
仏教経典『ダンマパダ』をテキストマイニングしてみた

はじめに
本記事は思想・哲学・文学・芸術の会のアドベントカレンダー2022用に作成しました。

表題の通り、仏教経典『ダンマパダ』を違った角度で読んでみようと思い、フリーのテキストマイニングツール「KH Coder」を使ってみたという話です。
準備
ダンマパダは中村元先生の『ブッダの真理のことば・感興のことば』(岩波文庫)を使いました。
https://www.amazon.co.jp/ブッダの真理のことば・感興のことば-岩波文庫-中村-元/dp/4003330218
まずテキストデータを準備します。
後でKH Coderに食わせるのに都合が良いのでCSV形式で作成しました。

入力
用意したテキストデータをKH Coderに食わせます。
前処理を始める前に、下図のように、分離されると困る単語を強制抽出リストに、またカタカナで書かれた語句を使用しない語に指定しました。

前処理を実施したら以下の結果が出ました。

全体で866個の文章で成り立っていて、単語の種類が2,096個、文章全体を通して17.451個の単語があるようです。
ではさっそく中身を見ていきましょう。
単純集計
単語のカウント
まず「ツール」>「抽出語リスト」を見てみます。

これは各単語が文章全体で何回使われたのかを示しています。「人」が全体で264回、「心」が全体で90回使われたということですね。これだけでも「人の心について多く語られているんだな」と分かります。
続いて今度は品詞ごとの出現数を見ていきましょう。
「プロジェクト」>「エクスポート」>「抽出語リスト」で品詞ごとの各単語の出現数が見れます。

動詞と形容詞のところだけ拡大してみましょうか。

「たしかに『〇〇を□□と呼ぶのだ』みたいなことをたくさん言ってた気がするな~」みたいな気付きが得られますね。
形容詞では「無い」が一番多いようですが、何が無いと言っていたのでしょうか。調べてみましょう。
KWICコンコーダンス
「ツール」>「抽出語」>「KWICコンコーダンス」を開いて、「無い」で検索してみます。

上の結果の通り、「無い」の前後の文脈を調べることができました。これをこの画面のまま見ていってもいいですが、便利な機能があるのでそれを使っていきましょう。
コロケーション統計
KWICコンコーダンスの結果の右下に「集計」ボタンがあるのでそれを押してみます。すると下図のような「無い」の左側に出現していた単語のランキングが表示されます(ソートは「左合計」を選択しました)。

これで「無い」の左側に出現する単語のランキングを知ることができました。「汚れ」とか「怨み」とか「恐れ」とか、そういったものが「無い」と言っていたことを思い出してきました。
グラフィカルな分析
これまでは出現数がどれだけあるかといった単純な集計値を見てきました。次はいよいよ、グラフィカルな分析をやってみましょう。
共起ネットワーク
「ツール」>「抽出語」>「共起ネットワーク」をから共起ネットワークを作成してみましょう。

これは出現数が多い単語(ノード)に対して、関連性が高い単語どうしを結びつけた(辺)ネットワークになります。ノードの大きさはその単語の出現回数の高さを表しています。
単語間の関連はJaccard係数という値で計算されていますが、細かいことはおいておいて、「線で結ばれている単語は、一緒に出現する傾向が高い」というぐらいの意味で捉えてください。(Jaccard係数自体は簡単な式ですので気になった方は調べてみてください)
結果を見てみると、たとえば「ニルヴァーナ」には「楽しみ」とか「最上」が線で結ばれています。これらはセットで出現することが多いということです。「ニルヴァーナ」がいい意味で語られているということが分かりますね。
共起ネットワークはいくらでも深掘りすることができてしまうので、ほどほどにしておき、別の分析を見てみたいと思います。
対応分析
「ツール」>「抽出語」>「対応分析」を選びます。
オプションに「抽出語×外部変数」を選択し、「章のタイトル」を選び、対応分析を実行します。

青色の点が単語、赤色の点が各章のタイトルを表しています。理論的な説明は省略し、とりあえず以下のような見方で大丈夫です。
① 原点(上の図でいうと真ん中らへんの点線の交点)に近いほどあまり特徴がない単語である
② 原点から見て赤い点の方向にあり、かつ原点から遠い単語ほど特徴的である
これを踏まえて見ていきますと、左の方にある「バラモン」は原点から遠いため特徴的な単語であることがわかります。また原点から向かって赤い点「第二十六章 バラモン」の方向にあるので、「バラモン」は26章を特徴づける単語である(言い換えると26章に頻出するがその他の章では出現しないような単語である)ということです。
他にも「愛する」と「象」も同様です。ある章に特有の単語であることがわかりますね。
このように関係性や特徴をグラフに書いてみることで目で内容を知ることができます、その他いろんな可視化機能がありますが、締切も近いのでこの辺にしておきます。
コンセプト分析
最後にコンセプト分析を少し触れようと思います。
これまでは「単語」レベルで解析をしてきましたが、KH Coderの「コーディング」機能を使うことで「コンセプト」レベルでの解析が可能になります。
今回は「死」と「生」というコンセプトについて分析してみます。
関連語検索
「ツール」>「抽出語」>「関連語検索」を使って、近い意味の単語を調べることができます。

これを使って「死」と「生」それぞれのコンセプトに該当する単語を以下のように選びました。
死: 死、死ぬ、死後、寿命、殺す、殺
生: 不死、生き、生ける、生きる、生きもの、生存、生涯、生、生命
コーディング
これをKH Coderに入力するために以下のようなテキストファイルを作成します。これをコーディングルールと言います。

「ツール」>「コーディング」>「単純集計」から、さっき作ったコーディングルール・ファイルを参照し、集計すると以下の結果になりました。
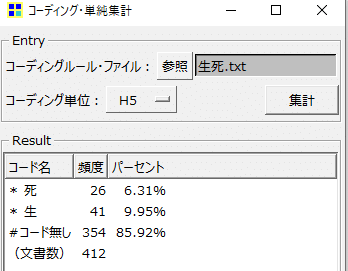
「死」のコンセプトを含む文章が全体のうち6.31%、「生」のコンセプトを含む文章が全体のうち9.95%あるようです。どちらでも無いのが85.92%です。
続いて「ツール」>「コーディング」>「クロス集計」を開き、集計結果からバブルチャートを作ると以下のものが得られました。

□が大きいほど、そのコンセプトの単語が出現しているということです。
たとえば「第10章 暴力」では「死」と「生」が同時に語られているということが分かります。他には「第15章 楽しみ」や「第8章 千という数にちなんで」では「死」よりも「生」が多く語られているといったこともわかりましたね。
終わりに
今回は「とりあえず 締切に間に合わせよう 触ってみよう」というスタンスでしたので、深い分析はせず、さらっと触れただけにしました。
それでも結構見えることが多かったのではないでしょうか?
KH Coderはフリーのツールなので、どなたでも使うことができます。
計量的なアプローチで何か本を読んでみたいと思ったら使ってみてください。