

記事一覧


WSL2でunslothのGPROトレーニングを試してみる
「DeepSeek-R1 の推論を自分のローカル デバイスで再現できるように」「わずか7GBのVRAMでアハ体験を」とのことなので、UnslothのGRPO(Group Relative Policy Optimizatin)トレーニングを試してみます。
今回は Phi-4 (14B)で試してみます。
使用するPCはドスパラさんの「GALLERIA UL9C-R49」。スペックは
・CPU:

画像系マルチモーダルLLMであるQwen2-VLのファインチューニングの練習
はじめにQwen2-VLは、高性能なマルチモーダルLLMです。
本記事では、モデルのファインチューニングを試みてみます。
マルチモーダルLLMを学習するのは初めてなので、色々と試行錯誤がありそうです。
基本的には、以下のマニュアルを真似するだけ作業が完了しました。
(一部、コードを追記修正)
マシンA100(80GB)x2、ubuntuを使います。
ファインチューニングの最低スペックは不明
RAGベースの検索回答エージェントシステム(calm3)の構築メモ
はじめに
これは、RAG(Retrieval-Augmented Generation)をベースにエージェントを動作させるシステムの構築メモです。
課題感
RAGは、大規模言語モデル(LLM)の知識を拡張する上で有益なツールですが、最適な文章を検索するプロセスに多くの課題があります。以下に、具体的な課題とその背景を示します。
専門文書の検索精度
専門性の高い文章では、正しい文献がヒット


【初心者向け】最近のローカル日本語LLM【ローカル万歳】
はじめにOllama Open WebUIやLM Studioのローカルで簡単に利用できる最近の実用的な日本語対応のLLMを紹介しようと思います。※ Python言語を利用してアクセスするのではなく、「モデルのダウンロードとGUIソフトウェアの設定」で実行できるものです
Open WebUIの詳しい導入方法は下記事で紹介しています。
公式レポジトリはこちら
Qwen 2.5中国アリババ社の


Qwen2-VL-7B-InstructのLoRA
OCRなどで高性能と話題のQwen2-VL-7B-InstructをLoRAしたのでまとめました。
LoRAにはこのライブラリを用います。
環境としてDockerを用いました。
自分が使ったコマンドは以下です。
docker run -it --gpus all -v $(pwd):/mnt/workspace registry.cn-hangzhou.aliyuncs.com/models

いちばんやさしいローカル LLM
概要ローカル LLM 初めましての方でも動かせるチュートリアル
最近の公開されている大規模言語モデルの性能向上がすごい
Ollama を使えば簡単に LLM をローカル環境で動かせる
Enchanted や Open WebUI を使えばローカル LLM を ChatGPT を使う感覚で使うことができる
quantkit を使えば簡単に LLM を量子化でき、ローカルでも実行可能なサイズに
LLama2の訓練可能な全層をQLoRAで学習する
はじめにLLama2はMetaが23年7月に公開した、GPT-3に匹敵するレベルのオープンソース大規模言語モデル(LLM)です。
最近はFalcon 180bのような、より大きなモデルも出ていますが、デファクトスタンダードとして定着している感があります
LLMに新たな情報を加える手法として、ファインチューニング、特にQLoRAが注目されています。
しかしQLoRA、特に初期設定では一部のパラ

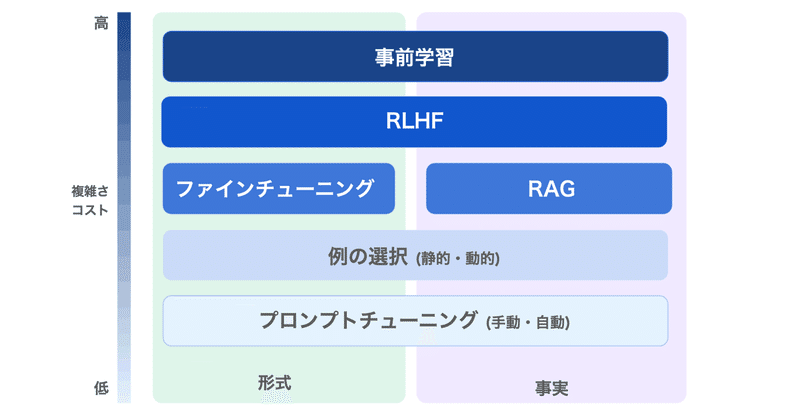
LLMのファインチューニング で 何ができて 何ができないのか
LLMのファインチューニングで何ができて、何ができないのかまとめました。
1. LLMのファインチューニングLLMのファインチューニングの目的は、「特定のアプリケーションのニーズとデータに基づいて、モデルの出力の品質を向上させること」にあります。
OpenAIのドキュメントには、次のように記述されています。
しかし実際には、それよりもかなり複雑です。
LLMには「大量のデータを投げれば自動
Llama2-70b-chatで専門テキスト(学会の予稿集)をファインチューニング(QLoRA)
概要23年8月時点におけるオープンソース大規模言語モデルの筆頭とも言えるLlama2を使い、専門テキストをファインチューニングした際のメモです。
言語モデルに知識を追加するのは、意外と難しいということがわかりました。
前提となるコード類は以下の記事などを参照
学習データ筆者が所属している学会の一つである、高分子学会の年次大会(2023年)の予稿集を学習させてみることにしました。
(学会の参加者
llama2のファインチューニング(QLORA)のメモ
2023/11/13追記
以下の記事は、Llama2が公開されて数日後に書いた内容です。
公開から数ヶ月経った23年11月時点では、諸々の洗練された方法が出てきていますので、そちらも参照されることをおすすめします。
(以下、元記事です)
話題のLamma2をファインチューニングします。
QLoRAライブラリを使うパターンと、公式推奨の2つを試しました。前者が個人的にはオススメです。
前提H
llama2のセットアップメモ (ダウンロードと推論)
話題のモデルのセットアップ
Llama2とは商用利用が可能(諸説あり)で、GPT3並の性能を持つ、オープンソースモデルの本命です(2023/7/19時点)
利用方法
いくつかあります
手段1 Metaの公式モデルを使う
登録必要
あまり使いやすくない印象です
13b以上は、GPU並列利用が基本(?)
手段2 Hugging faceの公式連携モデルを使う
登録必要
便利です


airoboros: GPT-4で作成した学習データで微調整した大規模言語モデル(ほぼgpt-3.5-turbo)
Self-Instructの手法でGPT-4を使用して生成された学習データを使って、ファインチューニングされたLlaMA-13b/7bモデルが公表されていました。
モデルの概要Self-Instructの手法でgpt-4、またはgpt-3.5-turboを用いて、人間が生成したシードを含まず学習データセットを作成(OpenAIライセンスの対象)
airoboros-gpt4
airoboro