
たった5秒の音声データで自分の声を再現✨GPT-SoVITSとStyle-Bert-VITS2による音声合成モデル作成のコツ❗️自分だけのAIボイスを手に入れよう❗️

どうも皆さん!お風呂は熱めが好きなタイプの女、葉加瀬あいです!
前回、Style-Bert-VITS2を使用した音声合成やAIで簡単に人の感情を理解しながら、テキストを読み上げる方法について解説しましたね!
前回の内容をまとめるとこんな感じになります。皆さん覚えていますか?
Style-Bert-VITS2は、VITS2とBERTを組み合わせた日本語特化型のテキスト読み上げAI(TTS)です。
文章の意味を理解し、感情豊かで高品質な音声を生成できます。自分の好きな声で学習でき、オープンソースで利用可能です。
WindowsでもGitやPythonがなくても簡単にインストールでき、Google Colabでの学習もサポートしています。
音声合成のみならCPUでも動作し、APIサーバーも同梱されています。デフォルトでも感情豊かな音声を生成でき、GPUがなくても音声合成とマージが可能です。
この音声合成AIのモデルを使ったテキストの読み上げに関しては、「どういった学習モデルを使うのか」によって、実際に作成される読み上げの音声ファイルの品質や喋り方や声質などが変わるので、「どれだけ高いクオリティーの音声合成モデルを作れるのか」というのが、とても重要なんですよね!
そこで、前回と今回で、その実際の音声合成モデルの作成方法について解説していこうと思います!
また、前回の記事では、GPT-SoVITSを使ったAIに学習させるデータセット(サンプル音声)の準備方法について解説をしました!
GPT-SoVITSを使えば、数秒の音声ファイルがあれば簡単に音声合成モデルのデータセットを無限に作れてしまうので、とても学習のデータセットを用意するのが楽になります。
一応、要約すると以下のような内容になるのですが、皆さんこちらの内容は覚えてますでしょうか?
自分だけの声で動画コンテンツを作るには、Style-Bert-VITS2とGPT-SoVITSを使った音声合成モデルの作成が有効です。
まずはAIに学習させるデータセット(サンプル音声)の準備が必要で、数分から数十分程度の音声が好ましいです。
多くの人はサンプル音声を十分に持っていないため、GPT-SoVITSを使ってサンプル音声を用意することが今回の趣旨です。
GPT-SoVITSは、ゼロショットTTSと呼ばれる技術を用いて、わずか5秒の音声データから声を再現し、多言語にも変換可能なTTSです。
与えられていない情報や話者の声の特徴なども予測して音声合成を行ってくれるのが大きな特徴です。
前回のおさらいができたところで、ここからは実際に音声合成モデルの作成をやっていきたいと思います!
なお、Style-Bert-VITS2の基本的な使用方法やGPT-SoVITSを用いたデータセットの作成等の理解や準備は完了しているものとして進めていきますので、まだそこの基礎知識や使い方、準備などが終わっていない方は、以下の投稿を参考に準備を進めておいてください。
Style-Bert-VITS2を使用した音声合成やAIで簡単に人の感情を理解しながら、テキストを読み上げる方法について
GPT-SoVITSを使用した、音声合成モデルのデータセットの準備について
なお、私の記事を読む上での注意事項などをこちらで説明しておりますので、以下のプロフィール記事をご一読いただいた上で閲覧するようお願いいたします。
それでは、実際にStyle-Bert-VITS2とGPT-SoVITSを使用した音声合成モデルの学習方法について解説をしていきます!
Style-Bert-VITS2で自分の声を使った音声合成モデルを作る手順
1. GPT-SoVITSで作成したデータセットの加工
まず、学習に必要なデータセット(音声ファイル)に関してです。
前回の投稿の最後の部分でもお伝えした通り、学習には2-14秒程度の音声ファイルが複数と、それらの書き起こしデータが必要です。
つまり、2秒から14秒ほどの短い音声のファイルをいくつか用意すると、いった形になります!
あくまでも目安ですが、大体合計で数分程度から20分ほど位の音声ファイルがあれば良いかと思います!
なので、前回の記事で解説したGPT-SoVITSを使って大体、合計で10分から20分程度の音声ファイルのデータがあることを前提に解説を進めていきます!
まずは、GPT-SoVITSを使用して作成したデータセットをきれいに加工して行きます。
Style-Bert-VITS2のバッチファイルを開いて実行してください。
(画像)

実行すると、ツールが立ち上がりますので、データセット作成のタブを開いてください。こちらで作成した音声ファイルをきれいに加工して、音声合成モデルを作成する用のきれいなデータセットにしていきます!
(画像)
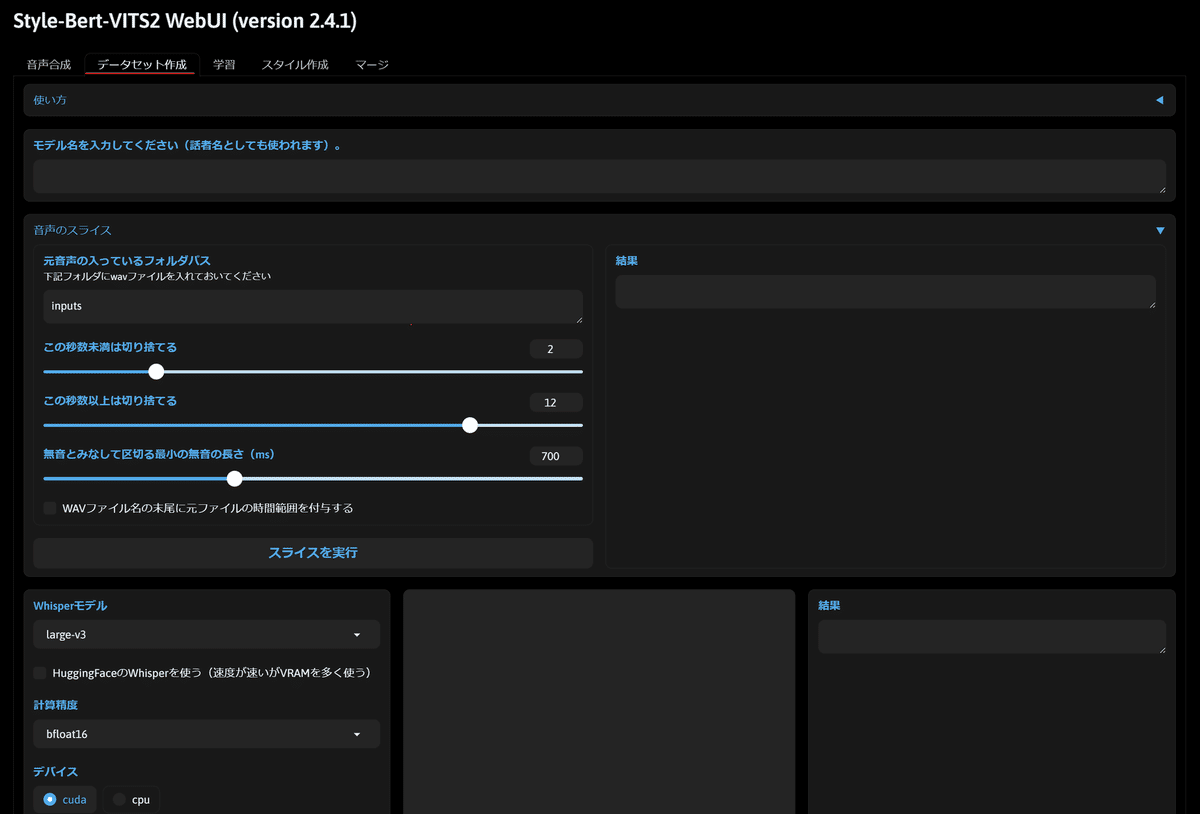
注意: データセットの手動修正やノイズ除去等、細かい修正を行いたい場合はAiviや、そのデータセット部分のWindows対応版 Aivis Dataset を使うといいかもしれません。ですがファイル数が多い場合などは、このツールで簡易的に切り出してデータセットを作るだけでも十分という気もしています。こちらのツールの使い方などに関しては、必要があれば、また別の記事で解説していこうかと思います!
データセットの加工を行うには、まず学習させたい音声ファイルのデータを(Style-Bert-VITS2\Style-Bert-VITS2\inputs)と言う場所に移動させてください。例えば、こんな感じです。
(画像)
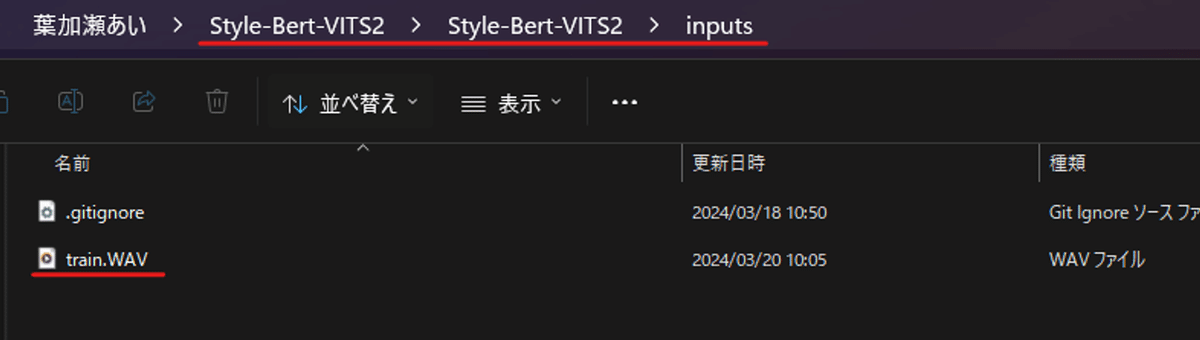
この時、ファイルに無音部分などがあっても、削除してくれるようになったので、特に無音部分の編集をこちらで行う必要は無いかと思います!
また、大体20分位のファイルを1つ用意しても、それを2秒から12秒(デフォルト設定)の間で分割して、複数のファイルにしてくれるので、例えば、YouTubeなどで話している声などのファイルを、こちらに入れるといった形でも良いかと思います!
ここまでできたら、次に先程の画面に戻って、音声構成のモデル名を入力して、スライスを実行をクリックしてください。
(画像)

スライスと言うのは、先ほどファイルを移動させた(Style-Bert-VITS2\Style-Bert-VITS2\inputs)の中の音声ファイルをStyle-Bert-VITS2で処理することができるファイルの長さに切り分けて保存するといった作業になります!
つまりはStyle-Bert-VITS2においては、15秒以上の音声ファイルのデータが無効な学習データセットとして認識されてしまうので、学習されないんですよね。
なので、このスライスと言う作業を実行して、処理できる時間に短縮する必要があると言うことです!
実行すると、スライスが完了した旨の表示が出ます。ここまでできたら完了ですね!
(画像)

Data/{モデル名}/raw 例:Style-Bert-VITS2\Style-Bert-VITS2\Data\AI-Hakase-Test1\raw
と言うフォルダを見てみて、その中にきちんとスライスで作成された音声ファイルのデータが入っているかどうかを見てみてください!
私の場合は、先ほどアップロードした音声ファイルが分割されて保存されています。
(画像)
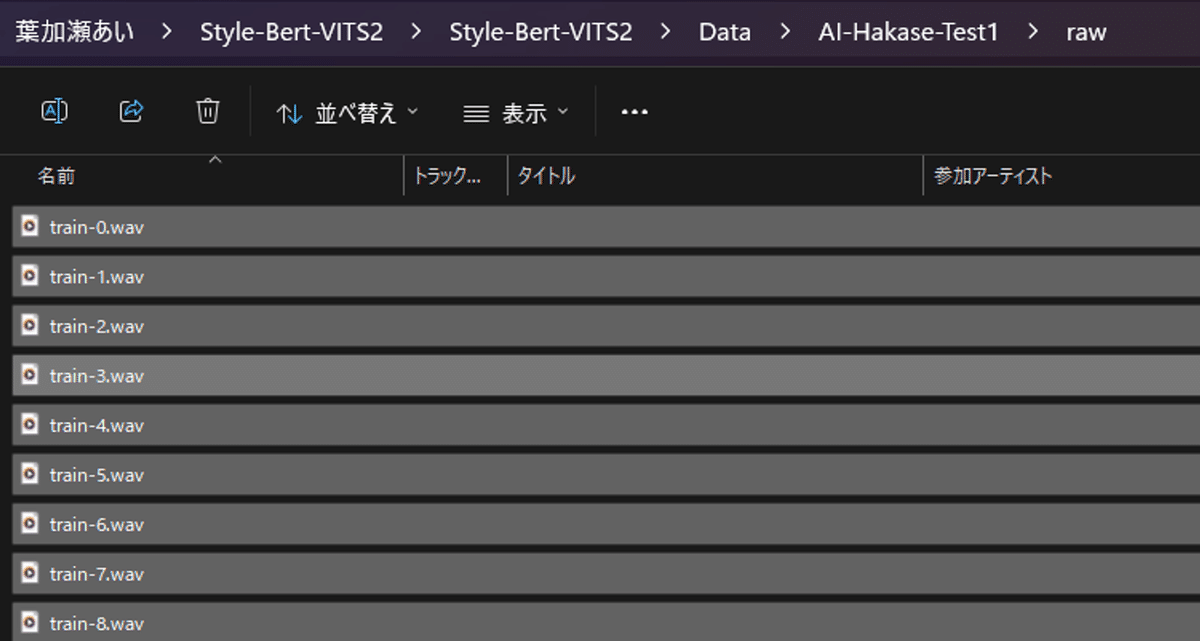
大体20分程度の音声ファイルになっていますね。
(画像)
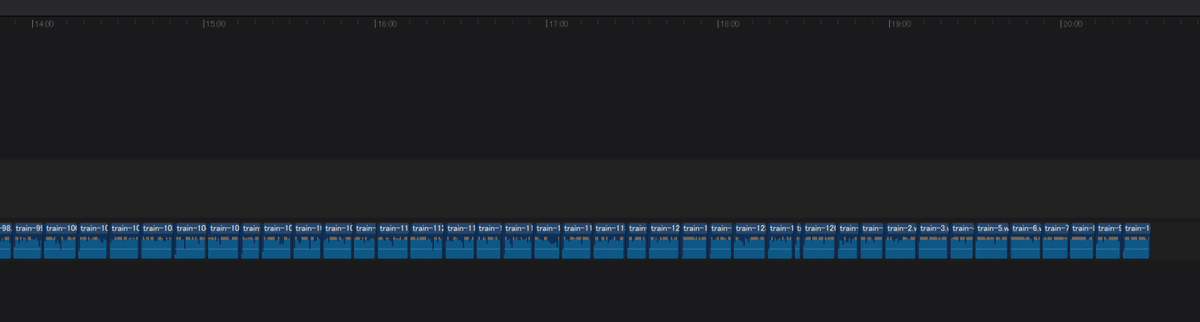
Style-Bert-VITS2のWhisperモデルで音声ファイルの文字起こしを実行
次に、このように作成した音声ファイルの文字起こしをしていきます!具体的には、スライスの下にあるWhisperモデルを使用します。
(画像)
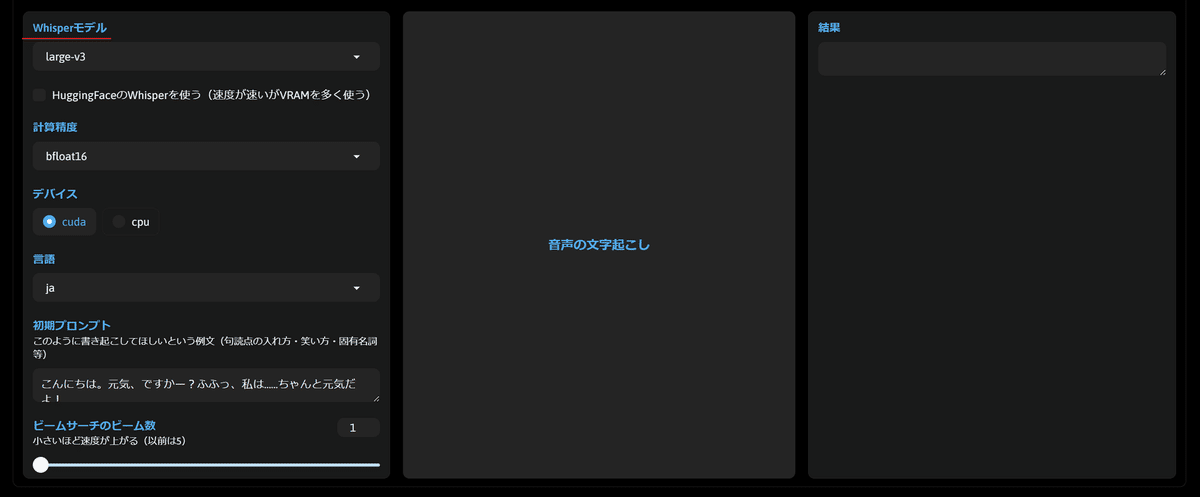
こちらでは、前回の記事で紹介したWhisper WebUIを使用して、音声ファイルの内容をAIが検出して文字として出力してくれます。
なお、モデルや計算精度の項目に関してはそのままで良いかと思います。こんな感じですね。
(画像)

もしこの文字起こしがとても時間がかかってしまう場合は、上の物ほど性能を犠牲にして早く、下のものほど実行時間が遅いけど性能が良いと言うような並び順になっていますので、こちらの中で上のほうにあるものを使用すると良いかと思います。私は今回1番下のモデルを使ってみます。
(画像)

ここまでできたら、音声の文字起こしをクリックしてください。すると、設定項目の内容で先ほど分割した音声ファイルの文字起こしを行ってくれます。
(画像)

この時、何故かエラーが出てしまう場合もあるようなのですが、(Data/{モデル名}/esd.list) の中にこのようなファイルが作られていて、それをメモ帳で開いて、きちんと文字起こしが記載されていれば大丈夫です。
(画像)

(画像)

なお、私の今回の設定で実行した場合は、大体このぐらいのビデオメモリー(VRAM)を使用しました。かかった時間は5分程度ですかね。
(画像)

2. データセットを使った音声合成モデルの学習
ここまでできたら、早速こちらのデータセットを使用して、音声合成モデルの学習を進めていきましょう!まずは、学習のタブを開いてください!
(画像)

一応、こちらで先ほどと同じモデル名を入力して、自動処理を実行と言うボタンをクリックすると、音声構成の学習に必要な準備のようなものを行ってくれるのですが、その前に細かい設定パラメーターについて解説をしておきたいと思います。
(画像)
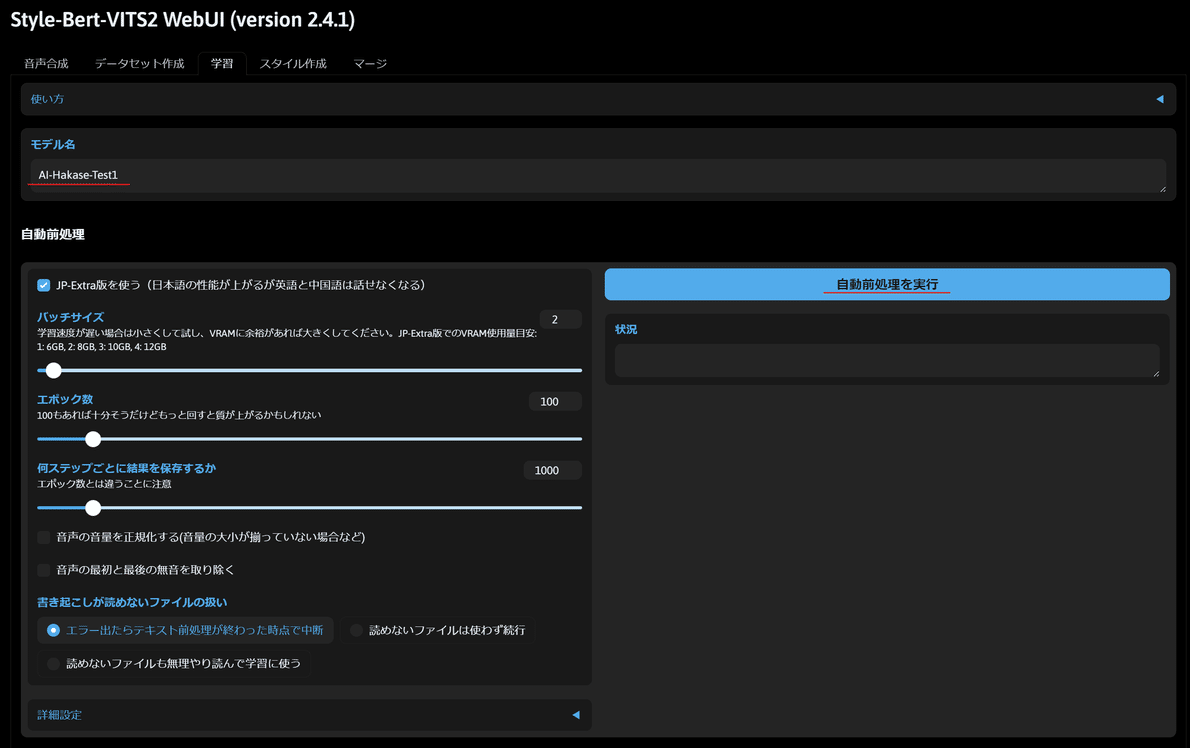
学習に必要な設定パラメーターの解説
設定パラメーター自体は以下のようになっています。
この記事が参加している募集
この記事が気に入ったらチップで応援してみませんか?