
つまり、2つの言葉のベクトル表現のコサインを計算すると、似ているものを探せるということです。
類似度を表すのに使うコサインのことを特に「コサイン類似度」と呼びます。
<技術情報>
コサイン類似度は、次の式で計算します。

2次元なら標準のコサイン関数を使えばいいのですが、多次元のベクトルなので、上の式で計算することになります。
ちなみに、2次元のコサインもこの式で計算できます。
いずれにせよ、数式なのでいかめしいですね。
ただ、この式は、ExcelやGoogleスプレッドシートの標準関数の組み合わせで表現できます。
=SUMPRODUCT(ベクトルA,ベクトルB)/(SQRT(SUMSQ(ベクトルA))*SQRT(SUMSQ(ベクトルB)))
SUMPRODUCT ・・・ 掛け算して足せ(上辺)
SUMSQ ・・・ 二乗して足せ(下辺のルートの中)
SQRT ・・・ ルートをとれ(下辺)
と、公式のまんまです。
標準関数の組み合わせなので、爆速で計算可能です。
(以下、追記)
コサインには、類似度が高いと鈍感に変化し、類似度が低いと敏感に変化するという特徴があります。
次のグラフをご覧ください。

横軸は、0度から180度を15度づつ区切ったもののです。
縦軸は、15度変わった時にコサインの値がどれだけ変わるかです。
これによれば、横軸の両側、つまり0度とか180度に近いと、角度が変わっても値はあまり変わらない、ということが分かります。
似ているものが近くにある、ということは、似ていれば角度はほぼ同じ、角度の違いはゼロに近くなります。
0度に近い場合は、類似度はあまり変化しません。
似ていればちょっとの違いは無視するということです。
逆に、90度あたりは、15度違うだけで値が大きく変わります。
似てない場合は似てないとはっきり言う、ということですね。
これにより、コサインは、大きく見て違う時は違うといい、細かい違いには目をつぶって似ているという尺度に使えるということなのです。
では、細かい違いに注目するにはどうしたらいいのでしょうか?
そこで出てくるのが次元数です。
次元数を増やすことで、より詳細な類似性の違いを表現することができるようになります。
例えば、「チワワ」と「ラグドール」は大人しい性質を持ち、「ドーベルマン」と「シャム猫」は野生的な性質を持つといった違いを、別の次元で表現することができるようになります。
例えば、「犬」と「猫」は、低次元の空間では「ペット」という点で類似していますが、高次元の空間では「サイズ」や「鳴き声」といった詳細な特徴の違いを表現できます。
それゆえに、高精度のEmbeddingモデルは、次元数の多さをアピールすることになっているのです。
この記事で取り上げたEmbeddingモデルの次元数を示します。
・text-embedding-3-large 3072
・text-embedding-3-small 1536
・voyage-large-2 1536
・voyage-2 1024
・voyage-lite-02-instruct 1024
一般に次元数の高いモデルのほうが精度が高く、コストも高いとお考え下さい。
(以上、追記)
2.3 コサイン類似度で似たものを探す
実際に似た情報を探すには次のようにします。
先に、外部知識をベクトル化しておきます。
その上で、同樣に検索語(検索クエリーとも呼ぶ)もベクトル化します。
そして、検索語のベクトルと、外部知識のベクトルの、コサインを順々にとっていきます。
あとは、その値を大きなものから並べれば、似ているものリストが得られるということです。
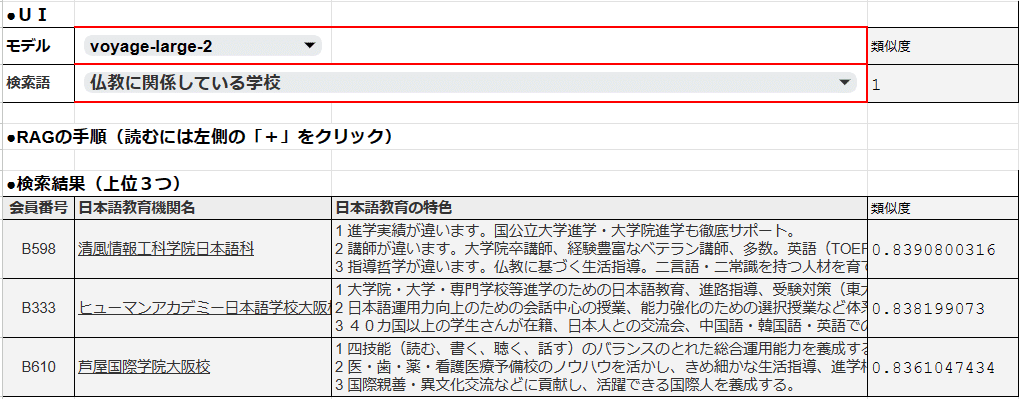
例えば、(1)で取り上げた3つの学校の特徴に対して、「仏教に関係している学校」という調べ物をしているとします。
まず、日本語学校の特徴をベクトル化しておきます。
次に、検索語である「仏教に関係している学校」という言葉もベクトル化します。

そして、検索語のベクトルと、各学校の特徴のベクトルの、コサインを順々に計算します。
次の表では、コサイン類似度の列を一列増やして表示してあります。
「類似度」という列を御覧ください。

検索語である「仏教に関連している学校」を起点にしているので、「仏教に関連している学校」との角度はゼロ。
そのコサインで、類似度は1になります。
そして検索語と各校の特徴との間の類似度がそれぞれ計算できました。
この例では、類似度の上位3校をあらかじめ選んであるので、並び替え後の表だとお考え下さい。
このように、ベクトル表現されたデータを検索する方法を「ベクトル検索」と言います。
2.4 Retievalでとってくるのはインデックスだけ
ベクトル検索で似ているものを見つけることはできました。
今度は、似ている内容を知りたいです。
では、コサインの逆であるアークコサインを使うのか?といえばそんなことはありません。
実は、ベクトル表現を元の言葉に戻すことはできないのです。
ベクトル検索で得られるのは類似度とその順位です。
しかし、RAGにおいては、大規模言語モデルに自然言語でベクトル検索の結果を渡す必要があります。
そこで、ベクトル化する際に、各データに索引用の番号(インデックスという、ここの例では会員番号)を組みにしておきます。
そして、類似度が計算できたら、上位のデータのインデックスをとります。
そのインデックスを元に、元の知識ベースから自然言語の表現をとってくる、こういうまどろっこしいことをします。
つまり、本当は、ベクトル検索では順番しかわからないのです。
これが Retrieval(リトリーバル)とよばれるベクトル検索の情報取得のプロセスの本体です。

2.5 自然言語に戻す方法
類似度の計算により、似たものの順番がわかり、そのインデックスを取ってくることができました。
最後はこれを自然言語に戻します。
それには、インデックスを頼りに、元の知識ベースを検索します。
この検索は、データベースならSQL検索を使います。
ExcelやGoogleスプレッドシートなら、VLOOKUP関数や、INDEXとMATCH関数を使えばよいですね。
ここの例では、元の知識ベースにも同じインデックスがありますから、このインデックスが一致するデータを知識ベースから取ってきます。
例えば、ベクトル検索で類似度2の会員番号「B333」の情報を探すと、上の表の5行目に、「B333、ヒューマンアカデミー日本語学校、1大学院・・・」という情報が得られます。
知識ベースから自然言語の表現を取り出すと、次のような表が得られます。

これでようやく、「仏教に関連している学校」に似ている日本語学校のリストが得られ、しかも、その学校の特徴も得られました。
あとは、この情報を大規模言語モデルに渡せば、それらしい文章にして、回答を生成してくれるという塩梅です。
情報が不足していると、大規模言語モデルはハルシネーションを起こして、無責任な回答を生成します。
しかし、RAGにより正しい情報を与えることができれば、その情報に基づく回答を生成するので、正確な情報でやりとり可能になります。
だから、仕事に使える生成AIになるということですね。
3.Googleスプレッドシートでハンズオン
理屈がわかったところで、実際に手を動かしてやってみましょう。
Googleスプレッドシートで、EmbeddingとRetrievalを体験できるようにしてあります。
それを開いて見て下さい。
3.1 スプレッドシートの見方・使い方
(1)シートを開く
では、次のリンクをクリックして、Googleスプレッドシートを開きます。
ノーコードでわかる Embedding / Retrieval
ワークシートを開くと、「Main」シートが選択されれているはずです。

もし別のシートでしたら、画面下のシート選択タブで青い「Main」をクリックして下さい。
(2)使用上の注意
Embedding API は有料であるため、実際にAPIにアクセスしてベクトル化を行うわけではありません。
このワークシートでは、Embedding API で得られた各表現のベクトル表現を保存しています。
そのため、検索語は選択しかできません。
また、知識ベースを変更することはできません。
一方で、シート上でモデルを切り替えたり、検索語を選択すると、コサイン類似度の計算を行い、検索結果が動的に変化します。
いずれ、実際にEmbeddingの計算を行うワークシートを公表する予定です。
(3)「Main」シートの画面構成
「Main」シートは上から順番に
●UI部
●RAGの手順
●検索結果
●知識ベース
●シート選択タブ
で構成されています。

●UI部は、Embeddingのモデルを選ぶのと、検索語の入力(選択)ができます。
モデルを変更すると、ベクトルデータベースが切り替わり、検索結果が変わります。
検索語は6つ選択可能です。変更すると類似度計算が行われ、検索結果が変わります。

●RAGの手順部は、通常は隠されています。
左の列番号のさらに左側にある「+」をクリックすると、簡単な説明が現れます。
再度同じ場所のボタン(「-」)をクリックすると、説明が隠れます。

●検索結果部は、コサイン類似度で検索語に近い上位3つの結果が表示されます。

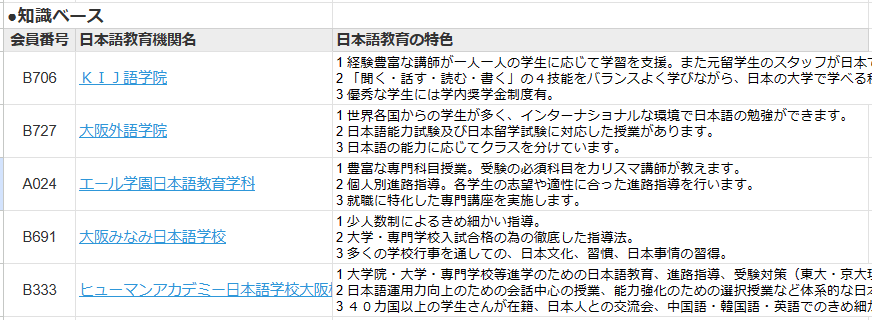
●知識ベース部は、日本語学校の特徴のデータベースです。
大阪近辺の日本語学校38校の会員番号、学校名、日本語教育の特徴のリストです。
出典は、日本語教育振興協会の会員校情報です。

●シート選択タブは、次のようになっています。
シートは左から
・まとめ 次の章で述べる外部RAG・内部RAGの性能比較表
・まとめ縦 同上(縦組みの表)
・Main メインシート
・text-embedding-3-large OpenAIのtext-embedding-3-largeでベクトル化したデータ
・text-embedding-3-small OpenAIのtext-embedding-3-smallでベクトル化したデータ
・voyage-large-2 VoyageAIのvoyage-large-2でベクトル化したデータ
・voyage-2 VoyageAIのvoyage-2でベクトル化したデータ
・voyage-lite-02-instruct VoyageAIのvoyage-lite-02-instructでベクトル化したデータ
・マスター 作業用(非表示)

(4)ベクトルデータベースの各シート
text-embedding-3-largeなどのEmbeddingモデルでベクトル化したデータのことをベクトルデータベースと呼ぶことにします。
ベクトルデータベースはいずれも同じ形式になっています。

各シートの上部は、検索語のベクトル表現です。
その下に、知識ベースのベクトル表現があります。
ベクトル表現はモデルにより次元数が異なります。
次元数は「D10」セルに表示されています。
また、C列は「Main」シートで選択されている検索語と各ベクトル表現の間のコサイン類似度の列です。
「Main」シートで検索語を別の語に変更すると、このC列の数値が変化します。
3.2 処理内容
実際に、「Main」シートのUI部で、モデルを選択したり、検索語を変化させてみて下さい。
動的に、検索結果が変化します。
類似度の計算は一瞬で終わると思います。
ただ、コンピュータの性能が低い場合、メモリの搭載量が少ない場合は時間がかかるかもしれません。
当方の環境は
・Windows 11
・第8世代 Core i7プロセッサ
・メモリ 48GB
・SSD 2TB
ですので、決して最新の環境ではありません。
メモリとSSDは贅沢していますけれど。
3.3 性能は?
さて、検索性能を見てみましょう。
OpenAIとVoyageAIの各Embeddingモデルによる各検索語に対する類似度の上位3校を表にしました。
全般的にぱっとしません。

特徴の中に「仏教に基づく教育」をうたっているのは清風情報工科学院だけなのですが、「仏教に関係している学校」として清風情報工科学院を上げたのはVoyageAIのvoyage-large-2だけでした。
「受験校」というキーワードでも、それぞれ根拠のありそうな学校が並んでいるものの、「カリスマ講師がいるぞ」や「大学・大学院への進学実績がよいぞ」というような表現をしている学校が上位には上がっていません。
「美人が多い学校」はあえて聞いてみた質問です。どの学校も「うちは美人が多いです」とこのご時世宣伝する訳もありません。となると、「わからない」というのが答えのはずですが、適当な計算結果が並んでいます。
私も、今回このような計算を実際にやってみて、「Text Embeddingって案外性能が低いんだな」と感じた次第です。
(以下、追記)
2.2で、コサイン類似度の計算は、大きく見て似ているかどうかを判断するのに使えるが、細かい違いには敏感ではない、と書きました。
「進学校」かどうかについて少し考察してみます。
実は、多くの日本語学校が進学をメインにして教育しています。
各校の特徴もそんな表現が多いです。
そこで、Embeddingモデルは、各校には細かい違いはあるが概ねみな進学校だと考えた、ということでしょう。
(以上、追記)
ただ、次の章で述べますが、コストは安いんです。
ごく安いコストで、まぁほどほどの結果を高速に得ることができるというのが売りの技術だと判断しています。
3.4 VoyageAIのEmbeddingモデル
VoyageAIの結果は少し割り引いて見る必要があります。
なぜなら、VoyageAIのモデルはいずれも英語用のモデルで、日本語にも対応したマルチリンガルモデルではないからです。
この検索結果の類似度のところをよく見て下さい。
各校の類似度の差がほとんどありません。
清風情報工科学院の特色には「仏教に基づく生活指導」という文言があります。
他の2校にはなく、交流会があるというような一般的な表現です。
しかし、類似度の違いは、0.001と0.003しかありません。
これはVoyageAIのモデルの日本語の処理に問題があることを示唆しています。
あえてVoyageAIのモデルを選んだ理由は、
・Claudeを開発しているAnthropicのホームページで利用が薦められている
・利用コストが安く、かつ、初期の5000万トークンまで無料で使える
・近々日本語に対応する予定
が理由です。
将来のバージョンに期待します。
埋め込みプロバイダーを選択する場合、ニーズや好みに応じて考慮できる要素がいくつかあります。
データセットのサイズとドメインの特異性:モデル トレーニング データセットのサイズと、埋め込むドメインとの関連性。一般に、より大きなデータまたはよりドメイン固有のデータほど、より優れたドメイン内埋め込みが生成されます。
モデル アーキテクチャ:モデルの設計と複雑さ。 Transformers のような最新の技術とアーキテクチャは、より高品質の埋め込みを学習して生成する傾向があります。
推論パフォーマンス:組み込みルックアップ速度とエンドツーエンドの遅延。これは、大規模な運用環境のデプロイメントでは特に重要な考慮事項です。
カスタマイズ:プライベート データの継続的なトレーニング、または非常に特定のドメイン向けのモデルの特殊化のオプション。これにより、固有の語彙のパフォーマンスが向上します。
Anthropic は独自の埋め込みモデルを提供しません。上記の 4 つの考慮事項すべてを網羅する幅広いオプションと機能を備えたエンベディング プロバイダーの 1 つがVoyage AIです。 Voyage AI は最先端の埋め込みモデルを作成し、金融やヘルスケアなどの特定の業界ドメイン向けにカスタマイズされたモデル、または個々の顧客向けにオーダーメイドで微調整されたモデルを提供します。
Embeddings
We charge for requests to the Voyage embedding endpoint based on the number of tokens in the docs/queries.
The first 50 million tokens for voyage-2, voyage-large-2, and voyage-code-2 are free for every account. Subsequent usage is priced on a per-token basis. Subsequent usage is priced on a per-token basis as in the following table.
埋め込み
Voyage埋め込みエンドポイントへのリクエストについては、ドキュメントやクエリのトークン数に基づいて課金されます。
voyage-2、voyage-large-2、voyage-code-2については、アカウントごとに最初の5000万トークンは無料です。その後の使用については、トークンごとに課金されます。以下の表のように、トークンごとに料金が設定されています。

4.外部RAGと内部RAGの比較
4.1 比較した大規模言語モデル
本記事では、ベクトルデータベースなどを外部に作り、外部のデータベースの検索結果(Retrieval結果)から大規模言語モデルが知識を得て回答を生成するRAGを外部RAG、大規模言語モデルのコンテキストウィンドウに外部データベースを取り込み大規模言語モデルで直接検索も回答生成もしてしまうRAGを内部RAGと呼んでいます。
ここでは、外部RAGと内部RAGの性能を比較するため、一般によく使われている次の大規模言語モデルを取り上げました。
OpenAI ChatGPT4 Turbo
OpenAI ChatGPT3.5 Turbo
Anthropic Claude 3 Opus
Anthropic Claude 3 Sonnet
Anthropic Claude 3 Haiku
Google Gemini 1.5 Pro
Google Gemini 1.0 Pro
Microsoft Copilot creative(GPT4 Turbo)
Perplexity Writing
ChatGPTとAnthropic Claudeは、いずれも有料課金モードで利用したものです。最初に、知識ベースを与え、その後対話を往復した結果です。比較表のコスト欄はAPI経由で利用した料金を示しています。
Google Geminiは、Google AI Studioで利用した結果です。最初に、知識ベースを与え、その後対話を往復した結果です。比較表のコスト欄はAPI経由で利用した料金で、データを学習に利用されないモードのものを示しました。
Copilotは、GPT4 Turboを使う「Creative(創造的)」モードで利用しました。コンテキストウィンドウは4000文字に制限されていて、データは途中までの状態で動作しました。さらに対話の往復回数が制限されており、4往復までで検索は自動終了になりました。
Perplexityは、複数の大規模言語モデルを切り替えて利用できるサービスです。しかし、いずれのモデルでもコンテキストウィンドウは4000文字に制限されています。今回の知識ベースを貼り付けると、文字数オーバーで検索ボタンが押せない状態となり、今回の用途には利用できませんでした。
いずれのモデルも、次の要領で対話した結果です。
a.まず、知識ベース(表をmarkdown形式にしたテキスト)をプロンプトに貼り付け、「このリストを「日本語学校リスト」と呼ぶね。」と命名して送信する。
b.次に、「日本語学校リストから、●●●な学校を3つ上げて」と質問する。
c.その回答を記録し、bに戻って繰り返す。
4.2 比較結果は内部RAGの圧勝
次の表は、内部RAGで得られた回答結果をまとめたものです。
緑に塗った部分は妥当な回答です。

「仏教に関係している学校」という問いに対し、OpenAI、Anthropic、Googleのいずれのモデルも、妥当な回答を返しています。ChatGPT-4は、「他の学校の記述には直接的な仏教関連の言及は見られませんでした(中略)。このリストから、他に明確に仏教と関連付けられている学校は見つかりませんでした」と1校だけ回答しています。他のモデルは奈良にあるから仏教に関係するかもとか、「分かち合いの精神」とあるのは仏教に関係するかもなどの理由で2位以下を上げています。
「受験校」という問いには、OpenAI、Anthropic、Googleのいずれのモデルも、妥当な回答な回答でした。ChatGPT3.5、Gemini 1.0 Proは少し劣ります。次に、ChatGPT4における生成AIからの回答を例として示します。いずれのモデルも、単に学校名をあげるだけでなく、その根拠となる記述を引用しています。

「美人が多い学校」という問いには、Gemini 1.5 Pro以外は、美人に関する記述がない、あるいは、美人であるかどうかは主観に属するので答えない、という形で回答を拒否しています。今の御時世では無難な回答と言えます。GoogleのGemini 1.5 Proはすこし挑戦的で、「いろんな国の学生がいる学校では、美人がいる可能性も高いのではないか」と、3校を上げています。
なお、マイクロソフトのCopilotによる回答は、内部の大規模言語モデルがChatGPT4相当ではありますが、回答内容が随分違います。理由はよくわかりません。
OpenAI、Anthropic、Googleの生成AIによる回答は、概ね妥当で、かつ、回答の根拠が示されるのが特徴です。
これに対して、外部RAGでは、回答の精度がかなり落ちます。そして、その根拠も示されません。無論、この回答を生成AIに流し込めば、それぞれそれらしい根拠をつけてくることでしょう。ただ、元のランクが不正確だと、回答に根拠がついても価値は低いと言わざるを得ません。
結果として、外部RAGと内部RAGを比べると、内部RAGが圧勝という状況です。
4.3 課題はコストと日本語対応
さて、性能は大規模言語モデルによる内部RAGの方が上という結果が得られました。
問題は、コストです。
Embedding APIによるコストは
・知識ベースを取り込む1回しかコストがかからない
・単価も安い
となっています。
コストメリットは大きいです。
特に大量の検索トラフィックが予定される場合は、今後もEmbeddingを使わざるをえないと予想されます。
大規模言語モデルによるコストは
・毎回回答生成する毎にコストがかかる
・単価は一般に高いが、安いものもある
となっています。
AnthropicのClaude 3 HaikuやGoogle Gemini Proは選択肢に入る可能性があります。
また、Gemini 1.5 Proに無料モードが設定されるかどうかも注目です。
Embeddingについては、次のような運用の改善が進んでいます。
・コンテキストウィンドウが小さいので、それに合わせて文書(知識ベース)を分割してベクトル化する
・全文検索とベクトル検索を併用したり、文書の分割の最適化、Bing検索のノウハウを反映したセマンティックランク付け機能により回答の精度を向上させる技術(Microsoft Azure AI Search(旧Cognitive Search))
大規模な企業向けシステムでは、Azure AI Searchなどの検討が必要になると予想されます。
一方で、Embeddingのモデルそのものも改良が進んでいくと予想されます。
特に、VoyageAIのマルチリンガルモデル(日本語対応)がどの程度の性能かによっては、Embedding APIの選択肢は広がるでしょう。
<技術情報>
Embeddingがどのような特徴に注目して次元を構成するかによって、言葉の含みや細かいニュアンスを表現できるかどうかが決まります。
Embeddingの次元は、学習データと学習アルゴリズムに基づいて自動的に構成されます。従来のEmbeddingモデル(Word2Vecなど)では、単語の共起情報(どの単語がよく一緒に出現するか)に基づいて次元が構成されました。これにより、単語の意味的な関係性を捉えることができましたが、度合いの大小や詳細なニュアンスを表現することは困難でした。
しかし、最近のより高度なEmbeddingモデル(BERTなど)では、単語の共起情報だけでなく、文脈や単語の位置関係なども考慮して次元が構成されます。これにより、単語のより詳細な特徴や含みを表現できるようになってきています。
例えば、「銀行」という単語を考えてみましょう。従来のEmbeddingモデルでは、「銀行」と「金融機関」の類似度は高くなりますが、「銀行」が「川岸」という意味で使われているのか、「金融機関」という意味で使われているのかを区別することは難しいでしょう。
一方、文脈を考慮した高度なEmbeddingモデルでは、「銀行」が「川岸」という意味で使われている場合と、「金融機関」という意味で使われている場合で、異なる次元の値を持つことができます。これにより、単語の多義性や文脈に応じた意味の違いを表現できるようになります。
このように、Embeddingモデルの性能は、その内部で何に注目して次元を構成するかに大きく依存しています。今後、自然言語処理の研究が進むにつれ、より高度なEmbeddingモデルが開発され、言葉の含みやニュアンスをより細かく表現できるようになることが期待されます。
5.まとめ
この記事では、RAGの基本的な概念をおさらいした上で、外部RAG、内部RAGの考え方を示しました。
そして、外部RAGに使うベクトル検索の中心技術であるEmbeddingとRetrievalの情報処理について、ベクトル化、コサイン類似度を中心に説明しました。
さらに、EmbeddingとRetrievalを、Googleスプレッドシート上のハンズオンで追体験しました。
最後に、外部RAGと内部RAGの性能の違いや課題についてまとめました。
記事の通りやってみたがうまくいかなかったという方、コメント下さい。
うまく行った方は「いいね」お願いします!
この記事は、大阪のIT専門学校&日本語学校「清風情報工科学院」の校長・平岡憲人(ノリト)がお送りしました。
清風情報工科学院では、生成AIを若者に教えたい、生成AIを教育に活用して能力開発したい、というスタッフを募集しております。
ノリトについては、こちらの記事を。
よろしければサポートお願いします! いただいたサポートはクリエイターとしての活動費に使わせていただきます! (