
「#未来のためにできること」に応募してみました②「ハードウェア性能のデモンストレーションやBtoBの世界から分布意味論の領域へ」

以下の投稿で「人類の多くは人工知能技術自体の連続的発展ではなく、折り目折り目に現れるインターフェイスのパラダイムシフトに反応しているだけである」という話をしました。
ミクロコスモスの世界がこの有様なのは「部外者」だから仕方ないとして、ならばインサイダーたるマクロコスモスの世界は今日までどの様な展開を遂げてきたのでしょうか。その点に注目したのが以下の投稿となります。
「第二世代人工知能ブームまでの成果の集大成」としてのDeep Blue
人工知能史にそれなりに詳しい人なら誰でも思う事でしょう。「え?たったこれだけのアルゴリズムで人間のチェス名人と戦ってたの?」

主に以下を参照しました。
松原仁「Deep Blueの勝利が人工知能にもたらすもの(1997年)」
Deep Blueは32台を並列に並べた IBMのスーパーコンピュータ SP-2をベースにしていた。32台のそれぞれにチェス専用チップが 16台搭載されているので,Deep Blueには計 512台のチェス専用チップが搭載されていたことになる。この高速コンピュータを用いてDeep Blueは1秒間にチェスの数億もの局面を読むことができた。.
現在のコンピュータチェスは DeepBlueを含めて力任せ探索 (bruteforce search)が一般的である。これはルール上指すことが許されているすべての合法手をメモリと時間の許す限り全数探索で深く読み進めるというもので、チェスの平均分岐数(ある局面における合法手の総数)は約35なので,たとえば 5手先まで読むとすれば35^5の局面を読むことになる。後述する様にaβ法をうまく使えば探索局面は最良の場合で平方根程度まで減らせることが知られている。今回の DeepBlueは毎回平均14手先まで読むことができた。
「チェス専用チップ512個並行稼働」は当時最先端のIBM製スーパーコンピューターSP-2の最大性能だった模様。
4月5日、IBMは新しいPOWERparallel System (9076 SP2)を発表。4月5日Cornell Theory Centerが1号機を買うと発表された。ノードあたりPOWER2 CPUが1個であり、Thin 1, Thin 2 (66 MHz)、Wide 1 (66 MHz)、Wide 2 (77 MHz)の4種のノードがある。最大128ノードまでと発表されていたが、実際には512ノードが可能なようである。
8月、日本IBMはSP2を民間セクターに販売を進めていくと発表。龍谷大学は10月SP2の設置を完了した。日本に設置されたものとしては、動燃(72ノード)、東京都立大(60ノード)、原子力研究所(50ノード)、統数研、分子研、東京理科大学(いずれも48ノード)、東北大学工学部(46ノード)、中央大学(42ノード)、国立がんセンター(40ノード)、キリンビール(48ノード)、工技院化学技術研究所(32ノード)、東北大学(26ノード)、国立環境研(24ノード)など多様なノード数で設置されている。
1994年12月には、第2世代のPowerPC 603とPowerPC 604が登場した。603は32-bit PowerPCアーキテクチャを完全に実装したCPUで、ローエンド向けである。組み込みシステムなどに用いられた。604はサーバにも使える高性能のチップとして設計され、4命令同時実行可能なスーパースカラ・プロセッサであった。Power Macintosh 8500/9500やMacintoshクローンなどに採用された。また、ローエンドのRS/6000サーバやワークステーションにも使われた。1996年7月にはさらに高速化されたPowerPC 604eが導入された。
「αβ法による探索範囲の枝刈り」については以下も参照。
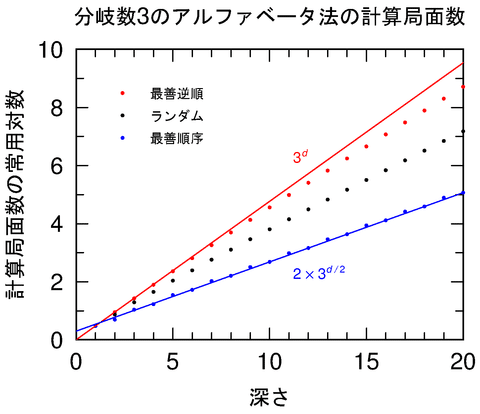
ある意味、Deep Blueは何よりもまずこの技法を研ぎ澄ます事に専念したといえましょう。
Deep Blueは序盤と終盤についてそれぞれ非常に大きいデータベースを有しており,序盤と(最)終盤は探索することなくそれらのデータベースとの照合によって指し手を決定していた。探索を効率化するためにCHESS4.5というプログラムの中で初めて用いられた反復深化 (iterativedeeping) [Slate 77]を採用している。 αβ法では節点の並び方が効率に大きく影響を与える。見込みの高い節点から順番に並んでいるときが最も効率が良<, αβ法の平方根程度にまで減らすことができる.反復深化では,探索木を生成する過程で 1手先を読むたびにその局面を評価関数で評価し評価値が大きい順番にソートして並び換える. 1手ごとに毎回このことを繰り返すのは一見無駄のようであるが,常に見込みの高い節点から探索を続けることになってαβ法の効率が劇的に向上するのである.反復深化は終盤データベースと並んでコンピュータチェスを強くするのに最も貢献した手法と言われている。.
もちろん人間の思考はさらに複雑な構造を備えており、そうした状況への適応も不可欠となりました。
反復深化で力任せにいくら深く読んだとしても,いつも固定の深さまでしか読まないと水平線効果(horizontal effect) によって不都合な事態が生じる。探索木の末端(葉)節点のレベルを水平線になぞらえることにすると,プログラムには水平線の向うは見えないことになる。もちろん人間の強いプレイヤーも水平線の向うは見えないが,水平線のレベルのある局面の評価が「怪しい」と感じると,その局面だけ探索を延長して評価の確認を行なっている.この工夫を選択的深化 (selectivedeeping) と呼ぶ。 DeepBlueは選択的深化の一種である非凡拡張 (singularextension) [Anantharaman 90]を用いている.これはある局面の評価だけがその局面の兄弟(同じ親節点から生成された同レベルの節点)の評価よりはるかに高いときに,その高い局面の先を深く読み進めて確認を取るものである。「うま過ぎるときには注意せよ」という格言に対応する.この機構によりDeepBlueはときに50手60手先まで読む事もあった。
その一方でIBM Deep Blueは単なる「第二世代人工知能ブームまでの成果の集大成」でなく「数理的最適化のみを最優先課題と設定する」新方針へのパラダイムシフトを引き起こした嚆矢でもありました。すなわち歴史のこの時点ではその背後において「人類が天然に備える知性こそ至高」なる観点に拘泥していた既存研究の大量枝刈りが進行し、深層学習の祖たるニューロンコンピューティング技術も危うく「歴史の掃き溜め送り」にされかけたという事を決して忘れてはいけません。

「しぶとく死なないメインフレームメーカー」IBMのサバイバル戦略

AS400(Application System/400)は、高い安全性、安定性、信頼性、拡張性を備えた、オフィス・コンピューター・システムのことで、幅広い機能が提供されてます。このシステムは、1988年にIBMよりリリースされて以降、現在も高い人気を誇っています。
AS400の開発・アップデートは継続的に実施されており、現代のビジネス・ニーズに不可欠なあらゆる機能が提供されています。また、IBMシステムの互換性は高く、レガシーな技術で動作するプログラムも修正すること無くAS400上で実行することが可能です。
このAS400システムは “iSeries" や “System i" など、何度か改称されましたが、現在の最新バージョンは、"IBM Power Systems" と呼ばれています。
2001年2月にも、IBMはLinux関連サービスに今後3年間で3億ドルの投資を行うと発表している。なぜIBMはそれほどまでLinuxに力を入れるのだろうか。なぜIBMはすべてのサーバ製品でLinuxを稼働させようとしているのか。IBMにとってLinuxとは何か。IBMの真の狙いは何か。IBMは単にLinuxのブームに乗りたいだけなのだろうか。
IBMのLinux戦略は、IBMの歴史の中でも重要な戦略転換であると考えられる。また、そこにはIBMの企業体質そのものが大きくかかわっている。これまで、IBMのサーバ製品群、特にメインフレームやオフコン(オフィス・コンピュータ)は、長い歴史の中で、それぞれ世界トップ・クラスのサーバとしての実績を積んできた。業界において、これらの製品群は常にリファレンス・モデルと見なされ、各ベンダはIBMの動向に敏感に反応してきた。ベンダは、IBMが打ち出す数々の戦略や、IBMのメッセージが市場に与えるインパクトについて注意深く観察・研究した。自社戦略や製品への応用を検討し、必要であれば自社の戦略に組み入れてもきたのだ。
さらに、それぞれの製品群ごとにユーザー・コミュニティが形成され、そこに参加する人々は、コンピュータ導入の先端ユーザーの名をほしいままにした。「IBM製品を選定してクビになるシステム担当者はいない」とまでいわれたほど、業界における信用度はほかを圧倒してきた。日本においても、IBMメインフレームの脅威からいかに国産メインフレームを守るか、ということを国策として対応した過去があることは有名な話である。すなわち、IBMサーバ製品は、まさに市場のリーダーであった。
しかし、情勢は大きく様変わりした。Windows NTとIA(インテル・アーキテクチャ)サーバは、彼らのOS/2サーバを事実上撤退に追い込んだ。さらに、ここ数年RISC/UNIXサーバは、米国におけるドット・コムの流れに乗って大きく成長し、特にSun MicrosystemsのEnterpriseサーバ製品は圧倒的な勢いで市場に浸透しつつある。この間、IBMのRISC/UNIXサーバ「RS/6000(現eserver pSeries)」もそれなりに出荷されているが、Sun Microsystemsの勢いには太刀打ちできていない。
一方、IAサーバやRISC/UNIXサーバに押される形で、これまでのIBMの強みであったオフコンやメインフレーム市場は縮小の一途をたどりつつある。
IBMが抱えるさまざまな課題の中で、最も重要な問題は、IBMが過去から積み上げてきた「財産」そのものである。巨人IBMというイメージがあまりにも定着しすぎた結果、内部的にはいわゆる大企業病を招き、外部的にもさまざまな足かせをIBMに課した。このことはすなわち、「昔の強みが今の弱み」に変化した典型的な例といってもよいだろう。これまでIBMは、システムに必要な製品をすべて自社で賄おうとする、垂直構造型企業として成長してきた(実際ほとんどのメインフレーマはいまでもそのような企業体質を持っている)。オープン時代となり、逆にMicrosoft、Intel、Sun Microsystemsといった企業は、水平構造型企業としてオープン環境を自ら生かしながら成長し続けてている。
このように水平型ベンダの存在が大きくなる中、IBMの存在はIT業界の中で、保守的、閉鎖的、官僚的といったイメージで見られるようになっていった。ここで重要な点は、だからといって既存のパートナーや顧客がすぐにIBM離れを起こしているわけではないということである。IBMにとって、ともに歴史を歩んできたパートナーや顧客は依然として重要な存在であり、彼らにとっても、IBMは依然としてITリーダーとして重要な存在である。つまり、IBMと彼らは一体化した一種の共生関係をつくり上げているのだ。
IBMの徹底した顧客第一主義の中で、IBMユーザーやパートナーは発言力を増していった。ここに強い顧客の存在がある。IBMとしても当然重要な顧客、パートナーを失うことはあってはならないし、顧客やパートナーにとっても、先端技術を提供し続け、システム構築・提供を行ってくれるIBMとの縁を切るわけにもいかない。特にAS/400やS/390といったいわゆる独自(プロプライエタリな)システムで長年育ったユーザーにとって、他社システムへの切り替えは非常に大きな壁であり、冒険でもある。IBMのシステムを販売しているパートナーにとっても、これらのサーバは利幅が大きいといったビジネス上のうまみもある。総じて、これらのユーザーやパートナーにしてみれば、自らIBMとの関係を解消する理由はほとんどないのだ。
結果としてIBMは、そのクローズドなコミュニティでのビジネスをあまりに重視しすぎたし、それに慣れすぎてしまっていた。いつの間にか、IBMは水平型ベンダが新たな市場で急成長するのを黙って指をくわえて見ているしかない企業になっていた(実際IBMはISPや通信キャリア系でのビジネスにおいて、少なくとも日本国内では他社に後れをとっていることを認めている)。
垂直構造を水平構造に転換するためにIBMは何をなすべきか。IBMがオープンな企業に生まれ変わるためには、自らオープンな製品を作る必要がある。しかし、IBMの出す製品は市場からはなかなかオープン製品として認知されないというジレンマもある(WebSphereやDB2はここへきてようやくオープン・ソフトウェアとしても認識されつつあるようだが)。このようなジレンマが数年続いた後、最終的にIBMは重要な決断を行った。
その答えが「Linux」である。性能・機能・価格といった単純な製品競争だけでは戦えないと判断したIBMは、自らオープン環境を育て上げ、その中で競争優位に立てる状態をつくり上げることを新たな戦略目標とし、その戦略の中核としてLinuxを位置付けたのである。これまでの閉じたコミュニティのみに頼っていては、サーバ・ビジネスにおける今後の高成長はほぼ絶望的であるが、競争の土俵を変えることで新たな成長は十分に追求できるという思惑が、彼らのLinux戦略の裏に隠されている。
Unix 系OS と IBM i はそれぞれ異なる発展を遂げてきました。
1983年に BSD が、翌 1984年には Linux がそれぞれ TCP/IP プロトコル・スイートに対応し、インターネットを介した相互接続が可能となります。OS/400 のその当時の通信機能といえば 1974年に発表された SNA ですが、実は Unix 系に遅れること 10年後の 1994年(V3)に OS 標準機能としてTCP/IP に対応しました(それまでも追加のライセンス・プログラムとしてサポートはされていました)。
この V3 は新しいファイルシステムとして IFS(統合ファイルシステム)もサポートするという、その後のオープン化に向けた分水嶺となるバージョンとなりました。IFS をサポートすることにより、TCP/IP の各サーバーの実装が可能になり、その後の OSS 対応の道筋をつけたのです。
そしてそれまで独自路線を歩んできた IBM i が、2001年に発表された V5 で AIX のランタイム環境である PASE(Portable Application Solutions Environment)for i のサポートを開始し、オープン化の基本対応が完了します。Linux 系アプリケーションの実行環境の PASE、そのアプリケーションが必要とするファイルシステムとして IFS、さらに他のシステムと通信する標準プロトコル TCP/IP をサポートすることで、IBM i は真の意味でオープンなシステムとなったのです。
もちろん System/3 から繋がる使いやすい OS の系譜は変わりません。それまで使われてきた基幹システムの開発・保守はそのまま稼働させつつ、オープン・システムとなったのです。
ただし、いわゆるオープンソース・テクノロジーを利用するためにはさらに13年を待つことになります。2014年、代表的なオープンソース・アプリケーションをサポートするために、5733-OPS ライセンスプログラムが提供されましたが2019年12月をもってサポートが終了となりました。せっかくのオープンソース・プログラムなのに、導入手段としては IBM i 独自の方法しかないのは使い勝手が悪く、新しいソフトウェアをタイムリーに提供できないとの判断からでしょう。これに変わって採用されたのがRedhat のアプリケーション・パッケージ管理である RPM(RedHat Package Manager)と各パッケージの依存関係を解決して導入を実施してくれる yum(Yellowdog Updater Modified) です。IBM i 上で実行するオープンソース・アプリケーションは、今後 RPM/yum で導入および管理が行われます。
この RPM/yum のサポートで IBM i のオープンソース対応は、Redhat 系 Linux OSと何ら変わらない管理方法ができるようになりました。もちろん、アプリケーションは PASE 環境で実行されるので、Linux のバイナリーをそのまま持ってくることはできず、AIX 用にポーティング(移植)が必要です。しかし、現在では代表的なものはほぼ RPM がアクセスするリポジトリに揃ってきていますし、今後も IBM や各社がそれぞれのリポジトリにポーティングしたバイナリを用意していくことでしょう。
ご存じの方はご存じと思いますが、IBM Power Systemsは、IBM AIX、IBM i、Linuxの3つのオペレーティング・システム(OS)をサポートするサーバーです。このIBM Power Systemsが、2008年4月以前は「IBM System i」と「IBM System p」という2つの製品群に分かれていたのです。
IBM System i は、OSとしてi5/OS(現在のIBM i )を搭載するビジネス・アプリケーション用サーバーであり、日本では「オフィスコンピューター(オフコン)」に分類されていました。なお、IBM System i の「i」はIntegrationを意味していました。
IBM System p は、OSとしてIBM AIXを搭載するUNIXサーバーでした。また、IBM System pはLinuxも導入できたので、UNIXサーバーという記述以上のことを実現したサーバーでした(正確には、IBM System i もLinuxが導入できました)。なお、IBM System p の「p」はPerformanceを意味していました。
具体的な製品を例に挙げて、IBM System i と IBM System p の統合を紹介してみましょう。例えば、IBM System i にはPOWER5プロセッサーを搭載する「IBM System i5 モデル595」がありました。そして、IBM System p には、同じくPOWER5プロセッサーを搭載する「IBM System p5 モデル 595」がありました。これらの2つのシステムが、IBM Power Systemsとして統合された結果、POWER6 プロセッサーを搭載する「IBM Power 595」になったのです。
ただ、OSとハードウェアを一体化した製品群であったIBM System i とIBM System p が、単一のハードウェアに対して用途に応じたOSを導入するIBM Power Systemsに変わったことで、日本IBM社員のみならず、お客様もビジネスパートナー様も表現方法に苦労しました。商標的に正しいかどうかは別として「IBM i on Power Systems」「AIX on Power Systems」「IBM Power Systems(i)」といった書き方で区別していた時期がありました。
もちろん、表現方法の件は一例にすぎません。製品の統合によって直面する様々な課題を鑑みて、入念にIBM Power Systemsの発表内容を練り、体制を整える必要があったのです。
こういった一連の流れの一挿話として「Apple MacintoshのPower PC採用(1994年~2005年)」という話題が挟まってくる訳です。
初代の登場からちょうど10年後の1994年に発売されたPower Macintoshシリーズから、MacもRISCプロセッサーを採用した。IBMとモトローラとアップルが共同開発したCPU、PowerPCだ。もちろん、Power Macintoshの名前に含まれる「Power」とは、この場合、高性能を意味する形容詞であると同時に、CPUの名前を部分的に借用したものとなっている。それほどに、このRISCプロセッサーの採用によるMacの高性能化への期待が大きかったことを示している。
RISCプロセッサー採用の背景には、CISC方式のCPUの性能の伸びが頭打ちになってきたのを打破するという目的があったことは疑う余地がない。ただし、CISCがRISCに対して原理的に劣っているかと言えば、必ずしもそうではないのも確かだ。その反証としては、Windows PCは、登場以来一貫してインテルが設計したCISC方式のCPUを採用し続けていることを挙げれば十分だろう。CISCかRISCかという区分は、あくまでも命令セットの特徴であって、必ずしもCPUの中身のアーキテクチャを特定するものではないとも言える。実際にインテルのCISCは、多段パイプラインなど、当初はRISCのアーキテクチャに特徴的なものと思われていた機能を取り込んで性能を向上させた。
それでも、RISCが登場した当初は、確かにCISCに対して構造的な利点を備えていた。それによって当時のMacは大きな性能向上を果たしたのも間違いない。しかしCPUの性能は、命令セットの特徴だけで決まるものでもない。RISC登場後のCISCも、休むことなく進化を続け、RISCとCISCは熾烈な性能向上競争を継続することになる。その過程の中で、RISCかCISCかといった命令セットの違いよりも、製造プロセスの違いが性能に与える影響が相対的に大きくなっていく。そしてその結果、PowerPCの性能向上にも陰りが見られるようになっていった。
そんな中、Macが2度めの大きなCPU変更に踏み切った。こんどはこともあろうに、Windows PCと同じインテル製のCPUに乗り換えることを発表したのだ。ジョブズがアップルに復帰して、再びアップルがかつての栄光を取り戻し始めていた2005年のことだった。これは前回とはまったく逆に、RISCからCISCへの転換だった。この発表は、少なからず驚きを持って迎えられた。実際の製品として登場したのは、そのショッキングな発表の翌年、2006年に発売された現在のフォルムに近い平板タイプのiMacが最初だった。
最初の68000シリーズの時代がほぼ10年、それからPowerPCの時代もだいたい10年続いたのに対して、インテルCPUの時代は15年ほども続いたことになる。今のところMacが同じ系列のCPUを使用し続けた年月としては最長のとなっている。この間も、もちろんCPUと、それに伴うMacの目覚ましい性能向上は続いた。しかし、Macの性能向上の主な要因であるCPUは他社製だった。しかも、それを製造、供給しているインテルは、アップルにとってはライバルとなるPCメーカーにも同様のCPUを提供している。
仮にインテルが、アップルに対して優先的に新しいCPUを供給してくれることがあったとしても、多少の時間差があるだけ。それほど時間が経たないうちに、CPU性能に関しては、どのパソコンメーカーも同じになってしまう。これではいつまで経っても性能面でアップルが絶対的な優位に立つことはできない。また生産量が限られる高性能CPUの供給量や価格を考えると、パソコンの性能が技術的な問題よりも、むしろ政治的な駆け引きで決まってしまうという状況を避けることが難しくなるのは必然だった。
そして技術的にも、さらには政治的にもブレークスルーとなるような大きな転換として採用したCPUが、まだ記憶に新しいApple Siliconだ。このCPUは、分類上は紛れもないRISC方式となる。今のところ、同じクラスのマシンでは大きな性能向上を果たしていることから、少なくとも技術的には一定の成功を収めたことが明らかだ。このことから、CPUの設計や製造プロセス、そのたもろもろの技術的な状況は、現在では再びCISCよりもRISCの方が優位になっていると見ることもできる。
しかし、アップルがApple Siliconを採用したことで、最も大きく変わったのは、もっと単純なこと。それは他社製のCPUか、自社製のCPUかということだ。もちろんチップの製造も含めてアップルが実際に「作っている」わけではないが、設計から製品化までのプロセスは、すべて自らコントロールしているはずだ。この事実は、現在だけでなく、今後の発展を考えても、アップルに大きな優位をもたらすことを期待させる。政治的なコントロールの獲得は、技術的な成功を独り占めできることをも意味するからだ。
これまでのMacのように、CISCからRISCへ、そしてRISCからCISCへ、さらに再びCISCからRISCへというCPUの変遷を見ていると、コンピューターとは関係のないある光景が目に浮かぶ。それは、高速道路の走行車線と追い越し車線の車の流れに絶えず気を配り、少しでも空いている方に目ざとくレーンチェンジしながら先を急ぐような車の運転だ。これまでのMacは、そのようにして辛くも優位を保ってきたのかもしれない。しかしこれからは、Apple Siliconという、他の車が乗り入れることのできない専用レーンを用意し、他社の状況には関係なく、常に車の最高性能を発揮できるような運転が可能になったと見ることができる。
全般的に2000年代の事業再編を経てV字回復を果たしたイメージ。その間、顧客流出を免れたのは流石というべきでしょう。そして、ここである種の牽引役を勤めたのが「人工知能でなくコグニティブ・コンピューティング」を標榜するWatson事業だったのです。
ワトソン(Watson)は、IBMが開発した質問応答システム・意思決定支援システムである。その名前はIBMの事実上の創立者であるトーマス・J・ワトソンから取られた。
「人工知能」と紹介されることもあるが、IBMはワトソンを「Augmented Intelligence、拡張知能」、自然言語を理解・学習し人間の意思決定を支援する『コグニティブ・コンピューティング・システム(Cognitive Computing System)』と定義している。ただし、IBMは「Augmented Intelligence」とは特に断りなくWatsonのことを「AI」と紹介している。
2009年4月に米国の人気クイズ番組「ジェパディ!」にチャレンジすると発表された。これは1997年に、当時のチェス世界チャンピオンのガルリ・カスパロフに勝利したIBMのコンピュータ・システムであるディープ・ブルーに次ぐプロジェクトである。しかし、クイズ番組では自然言語で問われた質問を理解して、文脈を含めて質問の趣旨を理解し、人工知能として大量の情報の中から適切な回答を選択し、回答する必要がある。IBMはこの技術を、将来的には医療、オンラインのヘルプデスク、コールセンターでの顧客サービスなどに活用できるとしている。
2011年1月13日にはトーマス・J・ワトソン研究所でワトソンの公開と「ジェパディ!」での人間と対戦デモが行われた。ワトソンは、10台のラックに搭載されたPower Systems 750で構成され、2880個のPOWER7プロセッサ・コアを搭載し、オペレーティングシステムはLinux、処理性能は80テラFLOPS(TFLOPS)で、インターネットには接続されておらず、本・台本・百科事典(Wikipediaを含む)などの2億ページ分のテキストデータ(70GB程度、約100万冊の書籍に相当)をスキャンして取り込んだ。Urban Dictionaryをワトソンが学習したら、発言が下品になったこともあったとされる。
2011年2月14日からの本対戦では、15日と16日に試合が行われ、初日は引き分け、総合ではワトソンが勝利して賞金100万ドルを獲得した。賞金は全額が慈善事業に寄付される。
なお「ジェパディ!」は問題文が読み上げられた後に手元のボタンを押して回答する早押し形式であるが、ワトソンは音声認識機能を持たないため文字で問題を取得し、シリンダーでボタンを押す装置を用いて回答した。
IBMはワトソンを支える質問応答(Q/A)システムの開発に貢献した8つの大学を発表した。
2014年にはSTEINS;GATEとのコラボレーション企画として、コグニティブ・コンピューティング紹介するショートアニメ『STEINS;GATE 聡明叡智のコグニティブ・コンピューティング』が公開された。
2015年にはWatsonが各国の料理のレシピ、食品の香りや組み合わせ、嗜好性に関する心理的なデータを解析することで制作したレシピが出版され、日本ではレシピを実際にシェフが調理するイベント開催された。
日本市場へ投入を目指し、2015年から日本IBMとソフトバンクテレコムが共同でワトソンの日本語学習やAPIの開発を行う共同事業をスタートさせた。
2016年8月、ワトソンが患者の正確な白血病の病名を10分で見抜き、割り出した病名に対する適切な治療によって患者の命を救ったと報道される。
コグニティブって知ってる?AIとは違うIBMの目指す世界とは
2011年に、米国のクイズ番組で鮮烈デビューを飾ったIBM Watsonは、「コグニティブ・コンピューティング・システム」と呼ばれている。コグニティブと聞いてピンとこない人もいるだろう。それもそのはずだ。「コグニティブ」は、IBMが提唱した新しい概念で現在人工知能の分野で注目を集めているとはいえ、一般社会の中にはまだ浸透していない。
コグニティブとはなにか。コグニティブ(cognitive)は日本語で「認知」と訳す。Wikipediaによると、「認知」とは、「(人間などが)外界にある対象を知覚した上で、それが何であるかを判断したり解釈したりする過程」だ。つまり、Watsonのような「コグニティブ・コンピューティング・システム」とは、与えられた情報を処理する単なる機械ではなく、人間のように、自ら理解・推論・学習するシステムである。
日本IBMの中山裕之氏(グローバル・ビジネス・サービス事業コグニティブ・ビジネス推進室長パートナー)が「コグニティブ」を分かりやすく説明している。
「従来のコンピューティングの世界では、数値や一部のテキストしか理解することができませんでした。コグニティブの世界では、数値やテキストはもちろん、自然言語、画像、音声、表情、はたまた空気感などもコンピューターが理解することが可能となります。また、これらの情報を理解するだけでなく、これらの情報をベースに仮説を立てて推論し、この結果を自ら学習していきます。言い換えると、従来のコンピューティングでは、同じインプットを与えると必ず同じ回答が算出されましたが、コグニティブの世界では同じインプットを与えても、その状況に応じて違うアウトプットが導き出されることもあり得るのです」
そう、IBMは紙の時代の終焉を予想してパロアルト研究所で「世界初のワークステーション」Altoを開発しながらその優位を活かせなかったゼロックスの前轍を踏む事はなかったのでした。
それにつけても「Big Brother Watson」が本当に思わぬ姿で復活…

そして遂には生成AI分野にも進出…
三井化学は、2022年6月から、IBM Watsonによる新規用途探索の全社展開をスタートしています。これまでに、20以上の事業部門がIBM Watsonを実用し、100以上の新規用途を発見したという成果が上がっており、今年度は、研究開発やコーポレート部門も含め、更に実用部門を拡大していきます。事業部門の一つのテーマにつき、500万件以上の特許・ニュース・SNSといった外部のビッグデータをIBM Watsonへデータ投入し、更に、三井化学固有の辞書も構築しています。長年の豊富な経験や専門知識を持った、営業・事業領域の現場のスペシャリストが、IBM Watsonを活用して、効率的にビッグデータを分析すること(下図ご参照)で、先入観や既知の知見にとらわれない新規用途を発見することが可能となりました。例えば、SNSデータ分析では、「ある地方電鉄の車中で、カビ臭い」という投稿が多いことを見つけ出し、従来の営業手法では思いつかなかった電車内の防カビ製品の販売活動へと繋げています。
このようにIBM Watsonの新規用途探索において成果は出ているものの、まだ、新規用途の発見には、ある程度の時間が掛かるという課題があります。この課題に対し、先端デジタル技術の生成AIのひとつであるGPTを活用することで、特許やニュース、SNSといったテキストデータから、三井化学が注目すべき新規用途を生成・創り出し、更に、その注目すべきとする根拠や外部環境要因を明らかにして、新規用途探索の精度とスピードをアップさせることで、新規用途の発見を激増させます。
そこで、三井化学と日本IBMは、GPTのひとつであるMircosoftのAzure OpenAI等を活用した実用検証を開始しました。新規用途探索という目的に合わせて、GPTに対する指示を洗練させ、三井化学が注目すべき新規用途候補を特定・抽出します。さらにこの結果をIBM Watsonへ適用してキーワードを絞り込んで分析することで、まだWatson実用に慣れていないユーザーでも、短時間で新規用途が発見可能となります。また、SNS動画も含めたマルチモーダル化を行い、更に、これまでIBM Watsonを活用して発見してきた新規用途の情報をGPTへフィードバックすることで、新規用途創出の自動化の実現を目指します。
OpenAI社と直接ではなくMicrosoft Azure事業経由という辺りが、いかにも大手顧客を十分に囲い込んでいる「マクロコスモスの住人」IBMらしく感じられますね。
OpenAIとMicrosoftは密接な関係を持っています。以下はその主なポイントです。
1. 投資とパートナーシップ:
MicrosoftはOpenAIに対して複数回の投資を行っており、特に2019年の10億ドルの投資が大きな話題となりました。2023年にはさらに大規模な投資が行われ、MicrosoftのOpenAIへのコミットメントが強化されました。
2. クラウドインフラ:
OpenAIはMicrosoftのAzureを主要なクラウドプロバイダーとして利用しています。これにより、OpenAIはその大規模なAIモデルを訓練および展開するための強力なインフラを得ています。
3. 製品統合:
MicrosoftはOpenAIの技術を自身の製品に統合しています。たとえば、OpenAIのGPTモデルは、MicrosoftのOffice製品やAzure Cognitive Servicesに組み込まれ、ユーザーにAIの機能を提供しています。
4. 共同研究:
両社はAIの研究開発においても協力しています。特に、AIの倫理や安全性に関する研究が重要な焦点となっています。
これらの要素により、MicrosoftとOpenAIは互いに補完し合う関係を築いています。MicrosoftはOpenAIの先進的な技術を活用し、OpenAIはMicrosoftのリソースを活用してその技術をさらに発展させています。
置き去りにされてしまった「ヒッピー世代の覚悟」
ここで明らかに面白くなさそうな顔をするのがヒッピー世代の方々。
まさしくヒッピー世代が「(宗教右派の支配地域を全米の隅々まで行き渡らせた)TV伝教」と同じくらい「権力支配の道具」として憎悪した「IBMのメインフレーム」の世界。
真っ先に思い出すべきはリドリー・スコット監督が手掛けた伝説のMacintosh CM「1984(1984年)」が漂わせた殺伐とした空気感…
もし我々が自らの解放を願うなら、まず我々自身が何に支配されているか見定めなければならない。その内容は誕生の瞬間から刻々と飽くことなく進化を遂げてきて、今日ではとんでもないレベルまで精緻化が進んでいる。
マルクスとフロイトは共に、意識及び行動が我々の必ずしも感得していない物理的・心理的諸条件から生じているかについて言及した。現代のテクノロジスト達はそれをさらに発展させ、これら諸条件の巧妙なる操作方法を編み出した訳だ。
あるTVコマーシャルが放送されると、数百万の視聴者達は「何と下らないCMだ」と呟きながら何故そうするか分からないまま出掛けていって、その商品を買ってしまう。これが「動機の研究(Motivational Research)」の成果であり、それによって我々の意識を出し抜いて無意識に直接訴えかけ、我々の行動様式を勝手に望むまま規定し続ける事が可能となった。
また科学的管理法を用いれば我々人間をデータとして記録して調査分析し、そこから得られた情報をコンピューターにかける事で、最適なる技法が算出出来る。これが誰もが論じている情報化時代の正体であり、その実体は情報の巧妙な操作及び支配(Control)に基づく人間管理の具現化に他ならないのだ。
もし我々がそうした経営学的、都市計画的束縛から脱却して解放されたければ、これらの法則を侵犯する突然変異の変種になるしかない。かくしてヒッピーが好んで自らをそう呼ぶ「変わり種(Freaks)」が地上に生を受ける事になる訳だ。
まぁIBMに向けられるこうした偏見は時代を経て弱まるばかりか「本当にそんなシステムの構築が求められたなら、期待に応えられるのはIBMくらいのものだろう」と誰もが想像してしまう形で存続し続けているのです。
POWER2当時では想定し得ない「インターネットを介した動画」「監視カメラ」「自動運転」「5G」に代表される高速かつ大容量のデータ処理を、Power10では特許取得している世界最大のチップ面積と配線層に積載された180億個のトランジスタ、32GT/秒の高速インターフェース、PCIe5のI/O、AI推論技術により可能にしています。皆さまの環境で、実は活用が進まない「監視カメラの映像」や「通話録音のデータ」はありませんでしょうか? Power10を使えば、それらのデータが企業にとって宝の山に化けるかもしれません。
なおこうしたヒッピー世代が「IBMのメインフレーム」と同じくらい毛嫌いした「テレビ伝道者」の話がこちら。
1960年代に公民権運動やベトナム戦争を背景として広がったリベラルな風潮への反動で、70年代以降、聖書の文言を重視するキリスト教原理主義が台頭。その中から妊娠中絶や同性愛に反対し、公立学校での祈りの復活をめざすなど、キリスト教の伝統的な道徳的価値を積極的に擁護する組織的運動が生まれた。この運動を推進する勢力を宗教右派(キリスト教右派)と呼ぶ。
79年にテレビ伝道者ジェリー・ファルウェルが興した道徳多数派(モラル・マジョリティー Moral Majority)は、共和党保守派と結びつきレーガン大統領誕生の原動力となった。やはりテレビ伝道者のパット・ロバートソンが89年に創立したキリスト者連合(Christian Coalition)が、90年代には強い政治力を誇った。その間、家族の価値を守ることを最重要視する「家族フォーカス(Focus on the Family)」「家族調査評議会(Family Research Council)」や「アメリカのために憂慮する女性(Concerned Woman for America)」といった宗教右派団体が次々に結成された。
当時のヒッピーの世界観についてより理解を深めたければ、K.W.ジーター「Dr. Adder(1984年)」や「The Glass Hammer(1985年)」辺りがお勧め。今ではだいぶ入手が難しくなってしまっている様ですが…
こうして成立した「宗教右派」世代もまた「ヒッピー世代」と同じくらい時代遅れの存在と成り果ててしまっているのに、未だ社会的影響力だけは維持している辺りにアメリカ政治のややこしさがある様です。
成熟したIT企業の到達点としての「持続可能な開発目標(Sustainable Development Goals:SDGs)」
人によってはこんな重厚なBtoB話には一才興味がなく、すっかり退屈してしまったかもしれませんが、AmazonやFacebookやGoogleの様な創建当時は「未来への夢に満ちた少数精鋭集団」だったIT企業も成熟するにつれ次第に安定した成長の為にIBMやMicrosoftの様な「安定した顧客の囲い込み」に興味を示さざるを得なくなり、遂には何らかの「持続可能な開発目標(Sustainable Development Goals:SDGs)」を掲げざるを得なくなるものなのです。

ここでいうデータラーニングが「編集加工利用能力の向上例の一つ」に過ぎない事については、以下で説明。
それでは順を追って見ていく事にしましょう。
2006年7月にサービスを開始したAmazon Web Service(AWS)は、スタートアップのインフラストラクチャの中核になった。AWSはHTTP規格が確立されて以降、スタートアップの爆発的な急増の最も重要なイノベーションをもたらしたサービスであると言える。
しかし、Amazonは最初から共通のコンピューティング・インフラストラクチャのプラットフォームを構築しようとしていたのではない。彼らは、ハーレクイーンのロマンス小説、LostのDVDボックスセット、テニスラケットなど何百万点の商品を取り扱うサービスだ。
彼らがコンピュティングサービスに注目したのは、煩雑な配送と受け取りの仕組みを掌握してからのことだ。AWSのプラットフォームは、特定の課題に対して信頼できて愛されるソリューションを構築したことによる副産物として誕生したものであって、Amazonが最初から注力していたものではなかった。
プラットフォームを構築しようと動き出してからも、スタートアップのファウンダーという特定のカスタマーを対象にしていた。医療や金融のプライバシー規制、法人のセキュリティーの懸念点を考慮すると、そこから始めるのは相応しくないと判断し、それらの市場は最初から視野に入っていなかった。そのような多種多様な企業向けのサービスであるとは約束していない。AWSは、急成長するスタートアップにとって本当に必要なものを構築したのだ。
Amazonは1994年創業したが、AWSの提供を開始したのは2006年からだ。そして、AWSで収益が上がるようになったのは2015年からだ。きみのビジネスがもっと短い時間でプラットフォームを作れない理由にはならないが、歴史上最も成功しているウェブ企業に名を挙げられるAmazonでも、プラットフォームになるまで10年以上の歳月が必要だったのだ。ペース配分に気を配ることも必要かもしれない。
テクノロジーは常に特権を独占する少数の人々からはじまります。そしてその中で、それを大衆にまで行き渡らせる人が巨万の富を掴むのです。
クリストファー・スタイナー「アルゴリズムが世界を支配する」によれば、2010年頃よりウォール街からアルゴリズム取引関連エンジニアの大量流出が始まり、それに有名な「Occupy Wall Street運動(2011年)」が続いたのだといいます。流出した人材はほとんどそのままそっくりBig Data業界に流入。統計データに現れる規模で起こった変化だから尋常じゃありません。
Scikit-learnプロジェクトは David Cournapeau によるGoogle Summer of Codeプロジェクト、scikits.learnとして始まった。名前は「Scikit」 (SciPy Toolkit) つまり独立して開発・配布されるScipyのサードパーティ拡張であることを示している。オリジナルのコードベースは他の開発者に後に書き換えられた。様々なScipy Toolkitのうち、scikit-learnとscikit-imageは2012年11月に「well-maintained and popular(よくメンテナンスされており、広く使われている)」と評されている。
2015年以降、scikit-learnは活発に開発されており、INRIA、Telecom ParisTech、そして(Google Summer of Codeを通して)部分的にGoogleの援助を受けている。
2015年11月9日にベータ版がApache 2.0 open source licenseの下で公開され、2017年2月15日には正式版となるTensorFlow 1.0がリリースされた。
元々はGoogle内部での使用のためにGoogle Brainチームによって開発された。開発された目的は、人間が用いる学習や論理的思考と似たように、パターンや相関を検出し解釈するニューラルネットワークを構築、訓練することができるシステムのための要求を満たすためである。現在は、Googleのサービスの研究と生産に使用されており、以前に使用されていたクローズドソースのDistBeliefの役割をほぼ置き換えている。AIにも詳しいルーカス・ビーワルドは、GoogleはTensorFlowのコードをオープンソースにした事で、AIの真の価値はAIの「エンジン」ではなく、AIを賢くするのに必要な「データ」である事を示したと語った。そのためGoogleは「データ」の部分は公開しないだろうと述べた。
FacebookはPyTorchとConvolutional Architecture for Fast Feature Embedding(Caffe2)をメンテナンスしていた。しかし、互換性が無いためPyTorchで定義されたモデルのCaffe2への移行やまたその逆の作業が困難であった。これら2つのフレームワークでモデルを変換することができるように、2017年9月にFacebookとマイクロソフトがOpen Neural Network Exchange(ONNX)プロジェクトを作成した。2018年3月下旬に、Caffe2はPyTorchに併合された。
こうして全体像を俯瞰してみると、開発途上国の課題解決を目指すMDGs(Millennium Development Goals,2000年~2015年)が所詮は先進国にとって他人事で、当事者たる開発途上国に問題解決の意能力も意思もない事からほとんどの目標が達成されないまま2015年を迎えてしまい、それを反省して先進国をも巻き込んだSDGs(Sustainable Development Goals,2015年~2030年)が制定された事と、同時期Googleがモットーを「邪悪になるな(Don't be evil)」から「正しいことをせよ(Do the right thing)」に差し替えた事との思わぬ関連性が浮かび上がってくる様です。
MDGsとは「Millennium Development Goals」の略で、2000年にニューヨークで開催された国連ミレニアム・サミットで採択された「国連ミレニアム宣言」をもとにまとめられたSDGsの前身目標です。
MDGsは、合計8つのゴールと21のターゲットから構成されている2015年までの達成目標です。文言は異なりますが、SDGsの目標にはこれら全てが含まれています。
MDGsでは、人間開発と貧困撲滅をテーマとして、平和と安全、開発と貧困、環境、人権、弱者の保護などの課題に対しての国連がとるべき姿勢について明記されています。
MDGsの誕生によって、それまでバラバラだった社会課題や方策が1つの目標としてまとまったと同時に世界中が団結する基盤ができました。
しかしMDGsは開発途上国に対する「先進国の目線での」目標であったため、世界的なムーブメントまでには至らず、ほとんどの目標が達成されないまま、2015年を迎える結果になりました。

これはまさしく朝倉宗滴の「武者は犬ともいへ、畜生ともいへ、勝つことが本にて候」に代表される戦国武将精神から、天下泰平期の滅私奉公を理想視する忠義堂への推移。この様に「IT企業にとっての幼年期の終わりの到来」と「国際的不平等是正政策に先進国を巻き込む必要性の高まり」が重なって啐啄の機となりSDGsが今の形になったとも考えられそう?
コグニティブ・コンピューティング概念を超越する「人機一体」時代の到来
その一方で人類の可能性はまた別の形で追求が進む展開を迎えました。話をIBM Deep Blueが人間のチェス名人に勝利した時点まで戻します。
ワトソン事業を担当した際に、痛感したことがあります。それは、各社が技術の発展を分かりやすく喧伝するあまり、コンピューター対人間の構図をステレオタイプしてしまった事です。
実際には、Deep Blueプロジェクト当時から、コンピューターは人間の働く環境を改善するものとして社会に受け入れられています。本来、対決の文脈で語られるべきではないのです。
松原仁「Deep Blueの勝利が人工知能にもたらすもの(1997年)」
今回のDeepBlueの勝利に大きく貢献したのが,毎試合ごとに開発チームがDeepBlueのプログラムを書き直して棋風(一種の癖)を微妙に変化させたことである.数万行にもなる巨大なプログラムを短時間で書き換えて性能を向上させるのが非常に困難なことは ソフトウェア工学でよく知られている. DeepBlueの 開発チームはプログラム管理のツールソフトウェアを 作成し 、そのツールを用いて微妙な修正を適切に行なった。Kasparovは毎局違う人間と戦ってい るようだったという感想を述べている。1996年の対戦 では後半 Kasparovに癖を読み切られて DeepBlueが 惨敗したが,今回は DeepBlueの癖を最後まで読み切 れなかったKasparovが負けてしまったの である.
情報理論の大源流が対空砲の管制制御にあり、その全体像が「(観察対象の振る舞いが予測可能となるほど減少する)情報量を可能な限り0に近付ける戦略」を中心に組み立てられる事を知ってる人間なら誰もが「何てズルを!!」「こんなの機械が人間に勝ったうちに入るかっ!!」と思わず脊髄反射で机を叩いてしまうのではないでしょうか。そのあたりはまぁ、当時の人工知能業界はまだまだ「武者は犬ともいへ、畜生ともいへ、勝つことが本にて候(朝倉宗滴)」なる戦国武将精神の段階にあったとでも考えるしかありません。
第二次世界大戦(1939年~)中に「高速化した航空機の振る舞い(右旋回、左旋回、上昇、下降、加速、減速)を予測する撃墜技術」として萌芽した情報理論はノーバート・ウィーナー「サイバネティクス(初版1948年)」が刊行された時点では多くの事象が単純な線形フィードバックの組み合わせで説明可能と考えられていた。
IT企業で当時からあったのはIBMだけで、現在のIBM人工知能事業は当時の社長の名前(一代目も二代目もTomas Watoson)を冠している辺りがまた恐ろしいところ…
インターナショナル・ビジネス・マシーンズ(IBM)社の初代社長。厳密には同社の「創立者」ではないが、1914年から1956年までIBMのトップとして同社を世界的大企業に育て上げた人物であり、実質上のIBMの創立者とされることが多い。
IBM独自の経営スタイルと企業文化を生み出し、パンチカードを使ったタビュレーティングマシンを主力として、非常に効率的な販売組織へと成長させた。一流のたたき上げ実業家であり、生前は世界一の富豪として知られ、その死に際しては「世界一偉大なセールスマン」と賞賛された。
IBM社長となったワトソンは、自身の職務の最重要部分は販売部門の動機付けと心得ていた。セールスマン養成学校のIBMスクールを設立し、前職NCRの販売手法(ノルマ制、歩合制など)など彼の販売理論を教え込んだ。社では彼への個人崇拝が広まり、全社に彼の写真や「THINK」のモットーが掲げられた。社歌ではワトソンへの賛美が歌われた。
1929年の世界恐慌に際しても、ワトソンが導入した賃貸制(機械を顧客に販売するのではなくリースして賃料を得る)により、IBMは新たな販売が滞っても既にリースしている多くの顧客から安定した収入が得られるため、不況にも影響を受けにくい体質ができていた。また、IBMの安定経営を支えるものとしてパンチカード自体の販売がある。顧客は機械が紙詰まりを起こさないようにするためにIBM製のカードを購入しなければならない。これは、カメラも販売するフイルム会社や電気かみそりと替え刃を販売する会社などと同じ発想である。ワトソンは新規販売が激減しても強気で工場をフル稼働させ、大量の在庫を抱えた。しかし、フランクリン・ルーズベルトが大統領となりニューディール政策が実施されるにあたって、全国の労働者の雇用記録を整理する必要が生じ、そこにIBMの在庫が大量に導入されたのである。
第二次世界大戦前においては、主たるビジネスがパンチ・カード機やタイムレコーダーの開発及びセールス(厳密にはリース)であったIBM社を、巨額の先行投資を英断することにより、当時は黎明期にあったコンピュータ産業の巨人へと成長させた。
同時に、他のコンピュータ会社がリース業に参入した際には回収予定時期に「ペーパー・コンピュータ」(新機種の発表予告)をして相手の資金回収を妨害して敵を叩く戦略をとるなど、マーケットにおいては悪辣ともいえる手腕を発揮している。
戦争が終わり、コンピュータに関する新聞記事や学術会議が賑わうようになる。とは言えペンシルベニア大学のENIACを見学した時に、巨大かつ高価で、しかも信頼性の低いこの装置が、いずれオフィス機器になるとは思えなかったと述懐している。IBMもいくつかの原始的な電子計算機を発表したが、それらはパンチ・カード機に取って代わるものではなく、同社の技術力を世間にアピールするデモンストレーション機としての意味合いが強かった。しかしその後、ENIACの開発者であるジョン・プレスパー・エッカートとジョン・モークリーが自分達の会社を設立し、商用コンピュータUNIVACの開発を本格的に開始した頃から状況が一変、パンチマシーンの返品で在庫が山積、IBMの経営陣は危機感を募らせる。
例えば、1980年代の乗っ取り屋であるソール・スタインバーグは、ペンシルベニア大学の卒業論文に「IBMの衰退」についてテーマにするように指導された(自ら調査した結果、スタインバーグは逆に1950年代にIBMはコンピュータ業界において覇権を握るだろうと予測し、卒業後は企業向けのIBM社コンピュータのレンタル会社を興して一財産を築くことになる)。
IBMは朝鮮戦争を契機に、軍に納入するためのコンピュータ開発に巨費を投じる。中でも自身が設立したIBMフェデラル・システムが受注した半自動式防空管制組織(SAGE)はIBMのコンピュータ業界支配の要になったとされ、史上最大のコンピュータと呼ばれている。
1952年の社長就任、1956年のCEO就任及び同年の父ワトソン・シニアの死去に伴い、全面的に経営の指揮を執り始める。1960年代には社運を賭けた汎用コンピュータ、System/360の開発に着手し、成功させる。1970年の心臓発作を契機に体力的な限界を感じ、1971年に引退。
「実はワトソンは二人いた」…まるで「美濃の国取りは斎藤道三一代でなく、父長井新左衛門尉との二代で達成されていた」みたいな話。まさかIT業界でその実例にお目に掛かる事になるなんて…
なのでチェス業界だけでなく将棋業界や囲碁業界でも、人間が人工知能に敗れた後には「逆にその手口を潰して差し手の範囲を広げる」イノベーションが展開する事になったのでした。そもそもそれ以前に…
ディープブルーに敗北を喫したことについて、カスパロフや他のチェスの名手らは、ある一手のせいだと分析していた。第一局の終わり(第二局の最初の一手とする人もいる)に、ディープブルーはある駒を犠牲にする一手を打った。その背後に長期戦に持ち込もうというディープブルーの作戦があるかのように思われた 。
この一手は、コンピューターによるものとは思えない非常に洗練された動きであったため、カスパロフや他の多くの人間が、ゲーム中に何らかの人間の介入があったのではないかとも仄めかしていた。「あれは信じられないくらい洗練された動きだった。守りを固めながら、同時にその後反対の動きをすることを微塵も悟らせないようなものだった 。そして、それがカスパロフを混乱させた」。グランドマスターの称号を持つヤセル・セイラワンは2001年にWiredに対してそう語っている。
あの対戦から15年が経ったいま、ディープブルーの設計に携わったあるエンジニアは、あの動きがバグのせいで生じたものだったことを明らかにした 。
この話は、ニューヨークタイムズ紙にコラムを連載する統計学の専門家、ネイト・シルヴァーが著書『The Signal and the Noise』のなかで明らかにしたもの。ワシントンポスト紙のエズラ・クレイン記者はさっそくこの逸話を書評のなかで紹介している。
シルヴァー氏は同書を書くにあたって、ディープブルーの設計に携わったマーレイ・キャンプベルというコンピューターサイエンティストに取材した。マーレイ氏は同マシンを設計した3人のコンピューターサイエンティストのひとりだが、同氏によると、あの時ディープブルーは次の一手を選択できず、単にランダムに手を打ったのだという 。
当時、ディープブルー対カスパロフの対戦は、コンピューターサイエンスの歴史に残る「世紀の対決」として大きな注目を集めた。そして、人々はカスパロフの敗北を、人間の知性がコンピューターに打ち負かされた屈辱的な敗北として嘆いていた。しかしあの出来事は、人間には物事をおおげさに考えすぎるきらいがあることを示す、ひとつの教訓 だったのかもしれない。
さらには、こんな話まで。
カスパロフはあの対決で大きなハンディキャップを背負っていたと、多くのチェスの名手が長い間そう主張してきた。彼らの考えによると、何度か行われた両者の対決の間に、ディープブルーの設計者らにはプログラムに手を入れる機会が与えられており、それによってカスパロフの戦い方や戦略に適応することができたというのだった。また設計者側では、カスパロフの過去の戦いに関する公開情報をすべて利用することもできた。
それに対して、カスパロフは事実上目隠しをした状態で戦わなくてはならなかった。前の対戦以降、IBM側がディープブルーに大幅な変更を加えていたためで、利用できる情報もなかったからだ。
IBM側が前の対戦終了後に、ディープブルーのアルゴリズムに手を加えたことは事実だった。しかし実際に行われたのはバグの修正 ──予期せぬ動きにつながるようなバグを直すという作業だった。彼らは、ディープブルーが前の試合と同じ間違いをおかさぬように、プログラムに修正を加えた。だが、その時見落とされたバグがカスパロフを混乱に陥れ、それが結局ディープブルーに勝利をもたらした、というのはなんとも皮肉なものである。
「カスパロフは直感に反したあの動きについて、優れた知性の証だとする結論 を導き出した」とマーレイ氏はシルヴァー氏に語っている。「彼はあれが単なるバグの結果だとは考えもしなかった」(マーレイ氏)
本当の変革の波は全く違う形で訪れたのです。
例えば『The AI Revolution in Chess』によると、NNUE導入以降(2018年末以降)、トッププレイヤーたちの間でチェスの序盤と中盤の理解に大きな変化をもたらしているそうである。特に、より長期的な視座で評価できるようになっていて序盤ではGrünfeld DefenseやCatalan opening、Sicilian Defense Najdorf Variationなどでより早い段階で端のポーンを突く、中盤でポーン損の見返りに微妙な駒配置の利を選ぶ(旧来型はNNUE導入後よりも駒得を過大評価する)そうだ。また、この本の6章ではclosed positionについて深く言及されている。
Lizzieの登場に合わせ、囲碁AIを自宅に導入しようとした大橋さん。当初はグラフィックスカードを2枚使ったデスクトップPCを購入しようとしていたが、ここでアクシデント(?)が起こる。自宅で契約している電気のアンペア数が足りず、AIを使おうとすると停電してしまうことが分かったのだ。
「当時は引っ越したばかりでしたし、大家さんのおばあちゃんに相談するのもためらってしまって……。一旦保留にしていたのですが、北京で行われたTencent主催の囲碁大会に行った時に、知り合いの囲碁AIの開発者からAWSを薦められたんです。初期投資がなくていいですし、グラフィックスカードの過熱の心配もないと(笑)。すぐに使ってみようと思いました」
こうして大橋さんは2018年7月にAWSを導入。分からないことだらけだったが、東京・目黒にあるAWS開発者向けのスペース「AWS Loft Tokyo」に足しげく通い、ASKコーナーで質問を繰り返した。さまざまな開発者と話し合い、Amazon囲碁部ともつながり、スポットインスタンス担当だった部長のアドバイスを得て、利用額も大幅に抑えられた。現在は「月に数千円から1万円程度かかっている」(大橋さん)という.
スポットインスタンス…Amazon EC2の機能。AWSサーバ上で使われていない(余っている)EC2インスタンスに対し入札制で一時利用を行う。自らの提示額よりも高い価格で入札されると、すぐに利用を止められるリスクもあるが、一般的な「オンデマンド」制に比べて平均で7~9割引きになるとしている。
AWS活用が軌道に乗ってきた大橋さんは、次に「研究会」を始めようと考えた。ノートPC1台とネットワークさえあれば、どこでもAIを使った検討が行える。その利点を生かし、日本棋院の本院(東京・市ヶ谷)で定期的にAIを活用した研究会「プロジェクトAI」を始めた。現在は10代から30代の若手棋士を中心に、メンバーは25人にまで増えたそうだ。
「高性能のAIさえあれば1人で研究ができてしまうので、実は中国や韓国では今、囲碁棋士の『引きこもり』が問題になっているというウワサも聞きました。しかし、AIが打つ手は自分一人では理解できないことも多い。だからこそ、棋士のみんなで協力して研究できる場があればいいなと考えました。人間を超えたとはいえ、AIが苦手とする局面もまだまだあるのが実情です。そういう部分に関しては、人間と力を合わせて探索を行う必要があるでしょう」
知り合いの開発者の協力も得て、数々の囲碁AIをほとんど使えるようになった。大橋さんが囲碁AIを最新版にアップデートすると「Amazon マシンイメージ(AMI、インスタンスのソフトウェア設定)」として共有するシステムで、LINEを使って研究会のメンバーに配布している。囲碁AIを動かす際はAmazon EC2上で、GPUを利用するP2/P3インスタンスを利用するという。
「P3はP2よりも約3倍高いですが、同じ時間内に探索できる手の数が5倍以上あるので、コストパフォーマンスが高いP3を使う人が増えてきていますね。もっと速くて安いインスタンスが出るのをみんな楽しみにしています」(大橋さん)
研究会のメンバーは囲碁のプロだが、当然ながらAWSについては全員「素人」だ。しかし、大橋さんをはじめとして、AWSのシステムに興味を持ったメンバーが皆に初期設定し、教えて回ったほか、AWSの使い方をまとめたマニュアルを作る棋士まで現れ、今ではメンバー全員が自力でAWSのインスタンスを立ち上げられるまでになったそうだ。
「研究会の中には70代の人もいますが、全員がインスタンスを立ち上げられるようになりました。これは囲碁への知的欲求が原動力になっています。さらにAWSそのものに興味を持つ人が出てきて、さまざまな設定をいじるだけではなく、最近ではパフォーマンスの比較までしてくれます。メンバーの中には、AWS以外にGCP(Google Cloud Platform)を使っている人もいます。TPUで開発された囲碁AIも登場し始めているので、僕自身GCPにもとても興味があります」(大橋さん)
研究会のメンバーには棋士兼学生も少なくない。勉強会に参加しているメンバーであり、ポスト井山五冠を期待される一力遼八段に話を聞いたところ、「研究に使うツールが1つ増えたというイメージ」とこともなげに話してくれた。彼らにとってAIは、もはや特別な存在ではないのだろう。「特に若い子たちは、AIによって囲碁に対する考え方や会話が変わってきている」と大橋さんは話す。
「この手は青い」「いや、緑はどうかな?」「こうなるともう『じんましん』だよね」
最近、AIで研究をしている若手棋士の間では、こんな会話をするのが普通になってきているそうだ。「青」というのは、Lizzie上で示される「AIの第一候補手(最善手)」のこと。その部分が青く光ることからそう呼ばれている。緑は同じように第二候補を指す。
「じんましん」というのは、有力な候補手がなく、AIが全探索モードに入った際、碁盤上の目全てに確率などの数値が表示される状態だ。ソフトウェアの挙動(や仕様)に合わせて、会話で使われる言葉が変わっていくというのは、非常に興味深い。
有力な候補手がない場合は、全ての目に対して探索を行う「全探索モード」に入る。まるで発疹が広がっているような様子から「じんましん」と呼ばれているようだ。
「形勢判断の考え方も変わってきています。囲碁は白黒の碁石によって、囲った陣地の広さを競うゲームです。そのため、これまで形勢判断は、陣地の広さを示す『目』の数で議論するのが一般的でした。
しかし、今はAIによって『この手を打った場合の勝率』が表示されるようになっています。そのため、形勢判断も『何目』から『何%』というように、考え方が変わりつつあるのです。こうした概念の変化を抵抗なく受け入れられている人が、AIをうまく活用できている印象がありますね」(大橋さん)
一方、将棋の世界で起こってる事。
そう、かかる「人機一体の時代」には、人が会話に使う言葉自体が変容していくのです。これこそがまさに分布意味論の醍醐味…
「人機一体の時代」にも残り続けるであろう「ヒッピー世代の心得」
2010年代に入ってなおmemeとして現役で残存し続けたヒッピー文化の足跡は、事実上以下に述べる「ティモシー・リアリー博士の遺言」のみでした、

ティモシー・リアリー博士自身の説明
Turn on
"'Turn on' meant go within to activate your neural and genetic equipment. Become sensitive to the many and various levels of consciousness and the specific triggers that engage them. Drugs were one way to accomplish this end.
「Turn on」というスローガンで主張したいのは(「RAVEせよ(自分に嘘をついてでも盛り上げよ)」という話ではなく)「(自らを包囲する外界に対するさならるJust Fitな適応を意識して)自らの神経を研ぎ澄まし、生来の素質を磨け」という事である。あらゆる状況に自らを曝せ。そして自分の意識がどう動くか細部まで徹底して観察し抜け。何が自分をそうさせるのか掌握せよ。ドラッグの試用はその手段の一つに過ぎない。
「ドラッグの試用はその手段の一つに過ぎない」…実際、当人も後に「コンピューターによる自らの脳の再プログラミング」の方が有効という結論に至った訳だが「訓練手段」としてゲームを選択した場合「汚れた街やサイバースペース(cyber space)への没入(Jack In)」も「デスゲーム(Death Game)に巻き込まれる事」も「異世界に転生する事」も手段として完全に等価となるかが難しい。
Tune in
'Tune in' meant interact harmoniously with the world around you - externalize, materialize, express your new internal perspectives. Drop out suggested an elective, selective, graceful process of detachment from involuntary or unconscious commitments.
「Tune in」というスローガンで主張したいのは(「内面世界(Inner Space)の完成を目指せ」という話ではなく)「新たに掴んだ自らの内面性を表現(Expression)せよ」という事である。自己感情を外在化し、具体化し、それでもなお自らを包囲し拘束する現実と「調和」せよ。
「Tune in」は「Turn in」とほぼ同義。ここで興味深いのはどちらにも「警察に届ける(問題解決を公権力あるいは専門家に委ね、後はその指示に従順に従う事)」というニュアンスが存在するという点。そして直感的には「in」の対語は「out」となるが「Turn out」とは「自らを包囲し拘束する現実」を「全面否定して引っ繰り返す」あるいは「諦念を伴って全面受容する」事。「Tune out」とは「黙殺を決め込む」事。だがあえてティモシー・リアリー博士はこうした選択オプションを嫌い「自らを包囲し拘束する現実」を突き抜けた向こうに「外側(Outside)」は存在しない(あるいはどれだけ無謀な進撃を続けても「現実」はどこまでも付いてくる)とする。無論(自らも専門家の一人でありながら)「問題解決を公権力あるいは専門家に委ね、後はその指示に従順に従う」という選択オプションも許容しない。マルコムX流に言うなら「誰も人に自由、平等、正義を分け与える事は出来ない。それは自ら掴み取る形でしか得られないものなのだ(Nobody can give you freedom. Nobody can give you equality or justice or anything. If you're a man, you take it. )」、日本流に言うなら「誰にも人は救えない。それぞれが勝手に助かるだけだ」といった感じ?
Drop out
'Drop Out' meant self-reliance, a discovery of one's singularity, a commitment to mobility, choice, and change.
「Drop Out」というスローガンで主張したいのは「(本当の自分自身であり続けるために)現実社会から離脱せよ」という話ではなく「自立せよ」という事である。再発見された自らの個性に従った動性、選択、変化に専心せよ。
「Drop Out」は「Get off」とほぼ同義。ここで言いたいのはおそらく「解脱(Turn out)せよ」という事で、まさに「縁(自らを包囲し拘束する現実)からの解放」を主題とした原始仏教における「解脱」の原義がティモシー・リアリー博士のこの説明とぴったり重なる。ちなみに「Drop in」は「突然ぶらりと立ち寄る事」で、「オトラント城奇譚」作者として知られるホレス・ウォルポールが1754年に生み出した造語「セレンディピティ(serendipity、素敵な偶然に出会ったり、予想外のものを発見すること。また、何かを探しているときに、探しているものとは別の価値があるものを偶然見つけること)との関連が認められる。ちなみに「Get on」は「大き力に便乗する事(そしてそれによって成功を収める事)」。
総論
Unhappily my explanations of this sequence of personal development were often misinterpreted to mean 'Get stoned and abandon all constructive activity.'"
残念ながら、こうした私の自己発達に関する言及は「ドラッグでラリって建設的なすべての行動から遠ざかる」というように誤解されている。
これはこれで残るべくして残った至極の名言という感じ。「人機一体の時代」にも十分通用する心得だと思うので参考がてら再掲。
本当のパラダイムシフトは分布意味論的空間の発見がもたらした?
2022年におけるChatGPTの登場は、明らかにここまでに掲示した材料だけでは説明不可能なパラダイムシフトを含んでいます。そこで分布意味論の概念が登場してくる訳ですが、正直現時点においては「分布意味論(Distributional Semantics)っぽい」なる茫漠とした感触についてちゃんした形で定義を与える事が出来ません。しかも「これからの研究で何とかすべき」という話でもないのが頭の痛いところ…
人格心理学におけるビッグファイブ理論が立脚する語彙意味論(Lexical Semantics)あるいは語彙仮説(Lexical Hypothesis)においては「(環境適応の過程で)人間が言葉をつくり、言葉が人間をつくる」と考える。
ノーバート・ウィナー「サイバネティクス(Cybernetics,1948年)」1961年増補箇所は、個体身体内におけるホルモン連鎖や生物の群行動に見られるフェロモン連鎖に言葉の原型を見て取る。
ホルモン連鎖やフェロモン連鎖はしばしば同時期に発足したコンラート・ローレンツの動物行動学における「コクマルガラスの群が(一緒に逃げたり立ち向かったりする)共通敵を学習する過程」などと結びつけて考えられてきた(こうした群の後天的学習結果は「メンバーが一斉に全員入れ替わる事はない」準安定性によって維持される)。
人間の言葉は、こうした由来のまちまちなグループを束ねる形で成立するのですから、そもそも最初から数学でいう「(全体に適用可能なユークリッド尺度構成が不可能な)多様体(Manifold)構造」である事を宿命付けられているといって良いでしょう。
人工知能は当然、こうしたデータをそのままマルチモーダル(Multimodal)形式で学習する事も可能ですが、人間への応答で求められるのは概ね(言葉に基本的に言葉で答える様な)シングルモーダル(Singlemodal)形式の全射表現、ないしは(「怒ってる人」と指定されて「怒ってる人の絵」を返す様な)任意のシングルモーダル(Singlemodal)形式から任意のシングルモーダル(Singlemodal)形式への単射表現となります。
これは人間側の問題で、要するに人工知能は言葉による問い掛けに無前提で円形の図形を返す様な禅問答は求められないという事です。まぁ数式で表現した方が収まりが良い場合に数式で返したりはしますが。
特に自然言語処理(NLP)で重要なのは分布意味論(Distributional Semantics)と深層学習(Deep Learning)理論の関わり合いとなります。実際、word2vecの様なライブラリーは「犬」「小屋」「散歩」など共起性の高い言語グループに注目する事で大いなる成果を上げています。
分布意味論(Distributional Semantics)と深層学習(Deep Learning)の理論は、自然言語処理(NLP)において密接に関連しています。以下にその関係性を説明します。
分布意味論
分布意味論は、単語の意味がその使用される文脈によって定義されるという理論です。この理論に基づく手法は、単語の共起情報(どの単語がどの単語と一緒に使用されるか)を利用して、単語の意味をベクトル空間に表現します。代表的な手法には次のようなものがあります:
●共起行列:単語の共起情報を行列として表現し、各単語をベクトルとして扱います。
●Latent Semantic Analysis (LSA):共起行列に特異値分解(SVD)を適用して次元圧縮を行い、意味の潜在的な構造を明らかにします。
深層学習
深層学習は、多層のニューラルネットワークを用いてデータから特徴を自動的に学習する方法です。NLPにおいては、特に次のような技術が重要です:
●Word Embeddings(単語埋め込み):分布意味論のアイデアを発展させ、単語を高次元の連続ベクトルとして表現します。代表的な手法には、Word2Vec、GloVe、FastTextなどがあります。これらはニューラルネットワークを使用して単語の埋め込みを学習します。
●シーケンスモデル:RNN(リカレントニューラルネットワーク)、LSTM(長短期記憶ネットワーク)、GRU(ゲート付きリカレントユニット)などは、時間的な依存関係を持つデータ(例:文章)を処理するために使用されます。
●Transformerモデル:最近のNLPの多くの進展はTransformerモデル(例えば、BERT、GPT-3、T5など)によってもたらされました。これらのモデルは自己注意機構を使用して文脈を効果的に捉え、高精度な自然言語理解を実現します。
両者の関係
1. 分布意味論から深層学習へ:
分布意味論の基本的な考え方は、深層学習における単語埋め込みの理論的基盤となっています。単語の意味をベクトル空間に埋め込むというアイデアは、Word2Vecなどの手法に引き継がれました。
2. 深層学習の利点:
深層学習モデルは、分布意味論の手法と比べて、より複雑で高次元の文脈情報を捉えることができます。例えば、Transformerモデルは自己注意機構を用いて、文全体のコンテキストを考慮しながら各単語の意味を理解します。
3. 統合と応用:
現代のNLPシステムでは、分布意味論の概念と深層学習の技術が統合されて使用されています。これにより、単語レベルだけでなく、文や段落、さらには文書全体の意味を効果的にモデル化することが可能となりました。
このように、分布意味論の考え方は深層学習の進展と密接に関係しており、両者が相互に補完し合うことで、NLPの精度と性能が大きく向上しています。
これにさらに「ウィントゲンシュタインの言語ゲーム」概念が絡みます。実際、Transformer系LLMは(元来は写真における前景と背景の切り分けなどに使われてきた)自己注意機構アルゴリズムなどを駆使してそれに近い場合分けを実装する事で飛躍的に性能を伸ばす事に成功しています。
ルートヴィヒ・ウィトゲンシュタインの「言語ゲーム(language games)」の概念は、彼の後期哲学の中心的なテーマの一つです。この概念は、言語の使用が社会的な活動やコンテキストに深く結びついていることを示すために用いられます。
言語ゲームの概念
ウィトゲンシュタインの「言語ゲーム」は、以下のような考え方を含んでいます:
1. 言語の多様性:
言語は多様な形式と機能を持ちます。命令、質問、描写、報告、推測、感謝、挨拶など、さまざまな言語行為が存在します。これらの言語行為は、それぞれ異なる「ゲーム」として捉えられます。
2. 文脈の重要性:
言語の意味は、特定の文脈や状況に依存します。同じ言葉や文でも、使用される状況や目的が異なれば、意味も異なります。言語ゲームは、この文脈依存性を強調しています。
3. ルールと規則:
各言語ゲームには独自のルールがあります。例えば、チェスやサッカーのようなゲームにはそれぞれのルールがあるように、言語の使用にもその状況や目的に応じたルールが存在します。
4. 言語の機能性:
ウィトゲンシュタインは、言語を「道具箱」に例え、言語の各部分が異なる機能を持つと考えました。言語は単に物事を描写するだけでなく、行為を実行し、社会的な相互作用を形成します。
言語ゲームの例
ウィトゲンシュタインの「言語ゲーム」の概念を理解するために、いくつかの具体例を挙げます:
• 買い物ゲーム:
店で商品を買うときの会話ややり取り。ここでは、価格を尋ねる、支払う、商品を受け取るなどのルールや慣習が存在します。
• 教室のゲーム:
先生と生徒の間のやり取り。ここでは、質問をする、答えを求める、説明するなどの行為が含まれます。
• 医療のゲーム:
医者と患者の間の対話。診断、治療の説明、患者の状態の報告などが行われます。
哲学的意義
ウィトゲンシュタインの「言語ゲーム」理論は、言語の意味が固定的でなく、使用の仕方や文脈によって変わることを示しています。これは、言語の本質や意味についての伝統的な見方を覆すものであり、以下のような哲学的な意義があります:
1. 意味の使用理論:
言語の意味は、その使用方法によって定義されるという考え方。言語の使用が意味を形成するという視点です。
2. 反本質主義:
言語や概念の本質を探るよりも、それらの使用や実践を通じて理解しようとするアプローチです。
3. 実践としての言語:
• 言語は抽象的なものではなく、日常生活の実践や行動の中で具体化されるものであるという視点です。
結論
ウィトゲンシュタインの「言語ゲーム」は、言語の多様性と文脈依存性を強調し、言語の意味をその使用に基づいて理解するための重要な概念です。この理論は、言語哲学だけでなく、コミュニケーション、社会学、文化研究など多くの分野に影響を与えています。
全体像を俯瞰すると…
分布意味論、深層学習、言語ゲームは、それぞれ異なる角度から自然言語処理(NLP)や人工知能(AI)にアプローチしますが、相互に関連し、補完し合う関係にあります。以下にそれぞれの概念とその相互関係について説明します。
分布意味論
分布意味論(Distributional Semantics)は、単語の意味をそのコンテキスト(共起関係)から捉える理論です。具体的には、単語の意味は他の単語との共起パターンによって表現されると考えます。分布意味論に基づいた代表的なモデルには、以下のようなものがあります。
TF-IDF(Term Frequency-Inverse Document Frequency):単語の頻度を基に重要度を測る手法。
LSA(Latent Semantic Analysis):単語-文書行列に特異値分解(SVD)を適用して低次元の意味空間を構築する手法。
Word2Vec:単語をベクトル空間に埋め込むことで、意味的な類似度を捉えるモデル。
深層学習
深層学習(Deep Learning)は、多層のニューラルネットワークを用いて、データから特徴を自動的に学習する手法です。自然言語処理における深層学習の主な応用には、以下のようなものがあります。
埋め込みモデル(Embeddings):Word2Vec、GloVe、FastTextなど、単語をベクトルとして表現する手法。
リカレントニューラルネットワーク(RNN)や長短期記憶(LSTM):順序データ(テキストなど)を扱うためのモデル。
Transformerモデル:BERT、GPTなど、自然言語処理における最新のモデル。
言語ゲーム
言語ゲーム(Language Games)の概念は、ルートヴィヒ・ウィトゲンシュタイン(Ludwig Wittgenstein)が提唱したもので、言語の意味はその使用(ゲームのルール)に依存するという考え方です。言語ゲームは、特定の文脈やルールの中でどのように言語が機能するかを理解するための概念です。
分布意味論、深層学習、言語ゲームの関係
分布意味論と深層学習:
分布意味論のアイデアは、深層学習によって強化され、より洗練された方法で実現されています。例えば、Word2VecやBERTなどの深層学習モデルは、分布意味論に基づいて単語の埋め込みを学習しますが、ニューラルネットワークを用いることで、より高次元で複雑な意味関係を捉えることができます。
深層学習と言語ゲーム:
深層学習モデルは、言語ゲームの文脈を捉える能力を持っています。BERTやGPTのようなモデルは、大量のテキストデータから文脈情報を学習し、文脈に応じた意味の変化や使用方法を理解します。これにより、言語の使用に基づく意味を適切に捉えることができます。
言語ゲームの視点から見ると、深層学習モデルは、言語の使用ルールを学習し、それに基づいて適切な応答を生成することで、特定の「ゲーム」に参加していると考えることができます。
分布意味論と言語ゲーム:
分布意味論は、言語ゲームの一部を数学的・統計的にモデル化する手段として見ることができます。言語の使用に基づく意味の変化や文脈依存性を、共起関係や分布情報を通じて捉えることで、言語ゲームのルールを理解しようとする試みといえます。
まとめ
分布意味論、深層学習、言語ゲームは、自然言語の理解と処理において相互に関連し合う重要な概念です。分布意味論は、単語の意味を共起関係から捉える基本的な理論を提供し、深層学習はそれをニューラルネットワークによって強化し、複雑な文脈情報を扱えるようにします。言語ゲームの概念は、言語の意味が使用に依存することを強調し、深層学習モデルがどのように文脈に応じた言語理解を実現するかを理解するためのフレームワークを提供します。これらのアプローチは、相互に補完し合いながら、自然言語処理の精度と応用範囲を広げています。
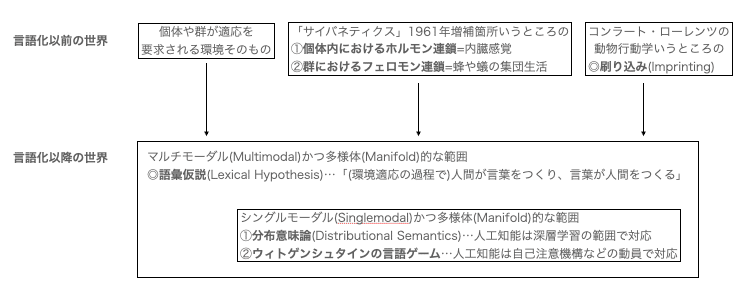
この表をまとめながら気付いた事。いわゆる「マウンティング行為」とは自明の場合として「語彙仮説のマルチモーダル表現」に他ならないという事。つまりこの領域はゼスチュアなどのノンバーバルコミュニケーションや服装による身分差表現などまで含んでいる。
しかしもちろん、株価動向一つとってもこうした全体像についての洞察はほとんど見る事がありません。
【速報】Microsoft決算
— 後藤達也 (@goto_finance) January 30, 2024
クラウド主導で収益増。発表直後は1%ほど株安になり、いまは1%高と、一進一退の状況です。AIとクラウドやOfficeとのシナジーへの期待は強く、株価は上昇基調が続いてきました。先日、時価総額がAppleを抜き、世界首位になったことでも話題になりました pic.twitter.com/b0e9UFwrbL
この振り幅。
$MSFT 🚩microsoft決算 (ガイダンスまだ)
— 米国株朝刊太郎🇺🇸VTuber/ブロガー (@beikabutaro) July 30, 2024
時間外▼6%中💥
✅株価1年で+26%
✅決算前PER36.6→ 25年6月:32.1
<ヘッドライン>
🔥クラウドが未達、Azureの成長が鈍化、ハイテク株の売りが急増(多額のAI投資回収に時間がかかる可能性💥)https://t.co/BXCDQhHMoy
<利益など>
⭕EPS… pic.twitter.com/lCqQiA5nni
Microsoft $MSFT が決算発表!
— ストロングマシン@米国株 (@strongmachine_p) July 30, 2024
クラウドサービスの売上ミス!!!
●売上高:$64.7B (予想:$63.8B)⭕️
●EPS:$2.95 (予想:$2.94)⭕️
●Azure売上:$2.85B(予想:2.86B)❌
テック銘柄の優等生は流石の決算で、個々のサービスの成長率も素晴らしく、本来なら評価されても全くおかしくない🤔… pic.twitter.com/PPCLetiMOU
23年1月〜NVDAを中心とするAI供給サイドの株価は急騰
— 株ナッツ (@kabunattu) July 25, 2024
生成AIを利用し収益が上がるAI利用サイドの株価はS&Pよりパフォーマンスが下
↓
AIによる恩恵が大したことないと判断されると
↓
🇺🇸大手ハイテクのAI設備投資が鈍化する
↓
生成AIバブル懸念にて損切りモードに入る
★これが半導体株を売る理由 pic.twitter.com/DtLihEgqSN
AIバブル崩壊相場だわ。
— 【トランプ♠️砲に気をつけろ‼️】 (@soseisandesu) July 30, 2024
データセンター売上鈍化しました。(T . T) pic.twitter.com/DVngYeWITE
🇺🇸を見ているとAIバブルが弾けそうなのですが、そうなると日経さんを牽引してきた半導体関連も軒並み打撃を受け、円高もあいまって、日本市場は今後どうなっていくのでしょうか…?
— いくら (@ikura03777) July 30, 2024
高配当ばりゅー? pic.twitter.com/l7A9iANJCC
世界で最も重要な株価がまた下がった。群衆がエヌビディアの上昇をパニックで買う時代は終わった。エヌビディアは、6月20日につけた史上最高値以来、時価総額が1兆ドル(155兆円)も減少。たった5週間でテスラの時価総額の1.5倍、バークシャー・ハサウェイと同じ価値を消した。AIバブルは弾けたのか? pic.twitter.com/CIPhWyZG3J
— 朝倉智也(Tomoya Asakura) (@tomoyaasakura) July 30, 2024
AMD 時間外 +5% 「半導体ショックを回避」ふぅ💦
— にこそく (@nicosokufx) July 30, 2024
エヌビディア -7%で終え🔥
マイクロソフトが引け後の決算で 時間外-7%の急落
エヌビディアや半導体株は、連れ安の急落
その後、AMDの決算を受けて
エヌビディアや半導体株は時間外プラテン!
最悪な状況を回避した pic.twitter.com/E9Yy987XGl
比較的落ち着いた意見
ここ2週間くらいNVIDIA含め市場が酷いことになってるなぁと思ってましたが、私が参考にしてるセカニチ(@sekanichi__ )さん「年初から見ると+122%だよ、売買代金ランキングはずっとトップだよ、慌てなくていい」と仰せです。これを信じて短期的な下落を無視してます!#セカニチ #株クラの輪を拡げよう pic.twitter.com/2jYv8snt6J
— こうへい|楽天社員 (@kohey_raku10) August 3, 2024
世間なるもの、一体どれほど危ないバランスで成立してるものやら…そんな感じで以下続報。