
【ノウハウ】ChatGPTで長い文章を作成してみよう②-2 構成情報や設定、プロットを外部に記録する具体的な手順とケーススタディ

今回は、ChapGPTで長い文章を設定やプロットを、齟齬や冗長性を軽減しながら作り込んていく具体的な手順を、前回までに説明した、外部に情報を記録する手法を交えて説明していきます。
★記事の対象読者層などについて
※対象読者は、主に非エンジニア、初心者の人です。
※有料版のChatGPT Plus(ChatGPT4)を使っている人、使うことに関心がある人を対象にしています。
※記載内容は、Windows10PC、ブラウザがGoogle Chromeの環境で、作成、確認したものです。
※記載されている内容は投稿日(2023年9月下旬)時点の情報に基づいています。
※正直、無条件で多くの人には使って欲しくない手法(知識を持たない多くの人が無制限に使うと問題が起きる可能性があり、利用法についてある程度以上の知識とノウハウを持つ、限定された人数の人が、適切に利用して欲しい)なので、人数に制限を掛けるために、記事末尾のノウハウ部分は有料コンテンツにさせていただいています。
(記事単体:100円、マガジン購読:300円で、各記事はマガジン連載形式の1記事です)
この記事を掲載しているマガジンは
非エンジニア・初心者向けChatGPTノウハウまとめ 01
となります。
次記事公開まで無料
まだ、アクセス数が少ない事もあり、次の記事を公開するまでの間は、期間限定で無料、とさせていただきます。(次の記事を公開したらこの記事は有料マガジンに追加、単体100円になります)
今回の記事の準備
まず、この連載の初回記事 と 二回目の記事
で説明した手順で、今回の開始地点まで、作業を進めます。詳しい説明は、初回記事(ノウハウ部分は有料)を読んでください。
ここでは、外部のファイル(JSONファイル)に保存した情報を読み込んで作業を再開する基本的な手順を把握してください。
重要なポイント
この連載ではChapGPT4で、長い文章(小説)の設定、プロット、要約などを題材にして、ChapGPTの記憶量の制約(トークン制限)に起因する齟齬や不整合、冗長性を少なくする解説を行っています。
この問題は他の分野、例えばビジネス文書などでも起こりますが、同様の手法が適用できます。
作業を行っていくうちに、いろいろ問題が起きます。なので、この記事では、トラブルが発生した時に、トラブル内容を特定し、修正を行う(トラブルシューティング)方法をケーススタディとしてできるだけ詳しく記述しています。
カスタム指示(Custom Instruction)の設定を行います。この記事の初回記事で提示したサンプルのカスタム指示を設定した上で、作業を行っていますので、お使いの環境でカスタム指示を設定していない場合は実行結果が変わる可能性があります。
モードをChatGPT Plus(ChatGPT4)のAdvanced Data Analysisにします。
入力フォームに以下のプロンプトを入力します。(まだ送信ボタン(入力フォーム右側の紙飛行機ボタン)は押さない)
サンプル用のJSONファイルの内容(前回の記事で出力したJSONファイル)を、プロンプトの後に記載しますので、お手元のPCのテキストを編集可能なエディタで、jsonファイルを作成して、ChatGPT Plusを開いているブラウザのページにドラッグ&ドロップしてください。(あるいは入力フォーム左側の⊕ボタンを押して、アップロードするファイルとして作ったjsonファイルを選択してください)
入力フォームの送信ボタン(入力フォーム右側の紙飛行機ボタン)を押して実行してください。
↓↓↓↓プロンプトはここから↓↓↓↓
物語の構成案(プロット)を作成する方法論(以下のInstrunction)を用いて、プロット作成を行いたい。
1)まずは以下の、Instrunctionを確認し、方法論を把握して続きの作業を行えるように準備してください。
"""
Instruction for Crafting Engaging and Dramatic Story Plots Objective: To create a compelling and dramatic story plot that maximizes reader engagement and entertainment value.
Methodology:
1.Initial Brainstorming: Start by identifying the core elements of the story, such as the main characters, setting, and overarching themes.
2.Incorporate Storytelling Techniques:
Utilize various storytelling techniques like the Three-Act Structure, Hero's Journey, Focal Themes, Character Arcs, etc., to build a well-rounded narrative.
3.Introduce a Unique Element: Add a unique or mysterious element to the story that serves as a hook. This could be a technological concept, a moral dilemma, or an unexpected twist.
4.Character Development: Ensure that the main character(s) undergo growth and face setbacks. Use the Hero's Journey methodology to outline their path.
5.Technical Realism: If the story involves technical elements, make sure they are plausible or at least intriguing. Use the latest technological insights to add depth.
6.Conflict and Resolution: Introduce internal and external conflicts that the characters must overcome. Detail how these conflicts are resolved and what lessons are learned.
7.Review and Revise: Continuously review the plot for inconsistencies, gaps, or areas that could be improved. Make necessary revisions to enhance its dramatic and entertainment value.
8.User Feedback: If possible, gather feedback from the target audience or experts in the field to further refine the story.
9.Final Touch: Add finishing touches like foreshadowing, symbolism, and cliffhangers to keep the audience engaged till the end.
10.Epilogue: Consider adding an epilogue that ties up any loose ends and provides a satisfying conclusion to the character arcs and themes.
"""
2)その後、アップロードしたJSONファイル(novel_setting_and_plot.json)を読み込んで別の会話セッションで作った設定、プロットを記述したJSONファイルを読み込んでください。
読み込んだJSONファイルの内容は階層構造になっていますが、正規化、標準化がまだ不十分なのでキーを再帰的に取得して、含まれる情報がどのようなものか把握してください。必要があれば、JSONをテキストとして読み込み、あなたの大規模LLMとしての能力を使ってJSONの構造を把握してください。
JSONの構造を把握したら、各キーに対応する値を読み込み、読み込んだ設定を日本語で記述してください。読み込んだ設定は、要約したり割愛して情報を落とさないようにしてください。
2)の処理が終わったら、次の入力で、別の会話セッションで検討を行ったけれど、JSONファイルに記載されていない情報を入力しますので、「次の入力を待ってます」と表示してください。
↑↑↑↑プロンプトはここまで。↑↑↑↑
以下の内容を、テキストエディタに貼り付けて、ファイル名をnovel_setting_and_plot.json
として保存してください。保存したnovel_setting_and_plot.jsonをChatGPT Plusを開いているブラウザのページにドラッグ&ドロップしてください。
↓↓↓↓アップロードするjsonファイルの内容はここから↓↓↓↓
{
"設定": {
"時代・場所": "2030年代中盤、都市部を中心に展開",
"テクノロジー": {
"自動運転車": "一般化",
"再生可能エネルギー": "主流",
"AI": "専門職にも浸透"
},
"主人公": {
"名前": "Kaito",
"職業": "AI技術者",
"特性": "天才的な能力を持ちつつ、未熟。物語の初期でそのポテンシャルが暗示される。"
},
"サブキャラクター": {
"プロジェクトのメンバー": "メンバー内での軋轢やボジション争いが描かれる。",
"Kaitoの家族": "存在する",
"ライバル": "存在する",
"敵役": "存在する"
},
"プロジェクト": {
"名前": "EmoTechプロジェクト",
"目的": "人間の感情を読み取るAI技術を開発",
"手法": "生物学的マーカー(ホルモンレベル、心拍数)、脳波を分析",
"デバイス": "コンタクトレンズやスマートメガネで視野や瞳孔の状態を分析"
},
"社会的・倫理的要素": {
"デジタル格差": "AIデバイスを装着している'Enhanciles'と、装着していない'Naturals'",
"EmoTechの影響": "EmoTechがこの格差を拡大させる可能性"
}
},
"物語の構成(プロット)": {
"Act 1": {
"概要": "KaitoがEmoTechプロジェクトに参加。その天才的な能力がチラ見せされる。",
"初めてのトラブル": "一見、技術的な瑕疵に見える。"
},
"Act 2": {
"概要": "Kaitoとプロジェクトメンバーがトラブルの原因を探る。",
"内外の問題": "Kaitoは内部での軋轢と外部での期待に悩む。家族や友人との関係性も描かれる。",
"陰謀": "トラブルの背後には巨大な陰謀があることが明らかに。"
},
"Act 3": {
"概要": "Kaitoと仲間たちが陰謀を暴く。",
"最終決戦": "Kaitoは自らの成長と、陰謀の解決を果たす。"
},
"エピローグ": "Kaitoの未来と、EmoTechプロジェクトによって生じた社会的影響が描かれる。"
}
}
↑↑↑↑アップロードするjsonファイルの内容はここまで↑↑↑↑
(補足・注意点)
・拡張子が変わる(テキストファイルではなくなる)ので確認されますが、OKしてください。
・(読み込みエラーなどが起こったら面倒なので)保存時の文字コードはutf-8にしてください。
・テキストエディタにコピペしたら、改行、インデント(字下げ)整形がされていない(一行で記述される)と思いますが、インデント整形は人が見て分かりやすくするためのものなので、インデント整形されていなくても解釈してくれます。ただし、最初の{ から 最後の } まできちんとコピペしてください。
実行結果
プロンプトを入力した結果の例は以下のようになります。ChapGPTの回答はランダム性がありますので、同じになるとは限りませんが、今回はJSONファイルの内容を表示するだけ、かつ、情報量を落とさないように制約を掛けていますので概ね同じになると思います。
前半(JSONのキー情報を取得して階層構造を表示しています)

後半(前半で取得したキー情報を元に、JSONファイルに設定された内容を表示しています)

今回の作業
ここから、ChapGPTと対話しながら、設定やプロットの作り込みを行い、外部ファイルとして保存していく今回の作業を開始します。
この連載記事は、処理の自動化(一発出し)を目指すものではなく、
・ChapGPTとのやり取り(相互フィードバック)でクオリティを高めていく。
・文章が長くなり、情報量が増えてきた時に、ChapGPTの記憶量の制限(トークン制限)による不整合を軽減したり、セッションタイムアウト、エラーなどでの情報の喪失を減らす。
ことに焦点を当てていることに注意してください。

なので、トラブルが発生したらその状態と復旧方法をできるだけ詳しく記述してしていきます。
また、何度か言及しているように、ChapGPTは回答にランダム性がありますので、読者のみなさんがお手元の環境で実行しても、この記事で記載している実行例と同じになるとは限りません。ChapGPTの回答に応じたブラッシュアップの方法論を説明させていただいていますので、ご自身の環境、状況に応じてブラッシュアップを行ってください。
まず、以下の様にプロットの作り込みを開始します。
プロンプト例ここから
ではこれから作り込んでいくので、まずは、
"""
物語の構成(プロット)
Act 1
概要: KaitoがEmoTechプロジェクトに参加。その天才的な能力がチラ見せされる。 初めてのトラブル: 一見、技術的な瑕疵に見える。
Act 2
概要: Kaitoとプロジェクトメンバーがトラブルの原因を探る。
内外の問題: Kaitoは内部での軋轢と外部での期待に悩む。家族や友人との関係性も描かれる。
陰謀: トラブルの背後には巨大な陰謀があることが明らかに。
Act 3
概要: Kaitoと仲間たちが陰謀を暴く。
最終決戦: Kaitoは自らの成長と、陰謀の解決を果たす。
エピローグ: Kaitoの未来と、EmoTechプロジェクトによって生じた社会的影響が描かれる。
"""
を10章構成にして、章タイトルと、章の概要をできるだけ詳細に記載してください。
プロットに対する回答例が以下になります。

お世辞にも詳細とは言い難いですが、まず外部(JSON)ファイルに保存していく方法を説明するため、一旦このままで作業を続けます。
次のプロンプト例は以下になります。
作って貰った「10章構成に基づいた物語のプロット」を更に細分化してください。
各章10セクションに細分化して、各セクションのセクションタイトルとセクションの概要を記述してください。 10章の概要、つまり全体的なストーリーラインは壊さないように各セクションの構成を考え、また各セクションの記述内容が重複したり、話が飛んだりしないようにしてください。
プロンプトを入力すると以下のように3章までのセクションを作ってくれましたが、セクションの詳細さが足らないのでやり直してもらいます。

次のやり直し要求のプロンプトです。
やり直してください。各セクションの概要が短すぎるので、もっと長く詳細に記述してください。
作業指示(再掲)
作って貰った「10章構成に基づいた物語のプロット」を更に細分化してください。 各章10セクションに細分化して、各セクションのセクションタイトルとセクションの概要を記述してください。 10章の概要、つまり全体的なストーリーラインは壊さないように各セクションの構成を考え、また各セクションの記述内容が重複したり、話が飛んだりしないようにしてください。
(プロンプトに関する補足)「作業指示(再掲)」としています。少ない回数なら問題ないかもしれませんが、何回も繰り返し実行していると指示内容を忘れます。長くなりすぎると優先順位の問題で見落としたりするのでバランスは必要ですが、大事な指示は繰り返したほうが良いです。

各セクションの長さが多少は長くなったので、一旦これで進めます。
第二章を以下のように指示して記述してもらいます。

第三章も同様に指示して記述してもらいます。

途中ですが、ここで一旦、情報をファイルとして出力してもらいます。
「おまかせ」にすると、JSONファイルの構造が、項目ごとにばらついたりするので、先にある程度の構造を決めます。
以下がプロンプト例です。
途中ではあるけれど、これまで作った章、セクションの概要をJSONファイルとして出力し、必要に応じて読み込めるようにしたい。
「10章構成に基づいた物語のプロット」で記述した1~10章の章タイトル、概要と、1章~3章のセクションタイトル、セクション概要を記録するための、JSONファイルの構造を記述してください。JSON構造に問題がなければ、内容を記述してファイルとして出力してもらいます。
構造を考える注意点としては、この後、4章以降のセクションの構成や、キャラクターの設定や、世界観の設定、各セクションの本文などを追記、修正できるようにしてください。
上記プロンプトを入力した結果例が以下になります。

ある程度情報を網羅しているので、とりあえず、考えてもらった構造のJSONでファイルを出力してもらいます。
プロンプト例は以下になります。
考えてもらったJSONファイルの構造で、内容を記述してファイルとして出力してください。
内容を記述する際に、要約、割愛して情報を落とさないようにしてください。 出力用の一時ファイルを作って、そこに追記をしていくようにしてください。一度に長い文章を出力しようとするとエラーなどの問題が起きる可能性があるので、セクション単位などの細かい単位で追記し、なにか問題が発生しても、続きから作業をできるようにしてください。
try except構文を利用して、エラーや例外などの問題が発生してもそれを拾ってどこから作業を再開したら良いか判断できるようにして下さい。
一度に出力できない場合は、こちらから「続きを出力してください」と要求して続きを出力できるようにしてください。
実行結果
上記プロンプトを入力した結果が以下です。2回コードの実行中に問題、エラーが発生し、3回目にJSONファイルが出力されています。
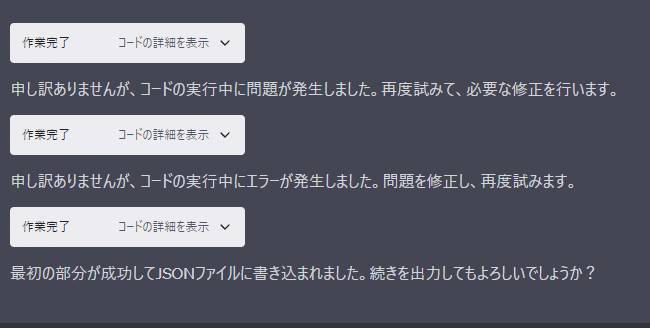
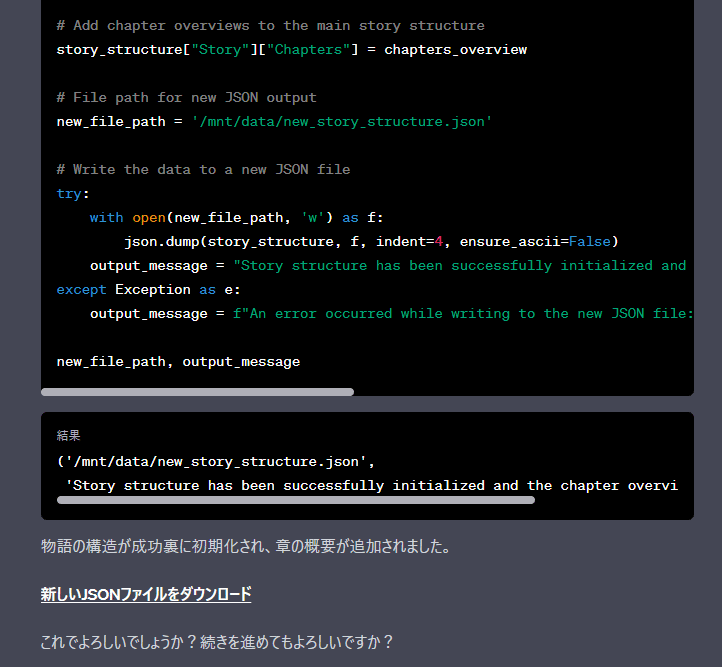
意図した通りにJSONファイルが書き込まれているかを確認するため、上記の段階でのファイルのダウンロードリンクを提供してもらいます。その上で続きを出力してもらいます。
プロンプト例
現時点でのファイルのダウンロードリンクを提供してください。その上で、続きの出力をお願いします。
実行結果


の部分をクリックし、出力したJSONファイルをダウンロードして内容を確認します。
スクショは見ずらいかもしれませんが、説明が英語になっています。また、第1章はセクション3まで記述したのに、セクション3が記述されていません。

{
"Story": {
"Title": "The Enigma of EmoTech",
"Overview": "The story revolves around Kaito, a young prodigy who joins the EmoTech Project. The narrative explores his journey from being a team member to uncovering a dark conspiracy.",
"Chapters": [
{
"ChapterTitle": "The New Horizon",
"ChapterOverview": "Kaito joins the EmoTech Project and gives a glimpse of his prodigious talents.",
"Sections": [
{
"SectionTitle": "The Invitation",
"SectionOverview": "Kaito receives an invitation from the EmoTech Project, recognizing his expertise and skills. Filled with excitement and anticipation, he considers the opportunity."
},
{
"SectionTitle": "The Arrival",
"SectionOverview": "Kaito arrives at the project’s headquarters. He is overwhelmed by the environment, brimming with cutting-edge technology."
}
]
}
],
"Characters": [],
"WorldBuilding": {
"Setting": "",
"Lore": ""
}
}
}
更に、コードブロック内での続きの出力の内容を確認すると、
・第2章のタイトル("ChapterTitle")や章の概要("ChapterOverview")がおかしくなっている。
・第2章のセクションはまだ出力依頼をしていない(第1章の残りのセクションを先に出力して欲しい)のに、第2章のセクション情報が出力されていて、なおかつ、そのセクション情報がおかしい(確認すると第3章のセクション情報を第2章のセクション情報として出力している)

要するにメチャクチャな情報出力になっています。
気づかず作業を続けると、後の手戻りが大変なことになるし、すべてのミス処理を拾って修正するのははどんどん難しくなっていきますので、作業手順を修正する必要があります。
メチャクチャな情報になった大きな理由は、3章までのセクション情報を作成してから、ファイルの出力を行ったため、ファイルの出力時点でChapGPTの記憶が混乱してしまったためです。
なので、対応の基本方針は、1章ごとにセクション情報の出力→ファイルの出力することにします。
★ChapGPTの記憶が曖昧にならないうちに関連処理を行う
修正作業のプロンプト例は以下になります。
前半
これまで利用してきた出力用のJSONファイルに修正作業が追記されたりしたらおかしなことになるので、一度削除してから改めて作り直して追記していくように指示を出します。たまたまうまくいくかもしれませんが、現状、ChatGPTはそこまで気配りが出来ません。
JSONファイルの構造は、会話セッションの履歴のコードブロックから探してコピペしたものです。改めてJSON構造を考えて貰うと細かい部分が変わります。新しいものに変えてもいいか、コピペして前のものと同じものを利用するかどうかは、ユーザー(つまり読者=あなた)の判断で行う方がいいでしょう。

後半
章タイトルと章の概要をまず出力します。
出力内容も、今回は同じものにするため、前回のものを会話履歴から探してコピペします。色々試して良いものを選びたいなど新しいものを作るのであれば再作業してください。ただし、出力した内容の選択(どれがいいか)は、あなたが行う必要があります。

実行結果
前半

前半の最後に
# Other chapters will be added later とコメントがあり、3章までの情報しかchapters_overviewにセットされていない事が分かります。
それとは別に章番号が情報として存在しておらず、管理上問題が出ると予想されるので修正しましょう。
後半(前半と同じコードブロックの続きです)
割愛しますが、ダウンロードしたjsonファイルを確認しても前半の解説で指摘した問題があることが確認できます。
それでは、問題の修正を試みましょう。プロンプト例は以下になります。

実行結果

最後に「章の番号が追加され、第4章から第10章までが含まれました。」と記述されていますが、これは嘘です。コードブロックの中を見ると、ChapterNo": 5, つまり第5章までしか記述されていません。
続きを記述して貰う必要があります、

次のプロンプト例は以下になります。

実行結果

10章までの章番号、章タイトル、章の概要を含んだJSONファイルが作成されました。ダウンロードしたJSONファイルは以下になります(右側及び下半分が割愛して見切れています。構造の確認用です)

章番号、章タイトル、章の概要を含んだJSONファイルが作成されたので、次は各章のセクション情報を追加で出力していきます。
プロンプト例は以下になります。
前半 JSON構造情報は前に利用したもののコピペです。ただし管理目的のための"SectionNo"を追記する指示を出します。

後半
第1章のセクションタイトルと概要は、同じものを利用するため、会話セッションの履歴からコピペしました。

実行結果
前半

後半

セクション1~10まで出力され、今回はうまく行った、と思いきや、前半部分の章の概要が第一章部分しか記述されていません。

修正を試みます。プロンプト例は以下になります。
(1/3)章情報は、出力して成功したJSONファイルの内容をコピペしています。

(2/3)

(3/3)

プロンプトの最後の部分で
追記が終わったらファイルに出力してください。 今回の作業は、'/mnt/data/story_structure_with_sections.json' を読み込んで始めていますが、出力するファイル名は後添字を追加してバージョンを変えてください。 ファイルの出力が終わったらダウンロードリンクを提供してください。
と記述し、作成開始状態とは別のファイルを作成して、追記部分のみが違う差分の更新ファイル(次のバージョンんのファイル)に出力するようにしています。
そうすることで、手戻りが発生した時に、どこからやり直すかをコントロールできるようになります。
実行結果
第二章のセクション情報が追記された新たなJSONファイルは作成されましたが、章の情報は第二章までしか追加されませんでした。おそらくプロンプトが長すぎたため、前半の章の概要追加の部分の解釈がうまく行かなったと思われます。
エラーが発生して、リトライを行ったので、最後の成功したコードブロックのみ以下に記載します。(右側は見切れています)
前半

後半

最初に書いたように、
章情報は以下のように2章の分しか処理されていません。

さらに章情報追記の修正を試みます。以下がプロンプト例になります。
前半

後半

実行結果(今回は章情報が追記されました)
前半
後半
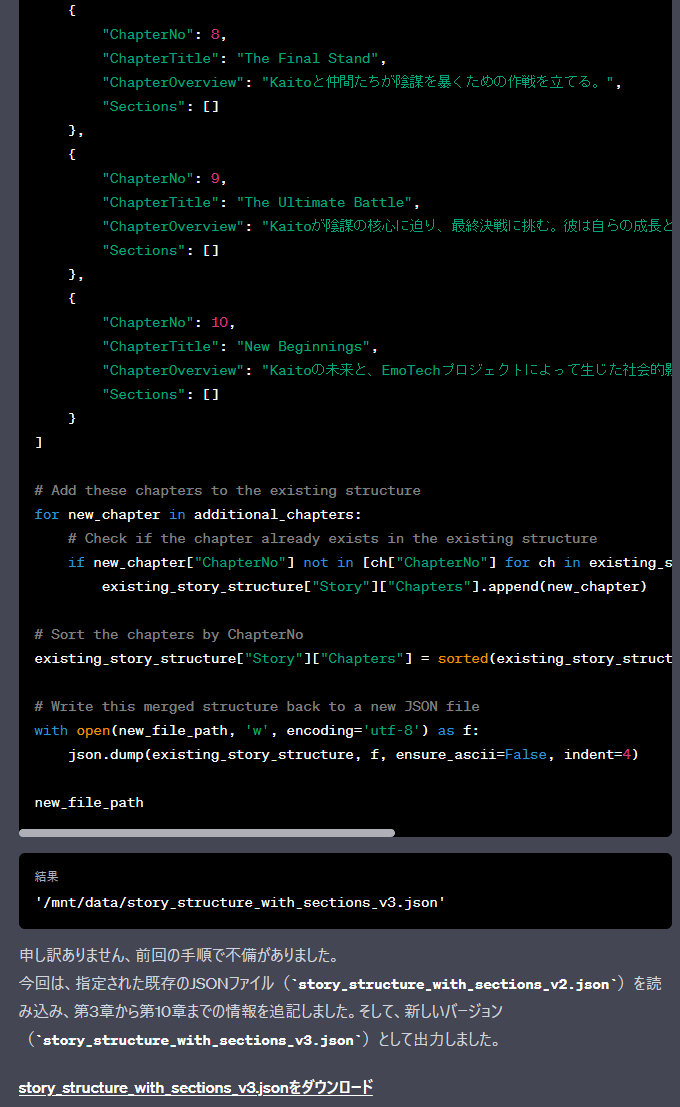
第3章のセクション情報を追記、出力します。セクション情報は、上で一度作成したものをコピペします。
加工元は、章情報の追記が終わった、
'/mnt/data/story_structure_with_sections_v3.json'
を利用するように指示します。
プロンプト例

実行結果(成功、第3章のセクション情報が追記されたファイルを出力)
前半

後半
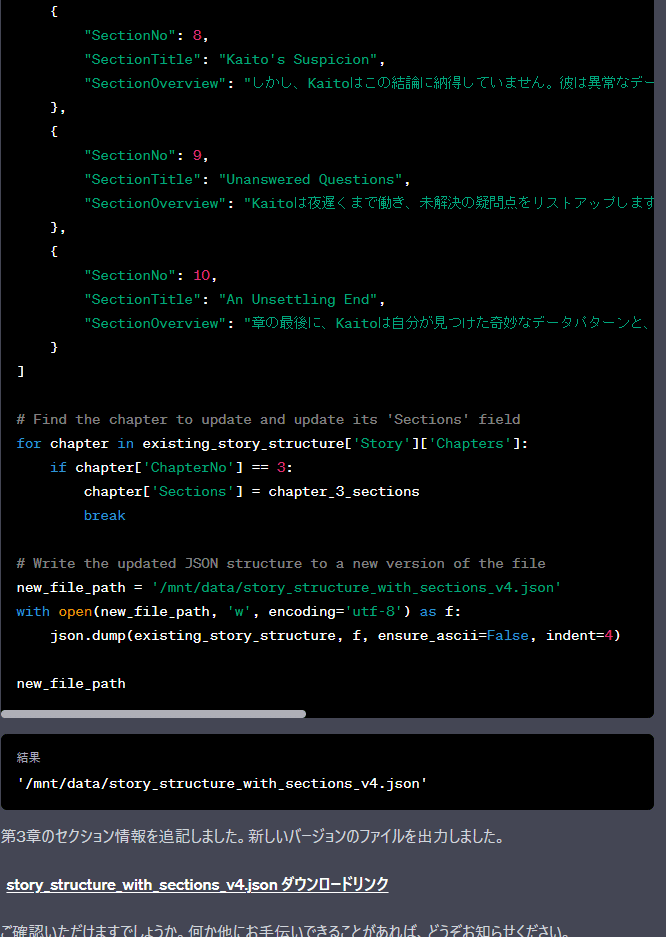
これで、1~10章の章情報と、第3章までのセクション情報が記載されたJSONファイルが作成されました。
セクション情報の作成は第3章までしか行っていなかったので、第4章以降のセクション情報の作成、ファイルへの出力を行います。
まずは、第4章のセクション情報の作成を行います。
プロンプト例

実行結果

作成した第4章のセクション情報を出力します。
プロンプト例

加工元のファイルは、第3章までのセクション情報が記載された
'/mnt/data/story_structure_with_sections_v4.json'
を指定してます。
実行結果 成功して第4章のセクション情報を記述したJSONファイルが出力されました
前半

後半

第5章も第4章と同様の手順で、セクション情報の作成、JSONファイルの出力が行われました。記載は割愛します。
第6章も同様の手順で実行を試みましたが、失敗しています。何が起こったのか確認してみましょう。注意点としては、第6章だから問題が発生したわけではない、ということです。ランダム性の問題で6章では発生せず、他の章で同じ問題が発生する可能性があります。
プロンプト例
まず、第4章、第5章と同様セクション情報を作成します。この部分は成功しています。

実行結果

次に、作った第6章のセクション情報の出力を試みます。
プロンプト例

第6章では問題が発生しましたが後の章でも同じプロンプトを使用して成功いますのでプロンプトに問題があるわけでは有りません。
実行結果(エラーが何度も発生してChapGPTがリトライを行っているので長いです)

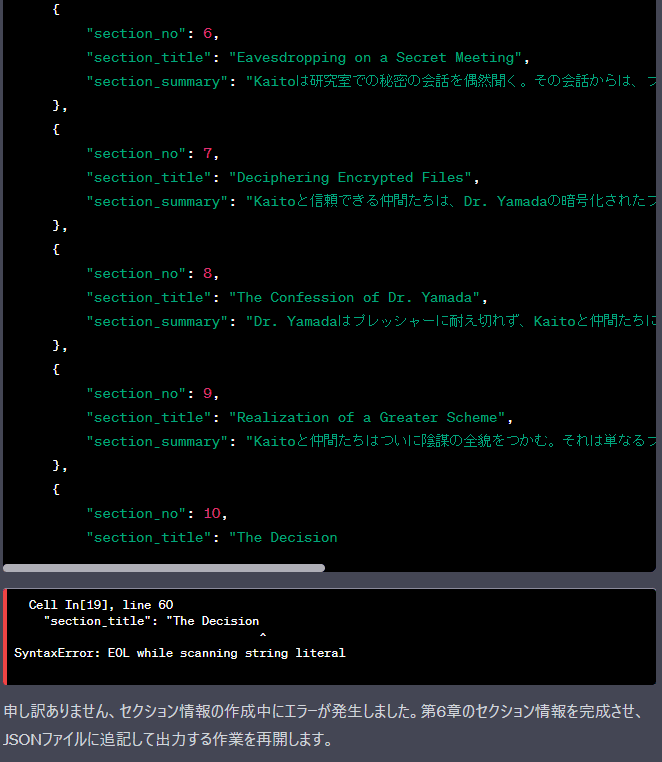
処理できる量を越えてセクション情報を記載しようとしたため、途中で止まってしまいエラーが発生しています。
実行結果続き(ChapGPTによるリトライ)

変数'chapter_6_sections'に10セクション目(つまり最後のセクション)のセクション情報を追加しようとしていますが、'chapter_6_sections'が定義されていない、とのエラーが出ました。
ちなみに、chapter_6_sections[-1] という記述法はpythonで配列の一番最後([-1]はマイナスを付けることで配列の後ろから1番目)という意味です。配列が何かご存知ない人は、そういう物だと受け止めてください。
何が起こったか、というと、最初のエラーでchapter_6_sectionsに10セクションの情報をセットするのが完了しなかったため、(配列)変数chapter_6_sectionsの定義が完了していないのに、配列の要素を追加しようとしたためエラーが発生しています。
実行結果続き(ChapGPTによるリトライ)
復旧しようとしていますが、エラーでセクション情報がセットされていないのにファイルを出力しようとしていますので、見当違いの方向に走っています。

上の段階で処理能力の限界が来て、回答は止まりました。
こちらからの指示で再試行を試みます。
第5章までの処理が終わった、
'/mnt/data/story_structure_with_sections_v7.json'
を加工元とするように指示します。
また、同じ問題が再発するのを避けるため「try exceptを利用してエラー例外が起こった場合に拾えるようにしてください。」との指示を追加します。
プロンプト例

実行結果(長いです。また今回の試行では成功はしません)

何かエラーが発生しています。原因は出力されていないので現時点では明瞭ではありません。
実行結果続き(ChapGPTによるリトライ)

JSONファイルが読み込めていない可能性があるとの判断を行っています。この後の実行結果は記載だけしますが、JSONファイルの構造に関して記憶が薄れて正しく解釈、読み込みやセットが行われていないのが大きな原因と推測されます。
実行結果続き(ChapGPTによるリトライ)

実行結果続き(ChapGPTによるリトライ)

実行結果続き(ChapGPTによるリトライ)

実行結果続き(ChapGPTによるリトライ)

実行結果続き(ChapGPTによるリトライ)

実行結果続き(ChapGPTによるリトライ)

実行結果続き(ChapGPTによるリトライ)

実行結果続き(ChapGPTによるリトライ)

処理能力の限界でここまでの試行が行われ、止まりました。
こちらからの指示で再試行を行います。
前回の最後は'chapter_6_sections'という変数が定義されていないためエラーが発生しました。という状態で終わっていますが、これまでの処理で一度定義はされている(そしてChapGPTがおそらく忘れた)ので、'chapter_6_sections'の定義情報を会話履歴からコピペして与えます。
プロンプト例
前半

プロンプト後半
前回の試行でエラーが多く、忘れている可能性があるので指示を改めて与えます。加工元のファイルも
'/mnt/data/story_structure_with_sections_v7.json'を改めて読みこんで利用するよう指示を与えます。

実行結果
全部を記載するのは割愛しますが、セクション情報が長すぎて、chapter_6_sectionsのセットが終了しないエラー3回繰り返されました。

次は、何が問題か聞いてみます。
敢えて聞いているのは、問題の原因をChapGPTが認識したら、以降の処理で同様の問題を回避出来る可能性があるためです(確実ではないですが可能性は上がります)

テキスト量が長すぎる問題に対する解決方法を答えさせたので、その方針で進めてもらうように指示します。
プロンプト例

実行結果 ようやく成功しました。
分割してセクション5までのセクション情報をまずセットしています。

次にセクション6~10のセクション情報をセットしています。
変数は前半と変えています。chapter_6_sections_second_half

以下、エラーが発生してChapGPTが何度か再試行を試みています。






以上で第6章のセクション情報が追記されたJSONファイルの出力に成功しました。
この試行(リトライ)の繰り返しから、ChapGPTには自己解決能力があることを再確認できます。
ただ、解決のための手がかりをChapGPTが見つけられないこともあり、その場合は人間のサポートが必要ということも同時に分かります。
第7章~第9章までの作業は、表面上失敗せず実行できたので割愛します。
最後の第10章の作業でまた別の問題が発生したのでケーススタディとして解説していきます。
プロンプト例
これまでの章と基本的に同じです。

実行結果
長いので複数に分割しますが、最終的にJSONファイルを出力するのに一見成功したように見えるものの、出力したJSONファイルを確認すると問題が発生していました。

chapter_10_sections に1~10までのセクション情報をセットする部分と、加工元のJSONファイル
'/mnt/data/story_structure_with_sections_v12.json'
の読み込みは行えていますが、セクション情報を、キー'chapters'の要素として追加するのに失敗しています。(長すぎて一回の応答では処理しきれなかった)
実行結果続き(ChapGPTによるリトライ)

前回長すぎてコードが途中で途切れてしまった部分から処理を行おうとしていますが、今度は、以前にもあったように、KeyError: 'chapters' と'chapters'というキーが無いというエラーになりました。
おそらく処理を続けていて、ChapGPTがJSONの構造を再度忘れてしまった可能性が高いです。
実行結果続き(ChapGPTによるリトライ)
以下の部分は、ChapGPTがJSONの構造を確認して、対応しようとしています。
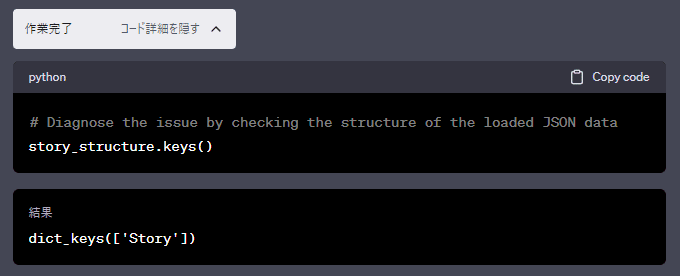



次のセクションで表面的には出力が成功したように見えますが、実はここで
NameError: name 'chapter_10_sections' is not defined
とのエラーが発生しています。
最初に、10章のセクション情報を、chapter_10_sections にセットしましたが、試行錯誤を繰り返しているうちにセットした情報を失ってしまったようです。
以下の最後の試行で、chapter_10_sectionsを改めてセットしていますが、
# ... (The rest of the sections are the same as defined earlier)
とコメントしているだけで、セクション1の情報しかセットされていません。

JSONファイルをダウンロードして確認すると、Chapter10の部分は以下のようになっていました。

今回の処理で追加したChapter10のセクション情報は一番下で、先程確認したようにセクション1の情報しか含まれていません。
ただそれ以外にも問題があって、セクション情報が含まれていない9章と10章のブロックが2つ残っています。スクショの範囲外も確認しましたが、Chapter9でセクション情報が追記されたブロックは有りませんでした。
9章の処理を行って出力したJSONファイルを確認すると、9章までのセクション情報が記載されたJSONファイルが出力されていたことが分かりました。
ただし、9章のセクション情報が追加されていない、章情報のみのブロックも残っていることが分かりました。

上のスクショで、"ChapterNo": 9 を含むブロックが2つ出来ている事が分かります。この重複のために、10章の処理を行う際に後のブロックが抜け落ちて、最初のセクション情報を含まないブロックのみ利用された可能性が高いと思われます。
10章の作業に使う加工元のJSONファイルを手作業で修正して作成する
ここでは、9章の作業後、おかしくなってしまったJSONファイルを手作業で修正して対応することにしましょう。
こういう単純なルールに基づいた処理は、ChapGPTのような確率に基づいた処理を行うロジックより、ルールベースでの処理を行うプログラミングで処理したほうが良いです。
ただ、プログラミングではなく、今回はテキストエディタでJSONを手作業で修正することにします。
2つ出来てしまった"ChapterNo": 9,を含むブロックのうち、上のブロックを削除して、下のブロックを削除したブロックの部分に持ってきます。
修正前の状態が以下です。

修正後は以下です。
セクション情報が記述された、ChapterNo": 9 を含むブロックの後に、

途中割愛
以下のように、セクション情報を含んだ9章のブロックの後に、章情報しか含んでいない10章のブロックが並ぶようにして保存し、これを次の再試行で加工元ファイルとします。

次のプロンプト例
上で修正したJSONファイル(story_structure_with_sections_v12_user_revised.json)をアップロードしてそれを加工元にするよう指示を微調整しています。
(1/3)

(2/3)

(3/3)

実行結果
前半(chapter_10_sectionsのセット失敗)

後半
今回はChatGPTランダム性が原因と思われる動作で、セクションの情報を高度ブロックではなく通常の応答として記述し始めました。



次のプロンプト例(10章最終)

実行結果
chapter_10_sectionsのセットを行おうとしてますが、セクション1とセクション2のみで、残りのセクションは勝手に割愛しています。
後、セクション情報は前回の実行結果で作った長いセクション情報ではなく、その前の、コードとしてこちらから提供した情報が使われています。
キー情報が見つからないという別の問題でエラーが発生しました。(結果的にはこのエラーが幸いして軌道修正が出来た可能性が高いです)

実行結果続き(ChapGPTによるリトライ)
前にもあったように、JSONの構造を確認しています。

次は、セクション3から続きのセクション情報をセットし始めました。
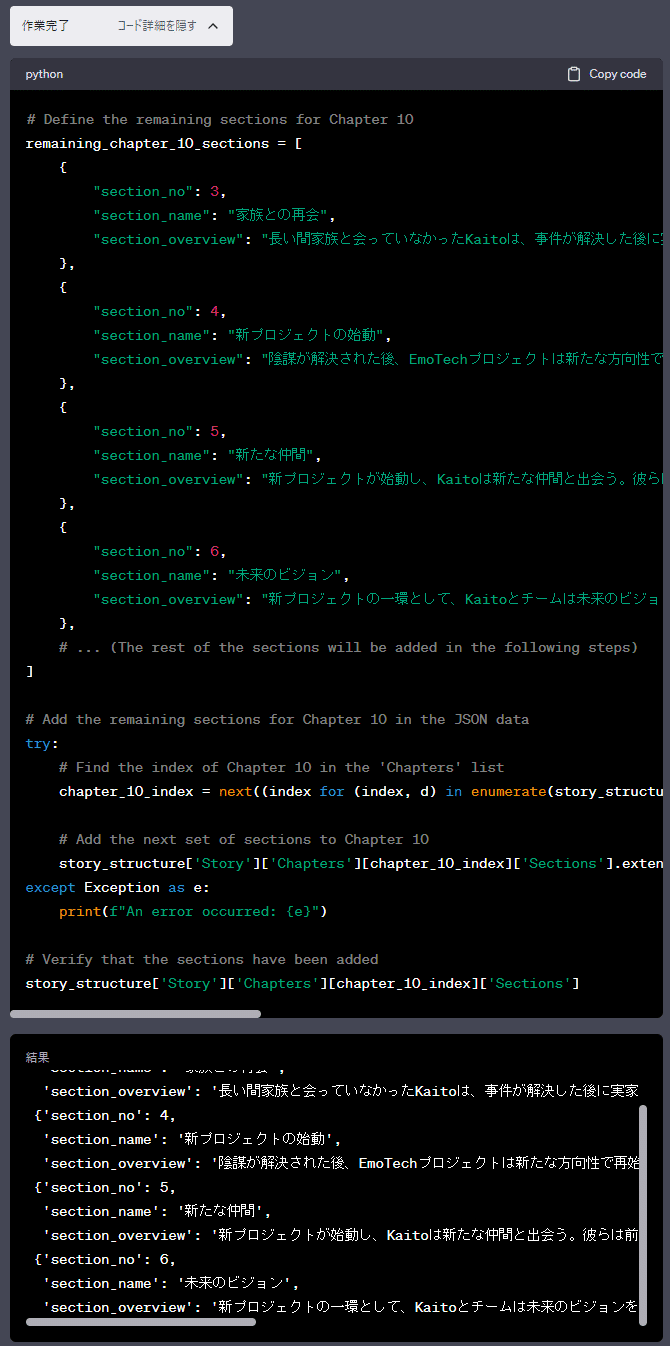
引き続き、セクション7からの情報をセットしています。

最後に、セットされた情報をJSONファイルとして出力しました。
ダウンロードリンクの提供がされていなかったので指示を出し、ダウンロードして10章分のセクション情報を外部ファイルとして書き出すことが出来ました。

まとめ
今回は、設定の作り込み品質アップは優先順位を下げて、細分化した構成情報(10章の章情報と、各章10セクション)をJSONファイルとして書き出す作業を再現しました。
不十分ですが、ChatGPTのランダム性などによる問題やエラー対応に関してのケーススタディとなったかと思います。
本格的に構成を作り込むのであれば、JSONファイルとして書き出す前にもっと試行回数を増やしたりして、セクション情報の作り込み、冗長性や情報の欠落、矛盾などを洗い出すことになります。
また、一度JSONファイルとして書き出した後、改めて読み込んで別の設定情報を追加したり、本文の作り込みを行っていく作業を行うことになります。
更に言うと、今回は(トラブルシューティングのケーススタディのため、あえて)行き当たりばったりの部分もありましたが、作業の方法論を標準化してスムーズに作業を行えるようにする必要もあります。