
Pythonプログラミング・ノート

先日入手したPythonの解説書が実践的なので、早速、実務でPythonコードを活用してみた件。
Python初心者なので、これがPythonプログラミングの作法に則っているかは甚だ疑問であることを御留意されたし。
元ネタはこちら
複数のcsv/tsvファイルを一つのエクセルにまとめる
参考にしたコードは、"csv_files_to_book.py(Page.144)
<仕様>
・”売上月別”フォルダに登録された、’’4月売上.csv”/’5月売上.csv”/’6月売上.csv”ファイルを順次読み込み、”第1四半期売上.xlsx”ファイルに作成した、入力ファイルと同名のシートにそれぞれのデータを取り込む。
<要求変更追加仕様>
任意のフォルダの下に月別のサブフォルダがあり、その中に複数種類のファイルが保管されている。同一種類のファイルは全て同じ名前。これらを全て取り込む。
入力ファイルは、csvではなくtsv形式。
一度に複数種類のファイルを読み込み、種類毎のエクセルシートにまとめる。
元データ量が大きいので、特定条件のものだけを抽出する。
抽出条件は、ハードコーディングするのではなく引数で与える。引数の数やサイズ、形式等をチェックする。
数値項目は、編集してint型、もしくはfloat型に変換する。
同一ファイル名であるにもかかわらず、レイアウトが変わった場合には、別のシートに纏める。(シート名に枝番を付加する)
プログラムの開始の表示/読込対象ファイル名毎の読み込み数と、抽出条件に合致してシートに出力された件数を随時表示/レイアウトが変わった場合の表示/プログラムの終了の表示
データファイルの1行目は、項目名のリスト。2行目からデータ。
データファイルはData_AとData_Bの2種類。
1. 任意のフォルダの下に月別のサブフォルダがあり、その中に複数種類のファイルが保管されている。同一種類のファイルは全て同じ名前。
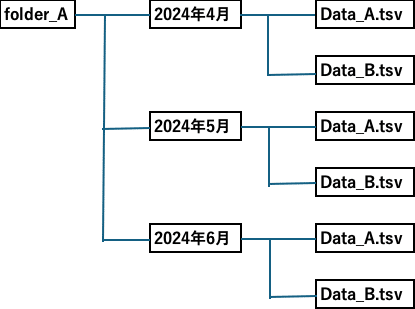
for file in Path("folder_A").glob("**/*.tsv"):"**/*.tsv"の表現で、サブフォルダのすべてのtsvを対象とすることができました。この方法を見つけた時の感想、、、へ〜〜〜
2. 入力ファイルは、csvではなくtsv形式。
ネットで検索するとすぐに解決策は見つかった。
# TSVファイルを開く
f = open(file, encoding="cp932")
reader = csv.reader(f, delimiter='\t')
# TSVファイルを1行ずつ読み込む
for row in reader:delimiter='\t'(区切り文字はタブだよ)と、指定するだけでした。
3. 一度に複数種類のファイルを読み込み、種類毎のシートにまとめる。
4. 抽出条件は、ハードコーディングするのではなく引数で与える。引数の数やサイズ、形式等をチェックする。
実行時に都度、対話形式で抽出条件を尋ねても良いのだが、定型的な作業なのでバッチ処理化することも考慮して、引数で与えることにする。
与えられた引数については、長さやコードの構成(ここでは、長さは3桁の文字、、、など)をチェックする。
import sys
# 抽出条件を確認
args = sys.argv
if(len(sys.argv) <= 1):
print("商品名が指定されていません")
sys.exit()
if len(args[1]) != 3:
print("不正な商品名(" + args[1] + ")が指定されました。(商品名は3桁です)")
sys.exit()
if args[1].isalpha():
product = args[1].upper()
else:
print("不正な商品名(" + args[1] + ")が指定されました。(商品名は文字です)")
sys.exit()5. 元データ量が大きいので、特定条件のものだけを抽出する。
step2で取り込んだ行のリストrowの中の各項目は、左から順番にrow[0]、row[1]、row[2]、、、という名前で取り出すことができるので、抽出条件と比較して一致しないときは読み飛ばすことが出来る。
if row[2] == product:6.数値項目は、編集してint型、もしくはfloat型に変換する。
row[3] = int(row[3])
row[4] = int(row[4])
row[5] = int(row[5])tsvファイル中の数値は文字で表現されているため、エクセルに登録するまえに型変換する。これは、レイアウト毎に数値項目の出現位置が異なるため、レイアウト毎に編集方法を変える必要がある。
7. 同一ファイル名であるにもかかわらず、レイアウトが変わった場合には、別のシートに纏める。(シート名に枝番を付加する)
入力ファイルを精査したところ、同一ファイル名であるにも拘らず、特定の月からレイアウトが変更(項目が追加)されることがあるのが分かった。(レイアウトを変えるなら、ファイル名も変えて欲しいものだ、、、。)
そのまま同じシートに読み込んでしまうと、項目がずれてしまうためデータの集計分析には都合が悪い。
レイアウトの変更を検知したら、コンソールに注意喚起メッセージを表示したのち、別シートに出力先を分けることとする。(ただし、この状態が検出された場合、上記6の処理が正しく実行できていない可能性があるため、注意喚起メッセージを確認したら内容を確認し、必要に応じて上記6に新たなレイアウトに対応する編集をするようにメンテナンスすること)
各種データファイル読み込みのループ開始前に、以下を定義しておくこと
# Data_Aシート
is_first_Data_A = True # Data_Aの最初のレコード読込処理
header_Data_A = [] # Data_Aレコードのヘッダー格納用
sheet_number_Data_A =1 # Data_Aレコードのレイアウトの発生番号
# Data_Bシート
is_first_Data_B = True # Data_Bの最初のレコード読込処理
header_Data_B = [] # Data_Bレコードのヘッダー格納用
sheet_number_Data_B =1 # Data_Bレコードのレイアウトの発生番号データファイル読み込みのループ開始前に、以下を定義しておくこと
is_header_Data_A = True # Data_Aレコードのヘッダーかどうか
is_header_Data_B = True # Data_BレコードのヘッダーかどうかData_Aファイルからの最初のレコード(ヘッダー情報)を読み込むタイミングで、Data_Aファイルのレコード出力用のシートをcreateする。
ヘッダー情報を上記のシートにappendする。
header_Data_Aリストに、ヘッダー情報を格納しておく。
if file.stem == "Data_A":
if is_first_Data_A == True:
is_first_Data_A = False
wSheet_Data_A = wBook.create_sheet("Data_A")
wSheet_Data_A.append(row)
header_Data_A = rowあらたにData_Aファイルを読み込むたびに、is_header_Data_A = Trueとなっているので、読み込んだヘッダー情報(row)と、格納しておいたheader_Data_Aを比較し、レイアウト変更の有無を確かめる。
リスト同士の比較ができるので、容易に確認できる。
変更がある場合には、新たにcreateしたシート名に枝番をつけて、そのシートへレコードを出力する。
(Data_Bファイル用のルーチンも同様)
if is_header_Data_A == True:
is_header_Data_A = False
if row != header_Data_A:
print("*** レコードレイアウトが変わりました (" + file.parent.name +") ***")
wSheet_Data_A = wBook.create_sheet("Data_A" + str(sheet_number_Data_A))
wSheet_Data_A.append(row)
sheet_number_Data_A += 1
header_Data_A = row8. プログラムの開始の表示/読込対象ファイル名毎の読み込み数と、抽出条件に合致してシートに出力された件数を随時表示/レイアウトが変わった場合の表示/プログラムの終了の表示
プログラムの冒頭
print()
print("ファイルの読み込みを開始しました")
print("---------------------------------------------------")一つのデータファイルの読み込みが終了した時点
print(file.stem + " (" + file.parent.name +") read : " + str(read_count))
print(file.stem + " (" + product +") write : " + str(write_count))
print("---------------------------------------------------")
プログラムの最後
print("Data_A (" + product +") write : " + str(grand_total_Data_A))
print("Data_B (" + product +") write : " + str(grand_total_Data_B))
print("====================================================")
print("ファイルの読み込みを終了しました")ソースコード
forやifの範囲指定をインデントで行うという作法に慣れていないので、戸惑いがある。
最初にリリースしたバージョン
※読み込み件数表示で、header行をデータ件数に含むというバグがあります。
下記のAyumiKatayamaさんからの指摘を元に、修正したバージョン
実行してみた
IDLEのShellウィンドウの表示結果。
適切な引数(商品A)で実行
========= RESTART: /Users/akio/Documents/Python/textbook/ch03/sample.py ========
ファイルの読み込みを開始しました
---------------------------------------------------
Data_A (2024年4月) read : 8
Data_A (商品A) write : 3
---------------------------------------------------
Data_B (2024年4月) read : 8
Data_B (商品A) write : 2
---------------------------------------------------
Data_A (2024年5月) read : 15
Data_A (商品A) write : 6
---------------------------------------------------
Data_B (2024年5月) read : 15
Data_B (商品A) write : 4
---------------------------------------------------
*** レコードレイアウトが変わりました (2024年6月) ***
Data_A (2024年6月) read : 22
Data_A (商品A) write : 9
---------------------------------------------------
Data_B (2024年6月) read : 22
Data_B (商品A) write : 6
---------------------------------------------------
Data_A (商品A) write : 18
Data_B (商品A) write : 12
====================================================
ファイルの読み込みを終了しました2024年6月のData_Aファイルで、レイアウトが変わったようです。
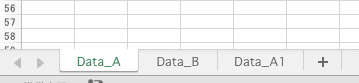
レイアウトが異なるレコードをうっかり混在させる事故を防ぐことができました。
引数なしで実行すると、、、
「商品名が指定されていません」と表示され、処理が終了します。
========= RESTART: /Users/akio/Documents/Python/textbook/ch03/sample.py ========
商品名が指定されていません4桁の引数で実行すると、、、
「不正な商品名(1234)が指定されました。(商品名は3桁です)」と表示され、処理が終了します。
========= RESTART: /Users/akio/Documents/Python/textbook/ch03/sample.py ========
不正な商品名(1234)が指定されました。(商品名は3桁です)3桁の数字ばかりの引数で実行すると、、、
「不正な商品名(123)が指定されました。(商品名は文字です)と表示され、処理が終了します。
========= RESTART: /Users/akio/Documents/Python/textbook/ch03/sample.py ========
不正な商品名(123)が指定されました。(商品名は文字です)まとめ
これまでは、時間をかけて1ファイルあたり数十万件のデータをエクセルに取り込んだあと、フィルタ機能で不必要なデータを削除する作業をマニュアルで行っていた。一つのファイルを取り込んで、しばらく待ち、読込成功を確認して次のファイルを取り込む、、、それだけで半日はかかっていた。
操作ミスして、別レイアウトのファイルを同一シートに取り込んでしまったり、同じファイルを複数回取り込んだり、、、、そのうちPCが固まってしまったり、、、。そういう時に限って、途中で保存してなかったり(泣
このプログラムがあれば、複数種類のファイルを一気に、必要なデータを選択してそれぞれ別のエクセルシートに取り込んでくれる。一度起動したら終了メッセージが出るまで放ったらかしでOK。しかも、上記の手作業より圧倒的に早くて正確。
一度取り込んでしまえば、あとはエクセルのピボット分析機能で、自由な切り口で調査分析ができるというもの。
うーん、大満足!
ここまで読んでいただき、ありがとうございました。
(冒頭の写真は、大津市の柳が崎湖畔公園のイングリッシュガーデンの壁一面の薔薇)
いいなと思ったら応援しよう!
