

2023年10月の記事一覧

シュッと LLM のおやじギャグ評価をしてみた
ちゃっす(/・ω・)/
特に深い意味はないのだけれど、なんとなく自分の主観的な好みで LLM モデルを評価できるといいなと思ったので、しょうもないおやじギャグリーダーボード的なものを作ってみた。
という話(/・ω・)/
とりあえず API でシュッと試したかったので ChatGPT と fireworks.ai で利用できるモデルを選択したぞ☆
まじめな評価をするつもりはないのでとりあえず

大規模言語モデルにおいて、「知識は全結合層に蓄積される」という仮説についての文献調査
はじめに大規模言語モデル(LLM)にファインチューニングで新たな知識を入れられないか、検討しています。
そろそろ論文を書くモードに入ってきたので、preprintなどを読みながら、周辺状況を整理中です。
本記事は、その一環の勉強メモです。
最近気になっているのは、「知識は全結合層に蓄積されている」という仮説です。この点について、調べていきます。
(参考)
今週、ファインチューニング関連でPFN




zephyr-7b-beta のデータセットの概要
「zephyr-7b-beta」のデータセット「UltraChat」と「UltraFeedback」の概要をまとめました。
1. zephyr-7b-beta「zephyr-7b-beta」は、「Mistral」をデータセット「UltraChat」と「UltraFeedback」でファインチューニングモデルです。複数のベンチマーク (ARC、HellaSwag、MMLU、TruthfulQA)


無償LLM 日本語能力ベンチマークまとめ(23/11/15)
日々新しいオープンソースのLLMまたはllama2のような無償使用可能なLLMが出てくるので定期的にベンチマークをとって性能評価をまとめておきます。新しい日本語対応LLMが出るたびに更新していきます。
23/11/15Japanese-MT-BenchRWKV-V5-World-1.5Bを追加。他の3Bモデルと遜色ない性能
RWKV-V5-World-v2-3Bを追加
23/11/9Japa

Google Colab で Youri-7B を試す
「Google Colab」で「Youri-7B」を試したので、まとめました。
1. Youri-7B「Youri-7B」は、「Rinna」が開発した「Llama 2」ベースの日本語LLMです。
2. Youri-7B のモデル「Youri-7B」は、現在6つのモデルが提供されています。
3. Colabでの実行Colabでの実行手順は、次のとおりです。
(1) Colabのノートブックを
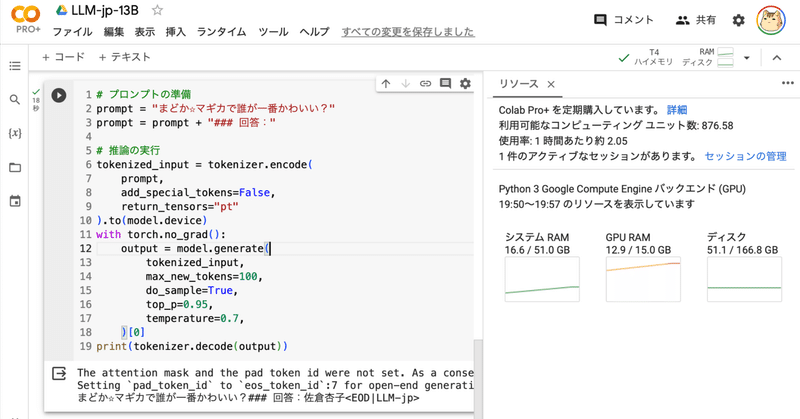
Google Colab で LLM-jp-13B を試す
「Google Colab」で「LLM-jp-13B」を試したので、まとめました。
1. LLM-jp-13B「LLM-jp-13B」は、「国立情報学研究所(NII)」が開発した130億パラメータの日本語LLMです。
2. LLM-jp-13Bのモデル「LLM-jp-13B」は、現在4つのモデルのみが提供されています。
3. Colabでの実行Colabでの実行手順は、次のとおりです。
(


初めての「LangChain」
はじめに LLM(Large Language Model)を効率的に使うには、「LangChain」なるものを使うといいらしい、、、とよく耳にするものの、LangChainってそもそも何なのか、LangChainを使うと何ができるのか、正直よくわかっていない。そこで、10月の3連休を利用して、素人ながら調べて、少し勉強してみることにした。
尚、本記述は私の数日の理解を元に記載したものであり、

AlpacaEval の概要
「AlpacaEval」の概要についてまとめました。
1. AlpacaEval「AlpacaEval」は、高速で安価で信頼性の高いLLM ベースの自動評価ベンチマークです。
2. 評価方法一般的なユーザーの指示に従うモデルの能力をテストする 「AlpacaFarm」の評価セットを使って評価対象のLLMの応答を生成し、「GPT-4」または「Claude」の自動アノテーターによって「davinc
ただ面白いから推しに関するディベートを fine-tuning した ChatGPT にシュッとやらせてみた
ちゃっす(/・ω・)/
ChatGPT 3.5 turbo モデルは fine-tuning ができるのである(/・ω・)/
さて fine-tuning とは?
というわけで今回の作戦はこうだ(〇-〇ヽ)
架空の物語を ChatGPT に創造させる
二人のキャラクターをつくる
それぞれのキャラクターを推す学習データをつくる
推しモデルをつくる
推しモデル同士でディベートさせる

OpenAI の WebUI で つくよみちゃんの会話テキストデータセット の ファインチューニングを試す
OpenAI の WebUI で「つくよみちゃんの会話テキストデータセット」のファインチューニングを試したので、まとめました。
1. つくよみちゃん会話AI育成計画(会話テキストデータセット配布)今回は、「つくよみちゃん」の「会話テキストデータセット」を使わせてもらいました。「話しかけ」と、つくよみちゃんらしい「お返事」のペアのデータが400個ほど含まれています。
以下のサイトで、利用規約を確

大規模モデルを単一GPUで効率的に学習する方法
以下の記事が面白かったので、かるくまとめました。
1. LLMを単一GPUで効率的に学習する方法大規模モデルの学習では、次の2つを考慮する必要があります。
「スループット」 (サンプル / 秒) を最大化すると、学習コストの削減につながります。これは通常、GPUメモリを限界まで利用することで実現されます。必要なバッチサイズがメモリオーバーする場合は、「Gradient Accumulation