
アンケート調査結果の形態素解析について

どうも、分析屋の東雲(しののめ)です。
前回は、アンケート調査結果とそれを形態素解析したワードリストデータを使って、可視化の手法について解説しました。
今回は、「アンケート調査結果から形態素解析をどのように行ったか」を補足的に解説しようと思います。
まだまだこの領域については手探りな部分が多いので、このやり方良いよというものがありましたらコメントなり引用リポストなりで教えてくださると嬉しいです!
ちなみに一連の作業のための課金は特にしておらず、少々力技っぽいやり方もしています。
サンプル数が100と少なかったため可能でしたが、膨大な量を処理する場合は大人しく課金するか他のやり方を探すのをお勧めします。
データについて
■元データ
元データは前回同様、こちらのアンケート回答データです。

よくある口コミサイトのようなイメージで、いくつかの有名な飲食チェーン店に関して、
回答日時、回答者の属性、複数の項目での0~5までの評価点、自由回答でのコメント といった内容が記載されています。
このデータのN列部分が自由回答の内容であるとして、これを形態素解析していきたいと思います。
■欲しいアウトプット
形態素解析を行った後のデータはどんな情報がまとまってほしいかを考えます。
今回は以下3つのデータを取るようにしました。
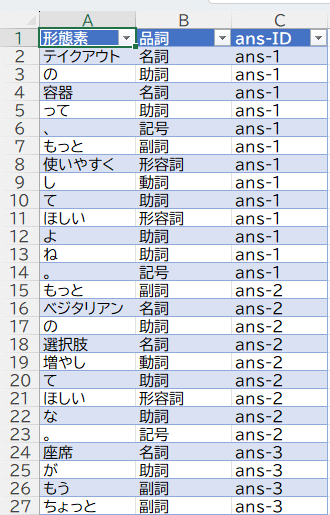
「形態素」列:自由回答の文章を形態素解析した結果
「品詞」列:その形態素がどのような品詞に当てはまるのかの情報
「ans-ID」列:元のアンケート回答のid
試行錯誤①:MeCabを使ってやってみる
まずは自力でやってみたいよねということで、形態素解析処理によく使われると聞くツール「MeCab」を使ってやってみました。
MeCab公式サイト
【余談】
Wikipediaによると、MeCabという名称は「和布蕪(めかぶ)」から由来しているそうで、
他にもJUMANやJanomeなど、日本語由来の名前のツールが多くて面白いですね。
さて話は戻り、MeCabも形態素解析も初めて扱うため何からやったらよいのかすらわからず、
とりあえずわかり易そうなYoutube動画を参考にしつつ手を動かしてみました。
以下動画が、環境構築から実際の処理まで基本的なことを解説していてわかりやすかったです。
【Pythonプログラミング】MeCabで形態素解析!自然言語処理の第一歩!〜初心者向け〜
上記動画を参考に、以下の様に簡単な形態素解析の処理を作成してみました。
形態素解析を行う対象データは1つだけのシンプルな内容です。(処理の詳細については上記動画で解説されているのでぜひご確認ください)

ターミナルでファイルを実行すると、無事結果が出力されました。

ではこれをベースに、今度は複数の文章を対象に処理の作成を試みました。
が、ここで躓いてしまいました…。
対象文章のリストを作ってfor文で回せば行けるやろ〜と思っていたのですが、思い通りには行かず。。
自力でサンプルすべてを処理するのはまだまだ時間がかかりそうです。
試行錯誤②:AIにお願いしてみる
自力でできないなら他力で解決を図ろうと、最近お友達になろうと頑張っているchatGPTさんに形態素解析を依頼してみました。(無課金の3.5です)
多分、プロンプトエンジニアさんに見せたら怒られそうなくらい雑な書き方をしていると思いますが、
まずはシンプルに「以下のテキストで形態素解析してください」でお願いしてみました。
※このやり取りの前に何度か試行錯誤していて、最初は品詞情報がなかったので「品詞情報を【テキスト[品詞]】の形で追加して」の様に出力形式を指定したりしていました。
それを学習してくれたのか、以下のやり取りでは「形態素解析して」だけで出力もこれまでに習った形式をしてくれているようです。

無事、形態素解析をしてもらえました。さすが賢いですね。
そして愚かな人間こと私は「形態素ごとのテーブル形式で出してほしいな〜」という欲が出てきます。
そしてそのままプロンプトをあれこれ試すも上手いこと行かず、またも躓いてしまいました(愚かだ…)
じゃあ気分を変えて、お願いするお友達を変えよう!ということで、Windowsに最近導入されたCopilotさんに同様の依頼をしてみました。
テーブル形式で出してほしい旨と、列名の指定も追加しています。

いい感じに加工しやすそうなデータを出力してもらえましたので、これをコピーしてExcelに貼り付けます。
データ>区切り位置を選択
➡1つ目の画面で、「コンマやタブなどの区切り文字によってフィールドごとに区切られたデー」を選択
➡2つ目の画面で、区切り文字の「その他」だけにチェックをいれ、「|」を入力(Shift + ¥)し完了。
すると、列ごとにセルを分けることができました。

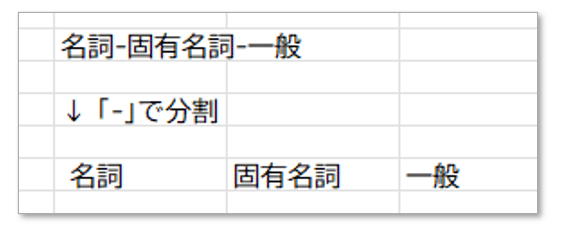
同様のやり方で、「品詞」列の内容を以下の様に分割しました。
可視化後の品詞フィルターでは「固有名詞」「一般」の様な細かい情報は省略して「名詞」「形容詞」など一番上層の内容だけを使いたいためです。
そして、当初欲しかった「形態素」「品詞」の列を残して、不要な列は削除します。
ここまででこんなデータができました。

あとは元データの「ans-ID」を付け足しますが、ここで17行目の「EOS」という値に注目します。

これは、Copilotが形態素解析結果を出力する際に、1つの文章の終わりに区切りとして付け足したものかと思います。今回はこちらを利用しましょう。
形態素解析の出力順は、入力した文章を上から処理して出力している者と思われるので、出力されたデータを1文章ずつ区切って上から1,2,3…とナンバリングをすることができれば、元のIDを再現できるかと思います。
(違ったらこのやり方は不完全なので、違うやり方考えないとですが、一旦問題なしと仮定して進めます)
Excelにて、以下の様にナンバリングの計算式を入力します。
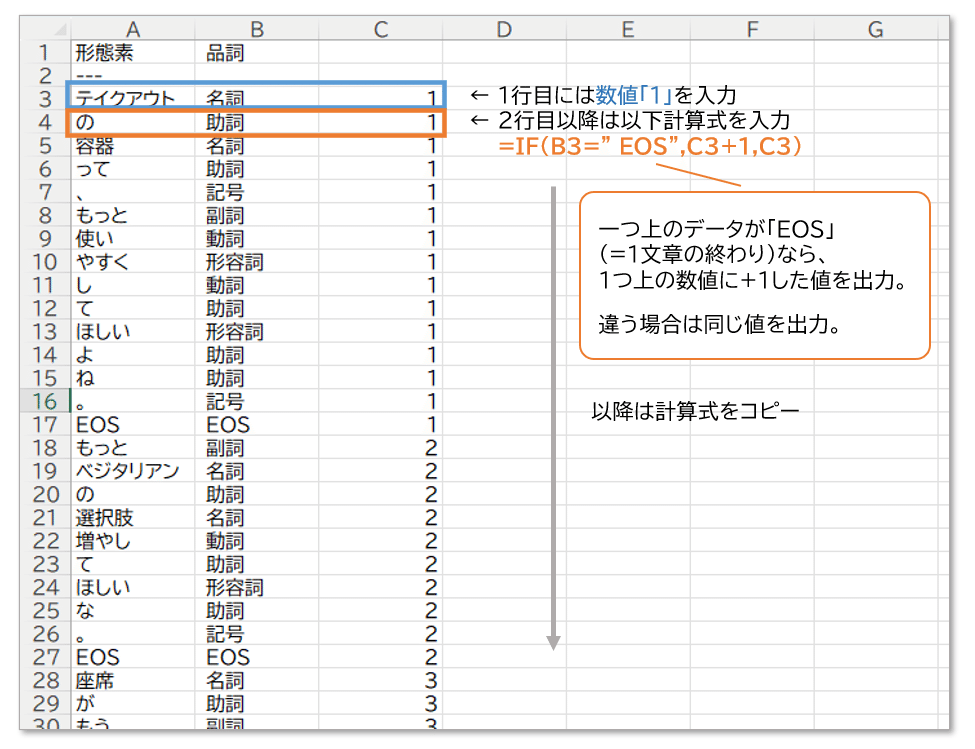
これで、1文章ごとに番号を振ることができました。
これに文字列「ans-」を付け足すことで、ans-IDと同じ値にします。
念のため、元のデータと比べて見ると、一番最後のデータが元の通り100で、自由回答の内容も一致しています。

これで、可視化に使う全てのデータが用意することができました。
まとめ
いかがでしたでしょうか。なかなか苦戦したうえにあんまり正攻法でもないような気がするので、胸を張っておすすめです!とは言えないのですが、お試しで形態素解析をしてみたい場合はお手軽で良いかもしれません。
最後に、今回お伝えした方法で実際の分析をやる際にはおすすめできない理由として2点あります。
■自由回答の内容を「個人情報」と判断するケースもあるので、無闇にAIに突っ込むのは得策ではない。
➡データの取り扱い方針はプロジェクトごとに異なるかと思うので、AIを利用してOKか都度確認することをおすすめします。NGの場合は前半にお伝えしたようなツールを利用するなどの検討が必要となります。
■無課金でこの手法を行うと、AIのテキスト出力上限文字数までしか一度に出力できないため、複数回に分けて形態素解析を行う必要がある。
➡今回のCopilotで言うと、大体15~20個の文章で出力上限に達してしまうので、5~6回に分けて100個のサンプルに形態素解析をしてもらいました。データ量が多い場合は、AIにExcelで入力・出力する方法等があると聞いたことがありますので、そちらを検討してみるのもよいかと思います。
ケースバイケースで最適なやり方を選べるように、今後も手法を色々と知っていきたい所存です。
ではでは。
ここまでお読みいただき、ありがとうございました!
この記事が少しでも参考になりましたら「スキ」を押していただけると幸いです!
株式会社分析屋について
弊社が作成を行いました分析レポートを、鎌倉市観光協会様HPに掲載いただきました。
ホームページはこちら。
noteでの会社紹介記事はこちら。
【データ分析で日本を豊かに】
分析屋はシステム分野・ライフサイエンス分野・マーケティング分野の知見を生かし、多種多様な分野の企業様のデータ分析のご支援をさせていただいております。 「あなたの問題解決をする」をモットーに、お客様の抱える課題にあわせた解析・分析手法を用いて、問題解決へのお手伝いをいたします!
【マーケティング】
マーケティング戦略上の目的に向けて、各種のデータ統合及び加工ならびにPDCAサイクル運用全般を支援や高度なデータ分析技術により複雑な課題解決に向けての分析サービスを提供いたします。
【システム】
アプリケーション開発やデータベース構築、WEBサイト構築、運用保守業務などお客様の問題やご要望に沿ってご支援いたします。
【ライフサイエンス】
機械学習や各種アルゴリズムなどの解析アルゴリズム開発サービスを提供いたします。過去には医療系のバイタルデータを扱った解析が主でしたが、今後はそれらで培った経験・技術を工業など他の分野の企業様の問題解決にも役立てていく方針です。
【SES】
SESサービスも行っております。