
【超丁寧に解説してみた】コンサル型のデータサイエンティストって何するの?

この記事は全文無料でお読みいただけます!
自己紹介
こんにちは!つかぽんたんです!
記事を読んでいただきありがとうございます!
駆け出しデータサイエンティストの私が普段どんな勉強してるかXで発信してるので、よかったらフォローしていって下さい!
誰がなんと言おうと仕事終わりに勉強してる人は偉いです pic.twitter.com/CgoO2UbtSF
— つかぽんたん (@tsukapontan_) November 11, 2024
この記事を書こうと思った理由
未経験から転職して約1年が経ちました。
定期的に振り返ることで自分のスキルの棚卸しをしようと思い執筆しています。
それに加え、データサイエンティストに興味あるけど、実際どんなことしてるかイメージ湧かないという方(自分も転職するまでそうでした)のために、データサイエンティストってどんな仕事をしているのか、今の自分の理解していることをこの機会に整理しつつ、データサイエンティストのリアルを知ってもらおう!という趣旨です。
なので前半はコンサル型のデータサイエンティストである自分がどんなふうに仕事をしてるか説明し、後半でKPT的に振り返っていこうと思います!
↓↓↓自分の成長をより知りたい方は転職して半年の時にも記事を書いたのでよかったら合わせてこちらもご覧ください!↓↓↓
想定読者
✅ データサイエンティストになってみたいけど、どんな感じか知りたい方
✅ データサイエンティストと一緒に働いてるけど、あまり知らない方
✅ 現在事業会社のデータサイエンティストだが、分析会社に興味がある方
この1年どんな仕事してきた?
データサイエンティストってまだまだマイナーな職種なんですよね。
よくデータサイエンティストってエンジニアでしょ?とか、機械学習でゴリゴリモデリングするんでしょって言われるんですけど、必ずしもそうとも限らないんです。
まずはデータサイエンティストのことを全然知らない方でもイメージできるように、できるだけ具体的にどんな仕事か説明していきます!
どんな会社で働いてるの?
自分は分析会社でコンサル型のデータサイエンティストとして働いています。
と言ってもピンとこない方もいると思うので、少し掘り下げて説明します。
まず、データサイエンティストという職種がある会社は大きく分けて以下の2つのタイプに分けられます。
クライアントから分析案件を受注して分析を行う分析会社
自社サービスで事業を行う事業会社
例えばコンサル会社なんかは1に、飲食、自動車業界などの会社は2に分類されるかと思います。
また、一言でデータサイエンティストと言ってもその職能と役割によってしばしば呼称が分かれます。
会社によって細かい呼称は異なりますが、どこの会社も概ね以下の図のように①エンジニア/ビジネス寄りか、②機械学習を使うか/使わないかの2軸で説明されることが多い気がします。

自分はこの図のデータコンサルにあたるかと思います。
特に事業の性質上、分析会社にはデータコンサルやデータアナリストのようなビジネス寄りの職種が、事業会社にはエンジニア寄りの職種が多い気がします。
ではここからは、この1年で自分が分析会社のデータコンサルとして具体的にどんな感じで仕事をしてきたか(書ける範囲で)振り返っていきます!
どんな人とどんな体制で仕事してるの?
自分は今の会社では3つくらいのプロジェクトを経験しましたが、チームの人数は多くて10人程度、少ないと2人の時もありました。
チームの人数が多いと目的・役割に応じてさらにプロジェクト内でさらにチームが分かれます。
自分が参画したプロジェクトでは以下のようにチームが分かれていました。
(チーム名、役職名、体制図はフェイク情報を混ぜたイメージです)
①人数多めのプロジェクト
施策チーム
戦略チーム
分析タスクに対して横割りな体制(詳しくは後述)。このプロジェクトでは自分は主に中流のタスクを担当していました。
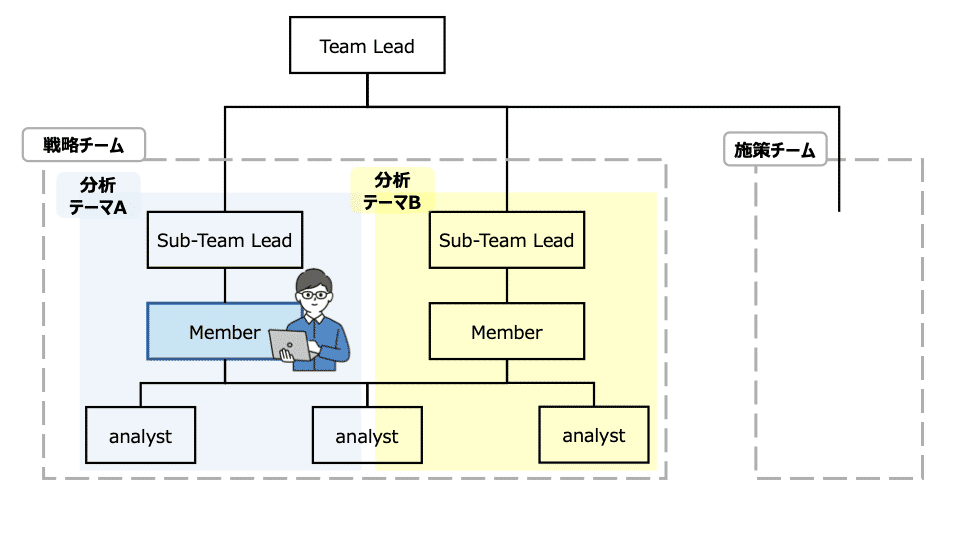
このチームの時は基本的にTL(Team Lead)かSTL(Sub Team Lead)がクライアント折衝を行なっており、自分はSTLの補佐的な役割で分析タスクに対応していました。
②人数少なめプロジェクト
新規ユーザ獲得担当
エンゲージメント向上担当
分析テーマに対して縦割りな体制(詳しくは後述)。基本的に一つの分析タスクを上流から下流まで1人で対応してた。

このチームの時は自分が対応した分析タスクについてはSTLの方にレビューいただきながら、クライアントMTGで自らクライアントに説明したりしてました。
具体的な業務内容は?
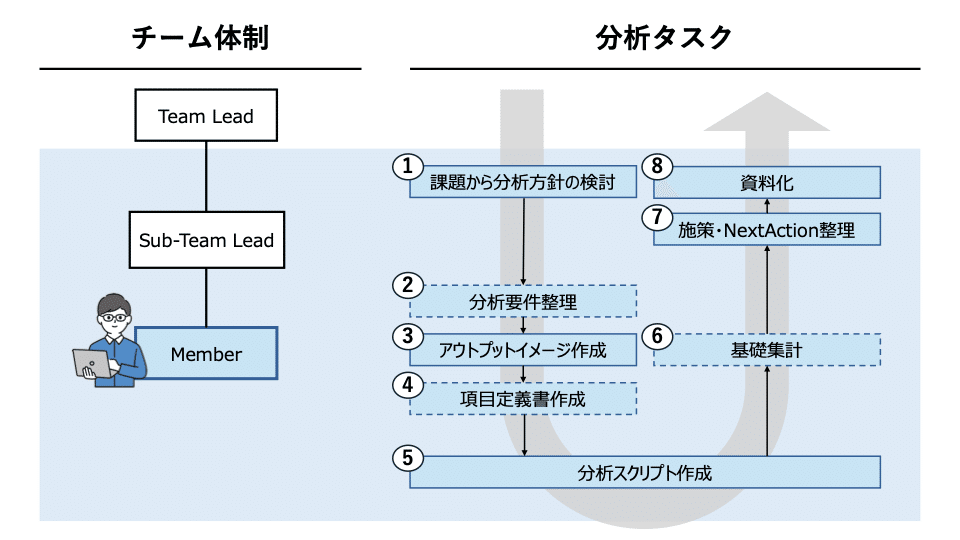
個人的に分析タスクは以下の8つの工程に細分化できると考えています。
課題から分析方針を検討する
分析要件を整理する
アウトプットイメージを作成する
アウトプットデータの項目定義書を作成する
スクリプト作成
アウトプットデータの基礎集計
示唆・NextActionの整理
資料化
それぞれどんなことをするのか簡単に説明すると以下のような感です。
課題から分析方針を検討する
以前の分析/施策結果などから見えてきた課題に対して、仮説をたてながら何を分析するか検討する。
分析要件を整理する
1ができたら、母集団、分析軸、指標は何になるかを具体的に整理する
アウトプットイメージを作成する
2の分析要件をもとに、表やグラフなどの形がどうなるかアウトプットイメージを作成する
アウトプットデータの項目定義書を作成する
2の分析要件を満たすデータを抽出してくるためのスクリプトの定義書を作成する。どのデータソースからどの項目を使って、縦持ちのデータにするのか横持ちのデータにするのか、PK(Primary Key)はどの項目にするのかとかを考える。
スクリプト作成
4の項目定義書をもとにデータ抽出スクリプトを作成する。うちの会社ではPysparkを使うプロジェクトが多い。
アウトプットデータの基礎集計
抽出したデータをエクセルのpivotなどで、3で作成したアウトプットイメージに合わせてデータを集計する
示唆・NextActionの整理
集計結果から示唆とその示唆に基づいたNextActionを整理する。
資料化
必要に応じてパワポ化する
人数が多いプロジェクトにいたときは、一つの分析タスクに対して、その工程ごとに対応する人が異なっていました。
特に自分は、中流部分の2,3,4,6を主に対応していました。
一つの分析タスクを複数人で対応する時は特に、2,3はTL/STLと、4はanalystと認識齟齬が出ないようにすることが重要です。ここでの検討が甘いと手戻りが発生する原因になるので結構神経を使います。
また、この時は戦略系のチームにいたので、主にサービスユーザの特徴を可視化したりサービス方針の意思決定の影響を効果検証したりする分析が多かったです。

一方人数が少ないプロジェクトでは上流工程から下流工程までを自分1人で対応することがしばしばありました。その時は認識合わせのコミュニケーションがない分、2,4,6あたりのタスクは省略することもありました。
この時のプロジェクトは施策系だったので、効率的に新規ユーザを獲得するためのロジックの検討やリストの作成を行っていました。
さて、ここまでつらつらと自分のやってきた仕事内容を自分の主観を交え説明をしましたが、ここからはさらに自分の主観全開で振り返っていきます。
前職とのギャップは?
プロジェクト単位の仕事
前職は法人営業だったのですが、法人営業であれば営業1課でも営業2課でもどこの部でもやることの大筋は変わりませんでした。担当のお客さんから来た依頼に対して提案したり、見積もり作ったり、契約書作ったり、納品調整したり。
一方データサイエンティストはプロジェクト単位で体制や業務内容が結構違います。前述した分析タスクの進め方などの基礎部分は共通しているものの、プロジェクトごとに必要なドメイン知識やチーム内のフォルダ構造、ナレッジの溜め方が結構違うので、チームを異動すると結構キャッチアップが大変です。最近はだんだん会社の根底にあるカルチャーというか、フィロソフィーみたいなものがわかってきたので、なんとなく慣れてきましたが特に最初の頃はこの辺が大変でした。
チームプレー
自分が法人営業の時は中小企業のお客さんを担当していたこともあり、基本的にはお客さんに対して1人で対応していました。
同じ課の人でも雑談や、事例共有、細かい業務の内容を教え合うことはあるものの、チームで動くことはほぼなかったです。
しかし、現在はめっちゃチームプレー。一つのタスクを分担して進めるとはどういうことか最初は全然イメージできていませんでした。
だんだん慣れてきてはいるものの、自分は元々大雑把な人間なので自分が思ってる倍くらいには丁寧に確認と認識合わせをしないと手戻り祭りになってしまいます。ここはまだまだ改善余地があるポイントですね。

定型作業の少なさ
前職の半分くらいは定型作業でした。ある程度契約プランと見積書/契約書の作成方法と決裁の取得方法、納品調整の方法を覚えてしまえば、ほぼパターン化された業務をこなす感じです。
しっかーし、データサイエンティストはほぼ定型作業はない!!!
そこにあるのは考え方の型であり、作業の型はありません!!!
それゆえ「仕事を覚える」という意味がまるっきり違うなって感じています。
前職では(やや極端な言い方ですが)作業方法を覚えれば一人前だったのに対し、データサイエンティストはSV(上司)のレビューがほとんど必要なく「考えられる」ことが一人前の基準です。
仕事きつい?楽しい?
両方ですね!!!!!!!!!!!!
とはいえ楽しい寄りです。せっせと作ったアウトプットイメージが全然SVと認識が合わず何回もレビューを受け修正が発生するときは、きっちーーーなあぁと感じる時もありますが、逆にレビューをするっとクリアして自力で分析タスクを回せている時や、自分の出した分析結果や示唆が施策に活かされたりすると結構嬉しくなりますね!
何ができるようになった?
さて、ここからがやっと本題(遅い)。
ここではデータサイエンティスト協会によるデータサイエンティストのスキルセットに則って今の自分のスキルをKPT的に棚卸しをしていきたいと思います。
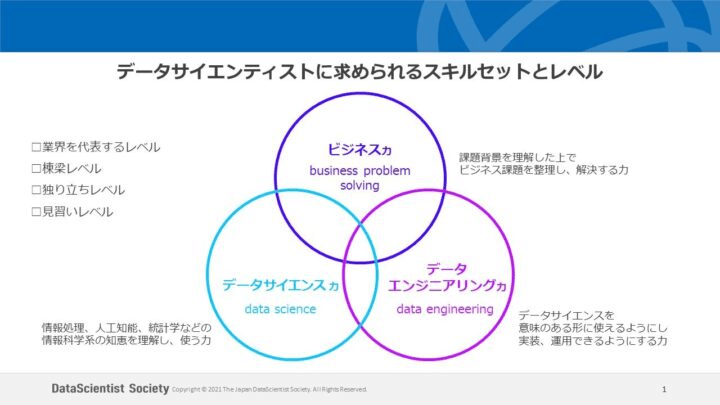
ビジネス力
文章の構造化が癖づいた
Slackなどのテキストでのコミュニケーションは構造化させないと気持ちわるく感じるようになりました。これはほんと成長かも。
この記事の構成からもこのスキルが付いてるのを感じてもらえたら嬉しいです。(半年前の記事↓を読んでいただければ成長してることが感じられるかと思います笑)
分析タスクの全体像が見えてきた
これもこの記事内で説明させていただいた通り、分析タスクをどう進めるか、どんなことをするのかの全体像が人に説明できるようになったのは成長だなあと感じます。
データサイエンス力
統計検定準1級合格
めっちゃ落ちまくりましたが、なんとか諦めず食らいついて合格を掴み取りました!統計学の知見がかなり広くなった実感があり、勉強頑張ってよかったなと思います。詳しくは↓の記事をご覧ください!
データエンジニア力
Pysparkは結構慣れてきた
チームメンバが自分とTLだけのプロジェクトの時にPysparkをずっと触っていたおかげで、ググらなくてもある程度書けるようになってきた。ただまだまだレビューしやすさや、再利用しやすさを考慮した「綺麗な」コードはまだ書けてないのでここは改善余地ありって感じです。
今の課題と今後の目標は?
ビジネス力
課題から分析方針を整理する力/示唆・NextActionを整理する力
分析タスクの上流工程ってやっぱり結構難しいんですよね。。。まだまだSVのレビューが多いなあと感じるのでSVの関与を減らして自力で分析タスクを回せるようになるのが今期の目標です
ドメイン知識
最近は上流工程を担当することが多く、データにあまり触れられていないので、積極的にデータのドメイン知識を付けていきたいです
データサイエンス力
Kagglerに俺はなる!!
統計検定準1級に受かった今、自分に足りないのは圧倒的に機械学習周りの知識。今期から力を入れてまずは銅メダル取れるように頑張ります!!!
データエンジニア力
Python書いてねえ!
今のプロジェクトではPysparkしか使わないので、もうPythonの記憶が無限の彼方にさあ行くぞ状態です。Kaggleを通してどんな会社に行っても戦力になれるようにPythonには触れ続けようと思います!!!
最後に
ここまでお読みいただきありがとうございました!
振り返ってみればこの1年で成長したポイントは多くあるなあというのが個人的な所感です。
何より、こんな記事を書けるくらいには仕事の全体像が見えてきてるのかなと思います。
とはいえまだまだ一人前のデータサイエンティストとは言えないので、これからも精進していきます!!!
ぜひスキを押していってくださいね!!!!!では!!!!!!
記事はここで終わりです。投げ銭として応援いただけると励みになります!!!!ぜひよろしくお願いします!
ここから先は
この記事が気に入ったらチップで応援してみませんか?