
【読書メモ】A/Bテスト実践ガイド 真のデータドリブンへ至る信頼できる実験とは

通称カバ本と呼ばれているこの本。
A/Bテストについての理解を深めるために必要なことだけでなく、A/Bテストを実際に正しく行うために必要な技術的な知識を平易な言葉で説明してくれています。
著者のRon Kohavi (ロン・コハヴィ)はAirbnb、Microsoftの元技術フェロー。彼の論文は40,000件以上引用され、そのうち3つはコンピューターサイエンスで最も引用された論文のトップ1,000に入っている。
共著者のDiane Tang(Google エンジニア)とYa Xu(Linkedin VP of Engineering)もGoogle、LinkedInで数多くのA/Bテストを行ってきた実績を持つ方。
実験計画に関するトピックスだけでなく、実験時に用いる指標や組織文化に関しても学びが多く内容でした。
改めて興味深かったポイントをまとめてみようと思います。
1.アイデアの価値を見積もることの難しさ
Microsoftの検索エンジンBingでは年間 1万件以上(※)の実験を実施しているが、巨大な改善をもたらすことは数年に1度くらいしか起こらない。
しかし、2012年に実施した広告見出しの表示改善は年間1億ドルの投資対効果を生み出しており、1人のエンジニアの数日の仕事が大きなリターンを生んでいた。
数百以上あった提案のうちの 1つであるこのシンプルな変更が、Bing史上最高収益を生み出すアイデアになるとは誰も思っていなかった。
(このアイデアは半年以上も社内で放置されていた)
※ちなみにGoogle、LinkedInも年間1万件以上のコントロール実験を行っている。
2.仮説検定の考え方
本書ではA/Bテストの方法論として仮説検定が登場します。このパートで基礎的な考え方を紹介します。
仮説検定のポイントは「反論を作って潰す」
仮説検定はある事象について統計的に違いがあるか否かを判断するアプローチです。
母集団から抽出した標本(※1)をもとに、母集団に関する帰無仮説(※2)を棄却できるか判定します。この帰無仮説が「わざと反論させる」部分にあたります。
具体例をもとに考えてみましょう。
※1.標本
「母集団」と呼ばれる全体から抽出された一部分。例えば完全失業率は、日本国民全体(母集団)の中からランダムに抽出された10万人(標本)に基づいて算出される。 A/B テストで得られたAとBのそれぞれのコンバージョン数などのデータもまた標本でしかない。
※2.帰無仮説
ある仮説が正しいのか検証したいときに立てられる仮説。主に否定したい仮説。帰無とは差が無い。関係が無いなどを意味する。反対の意味で対立仮説というものがあり「有意差がある」という仮説のこと。
具体例:広告ランディングページのA/Bテスト
新しい広告ランディングページ(以下 LPと記載)を作ったので、これからA/Bテストを行います。
この時、帰無仮説を「A/Bテストをしても、新LPと旧LPにCVR差が無い」とします。
実際にA/Bテストを行い、100回中95回CVRに差があった場合、「A/Bテストをしても、新LPと旧LPにCVR差が無い」確率は5%以下です(5/100=0.05)。
上記は「有意確率:p値(Probability)※3」という指標で、p値5%以下は統計学的に重要な意味を持ちます。
具体的には下記のように考えることが可能になります。
「A/Bテストをしても、新LPと旧LPにCVR差が無い」確率は5%以下。起こる確率は超レア。
↓
つまり、2つのLP間でCVR差が生まれるのは偶然ではなさそう。
↓
つまり、A/Bテスト結果で得られたCVR差は偶然ではなく必然。統計的に有意差を持っていると判断できる。
以上が仮説検定の大枠の考え方となります。統計学的視点に立つ場合、より厳密・詳細な説明が必要になりそうですが、私が専門家ではないため本記事では要点説明のみとさせて頂きます。
※3.有意確率とは
簡単にいえば、有意確率とは「一部のデータで計算した二変数の関係性が、どれくらい"たまたま"起こりうるのか」を確率として表現した値です。確率なので、0から1の間の値をとります。
有意確率の値が大きれば、「このデータをもとにすると、関係性がある(差がある)のは"たまたま"の可能性が高いので、関係性があるとはいいきれない(考えない)」と判断します。
なお、有意確率の値が有意水準を超えたとしても、「関係性がない」とは判断せず、「有意確率が大きい=偶然の可能性がある=関係性があるとはいいきれない」という判断をします。「関係性があるとはいいきれない≠関係性がない」という点に注意する必要があります。
一方、有意確率の値が小さければ、「このデータをもとにすると、関係性がある(差がある)のは、"たまたま"の可能性が低いので、関係性があるといえる(考える)」と判断します。
有意確率は、「関係性があると判断したときの誤判断リスク」ともいえます。有意差が大きければ、誤判断リスクも大きいために「関係性がある」とは結論付けません。
Ron Kohavi (ロン・コハヴィ)が考える仮説検定
『A/Bテスト実践ガイド 真のデータドリブンへ至る信頼できる実験とは』で著者Ron Kohavi は仮説検定に関して下記のように述べています。
コントロール実験では、コントロールに1つサンプルを、介入群に1つサンプルを用意することになる 。
私たちは、平均が同じであるという帰無仮説を与え、コントロール群のサンプルと介入群のサンプルのペアの間に差がありそうにないかどうかを検定によって定量的に見る。もし差がありそうにないといえそうもない場合、私たちは帰無仮説を棄却し、その差が統計的に有意であると主張する。
~中略~
p値が十分に小さければ、私たちは帰無仮説を棄却し、私たちの実験は効果がある(または結果が統計的に有意である)と結論付ける。
~中略~
科学の世界では基準に0. 05未満のp値を使用している。つまり、本当に効果がない場合に、100回中95回は効果があるとは言えないと正しく推論できるということである。
3.総合評価基準(Overall Evaluation Criterion)について
サービス運営者はA/Bテストによって、収益だけが改善すれば良いわけではない。
なぜなら収益だけを基準にすると、ユーザー体験を損なうことが知られている広告を Webサイトに貼り付けることになりかねない。
前述のBingでは、ユーザーごとのセッション単位でのユーザー体験のメトリクス(ユーザーの離脱や、エンゲージメントの増加)に対して、収益を重み付けしたOECを使用していた。
良いOECがなければ資源を無駄にする
可能性があることを肝に銘じる。
4.相関関係は因果関係を示唆するものではない
こちらはMicrosoft Office 365(サブスクリプションビジネス)の実例を踏まえた話。
エラーメッセージを見てクラッシュを経験したOffice 365ユーザーの方が解約率は低いが、だからといってOffice 365により多くのエラーメッセージを表示すべきだとか、Microsoftがコードの品質を下げてより多くのクラッシュを発生させるべきだということにはならない。
クラッシュ、エラーメッセージ、解約率の3つの事象はすべて、使用状況という1つの要因によって引き起こされる。つまり、製品のヘビーユーザーほど、より多くのエラーメッセージが表示され、より多くのクラッシュが発生し、解約率が低くなっていた。
相関関係は因果関係を示唆するものではなく、このような観察結果に過度に依存することは、誤った判断を招くことになる。
5.オンラインでのコントロール実験を行う組織に必要な3つの原則
①データに基づいた意思決定を行う為にOECを公式化する
データ駆動型の組織であるためには、組織は比較的短い期間(例えば1~2週間)で容易に測定できるOECを定義すべき。
(Goal metrics・Guardrail metrics・Debugging metricsの設定を行う)
困難なのは、「短期間で測定可能」かつ、「違いを検出するのに十分敏感」かつ「長期的な目標を予測できる」メトリクスを見つけること。
例えば、利益は良いOECではない。短期的な手段(例えば、価格を上げる)は短期的な利益を増加させることができるが、長期的には利益を損なう可能性があるから。顧客の生涯価値は戦略的に強力なOEC。
②インフラストラクチャとテストに投資する意思がある
コントロール実験を実行し、その結果が信用できるものであることを保証するために、上記が大切になる。
オンラインソフトウェアの領域(Webサイト、モバイル、デスクトップアプリケーション、およびサービス)では、ソフトウェアエンジニアリングによって、コントロール実験に必要な条件を満たすことができる。
コントロール実験は、Eric Riesがリーンスタートアップで普及させたような、アジャイルソフトウェア開発、顧客開発プロセス、MVP(Minimum Viable Products)と組み合わせることが特に有用。
③組織は、アイデアの価値を評価するのが苦手であることを認識している
Microsoftでテストされたアイデアのうち、改善を示すメトリクスを実際に改善できたのは3分の1にすぎない。
BingやGoogleのような数多くの実験により最適化された領域では、成功を見つけるのはさらに難しく、アイデアの成功率は約10~20%程度。
Slackのプロダクト&ライフサイクル担当ディレクターであるFareed Mosavatは、Slackでの経験から、マネタイズのための実験のうち、 30%程度しかポジティブな結果を示さないとツイートしていた。
もしあなたが実験主導のチームにいるなら、 70%の仕事が捨てられることに慣れてください。それに応じてプロセスを構築しましょう
他にも過去の失敗に関する担当ディレクターのコメントが出ており興味深いです。
Netflixでは、彼らがしようとしていることの 90%は悪い方向への挑戦でした
私は 5年間実験を実施してきたが、正しく結果を推測できた確率はメジャーリーグの野球選手がヒットを出す確率と同じくらいでした。つまり、私は実験を 5年間続けてきましたが、私がテストの結果を『推測』することができるのは、 33%くらいでした!
いくら自明だと思っていても、どれだけ研究をしていても、どれだけ多くの競合他社がやっていても、時には、あなたが思っている以上に、実験のアイデアは単純に失敗することが多いのです
過去のディレクターや開発者の事例を踏まえ、社内全員がアイデアの価値の評価が苦手である点を認識しA/Bテストに取り組みたい。
6.小さな改善の積み重ねが重要
主要なメトリクスの改善は、多くの小さな変更(0.1%から25%くらい)によって達成されている。
多くの実験では、ユーザーの一部にしか影響を与えないため、ユーザーの 10%に対して 5%の改善を行った場合、改善の影響は希釈され、はるかに小さな影響(例えば、母集団が実験対象群のユーザーとよく似ている場合は0. 5%)になる。
Al Pacinoが映画「 Any Given Sunday」の中で言っているように、「勝利は 1インチずつ」なのである。
7.スピード改善による効果
2012年、 MicrosoftのBingのエンジニアが JavaScriptの生成方法を変更し、クライアントに送信される HTMLを大幅に短縮してパフォーマンスを向上させた。コントロール実験では、驚くほど多くの改善されたメトリクスが示された。
10ミリ秒のパフォーマンス改善(※)ごとに、エンジニア 1人分の年間コストを全額負担できるほどの効果があることがわかった。
※まばたきの1/20の速度
Amazonでは、100ミリ秒のスローダウン実験で売り上げが 1%減少した。 Bingと Googleの共同講演 (Schurman and Brutlag 2009)では、ユニークなクエリ数、収益、クリック数、満足度、クリックまでの時間などの主要なメトリクスにパフォーマンスが有意に影響することが示された。
私が働いている会社ではスピード改善策は検討が後手に回ることが多い印象。改めて各指標への影響度を捉えて動きたいと思いました。
最後にGoogleでHead Performance Engineerを担当されていたSteve Soudersの金言を載せておきます。
Webサイトが遅いと起こる危険:ユーザーの挫折、ネガティブなブランド認知、運用費の増加、収益の損失
8.実験を行う際に注意すべき事項
①曜日効果
平日と週末ではユーザーの分布が異なる場合がある。
同じユーザーだとしても、異なる行動をとる可能性もある。実験が週単位のサイクルを確実に捉えることは重要である。
そのため、最低でも 1週間は実験を実行することが推奨されている。
②季節性
祝日など、ユーザーの行動が異なる考慮すべき重要な時期が複数ある。
グローバルなユーザーベースを持っている場合、米国と米国以外の祝日が影響を与える可能性がある。
例えば、ギフトカードを販売することは、クリスマスシーズンには効果があるかもしれないが、他の時期には効果がないかもしれない。
これは外的妥当性と呼ばれ、とある期間の結果を他の期間に一般化できる程度のことを指す。
③プライマシー効果とノベルティ効果
実験初期の効果が大きくなったり小さくなったりする傾向があり、効果の安定に時間がかかる実験がある。
例えば、ユーザーが新しい派手なボタンを試してみたが、それが役に立たないことに気づき、そのボタンのクリック数は時間の経過とともに減少していく場合があり得る。
一方で、慣れが必要な機能は、その慣れの効果が現れるまで時間がかかる。
9.トワイマンの法則と実験の信用性
下記がトワイマンの法則の説明。
面白そうに見えると、それを中心にストーリーを作り、それを共有し、祝おうとする傾向が私たちにはある。一方で、結果が驚くほどネガティブな場合は、その研究の限界や小さな欠陥を見つけて、それを却下する傾向が私たちにはある。
実験結果を判断する側の人が持っているバイアスを理解しておく必要がある。
バイアスの好例として紹介されているのが生存者バイアス。興味深い内容。
第二次世界大戦で爆撃機に装甲を追加することが決定されたときのものである。飛行機が最もダメージを受けた場所について記録が残されており、軍は当然のことながら、飛行機が最も打撃を受けた場所に装甲を追加したいと考えていた。一方、 Abraham Waldは、これらは装甲を追加するには最悪の場所であると指摘した。弾丸の穴はほぼ一様に分布し、装甲が必要な場所に命中した爆撃機は……検査のために戻ってくることはなかったので、弾丸の穴がない場所にこそ装甲を追加すべきであった
トワイマンの法則を忘れず、検証結果を
受け止めていくことが大事。
10.インスティチューショナルメモリとは
インスティチューショナルメモリとは組織が過去に学んだことをどれだけ記憶しているかを示すものです。例えば、A/Bテストを実施した場合に下記を記録していく。
├どういう目的で
├どういう仕様で
├オーナーは誰で
├どれくらいの期間を実施し
├どんな結果が得られたか(どのようなメトリクスにどのような影響を与えたか)
インスティチューショナルメモリは、過去の実験と変化を捉え、データに基づいた意思決定を行う文化を奨励し、イノベーションや継続的な学習の促進に役立つ。
11.組織を運用するためのメトリクス
組織は進捗と説明責任を測定するために、
良いメトリクスを必要としている。
一般的に使用される組織メトリクス分類は、ゴール、ドライバー、ガードレールである。この分類は、会社全体から大きな組織内の特定のチームまで広く有用である。
ゴールメトリクス
ゴールメトリクスは、成功のメトリクスまたは真に重要なメトリクスとも呼ばれ、組織が最終的に何を大切にしているのかを反映している。
ゴールメトリクスを考えるさいには、まず何を求めているのかを言語化し明確にすることが推奨される。あなたのプロダクトはなぜ存在するのか、あなたの組織にとっての成功はどのようなものか、といったような質問に答えなくてはならない。
そして、その答えは多くの場合、ミッションステートメントに結び付けられる。
ドライバーメトリクス
ドライバーメトリクスは、代理指標、間接的または予測メトリクスと呼ばれ、ゴールメトリクスより短期的に動く、敏感なメトリクスである傾向がある。
ドライバーメトリクスは成功そのものよりもむしろ、組織を成功に導くためのメンタル因果モデルを反映、つまり成功要因は何かの仮説を反映する。
ガードレールメトリクス
ガードレールメトリクスは、そもそもの前提条件に違反することを防ぐためのものである。
テストに実質的に含まれる一連のメトリクスで、意図しない形での機能低下やユーザーエクスペリエンスの低下を検出する。
(ex.エラー数やレイテンシ等が対象になる)
12.実験成熟度モデル
新しいアイデアを試すコストを減らし、好循環のフィードバックループを作る組織には実験成熟度モデルが存在する。本書では下記4つに
成熟段階を分けている。
クロールフェーズ
目標は基礎的な前提条件の構築。
具体的には計測装置と基本的なデータサイエンスの能力、仮説検証に必要な要約統計量であり、数回の実験を設計、実行、分析できるようにする。
いくつかの実験を成功させ、その結果を意味のある前進の指針にして次のステージに進むための勢いを生み出す。
ウォークフェーズ
目標は、基礎的な前提条件と少数の実験の実行を行うフェーズから、標準的なメトリクスの策定とより多くの実験を実行するための組織作りに移る。
このフェーズでは、計測装置の検証、 A/Aテストの実行、およびサンプル比率のミスマッチ(SRM)テストの実行によって信用性を向上させる。
ランフェーズ
目標は実験をより大規模に実施すること。
メトリクスを包括的にし、その目標は、メトリクスのセットの合意か、複数のメトリクス間のトレードオフを内包するOECを成文化するためのすべての方法の実施。組織は、ほとんどの新機能と変更の評価に実験を使用するようになる。
フライフェーズ
ここまでくると、 A/ Bテストはすべての
変更の際の標準手法となっている。
新機能を作るチームは、データサイエンティストの助けを借りずに、ほとんどの実験、特に簡単な実験の分析に熟達している。
この規模のテストを助けるための自動化に移るだけでなく、すべての実験と変更を記録する制度(インスティチューショナルメモリ)を確立し、過去の実験からの学習を可能にし、驚くべき結果やベストプラクティスを共有し、実験文化を向上させることが目標となる。
補足
ちなみに実験成熟度モデルの説明は
こちらの方のnoteも参考にさせて頂きました。
13.何が成功を促進するか?について考えるための有用なフレームワーク
製品をさらに魅力なものにする方法を考える上で
重要性の高い観点/指標が理解できる2つのフレームワークを紹介。
・HEARTフレームワーク
├Happiness - 課題が解決された状態
├Engagement - 気に入っている状態
├Adoption - 新たに使い始めている状態
├Retention - 使い続けている状態
├Task Success - コア機能がワークしている状態
・Pirate Metrics(AARRR モデル)
├Acquisition - ユーザー獲得
├Activation - ユーザー活性化
├Retention - ユーザーの継続利用
├Referral - 友人や外のネットワークへの紹介
├Revenue - 収益
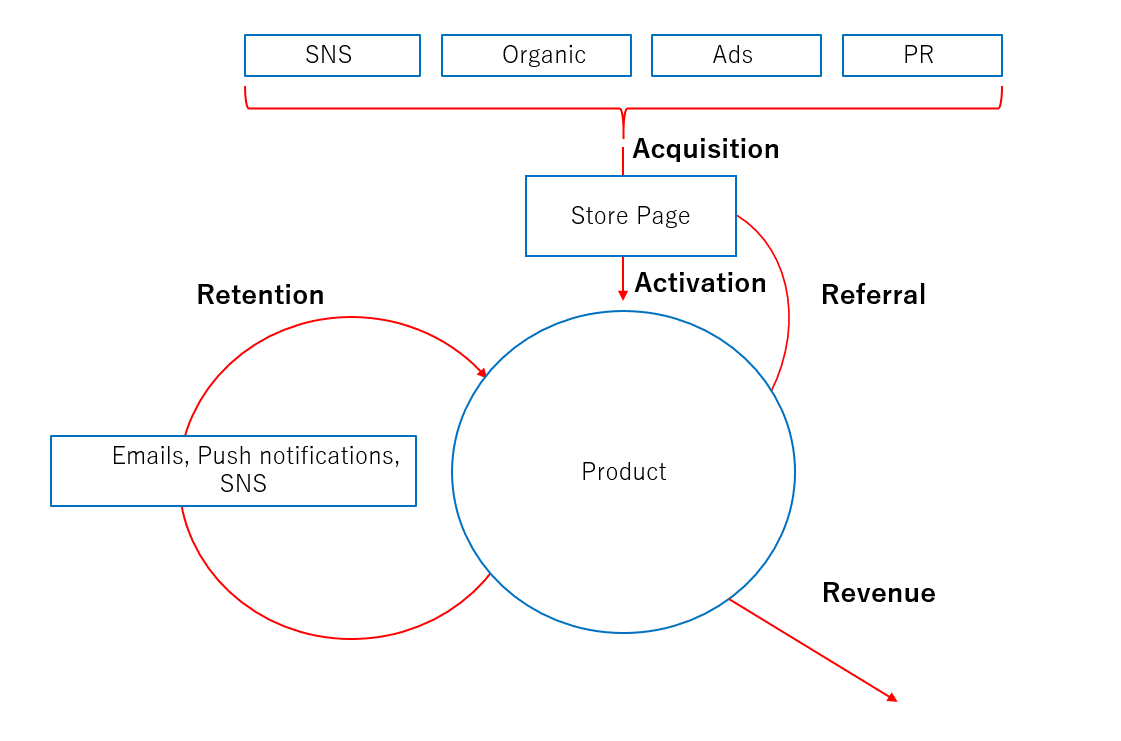
これらのフレームワークは、成功につながる過程を分解するのに役立つ。
例えば、典型的な企業は、最終的に収益を得る前に、ユーザーを獲得し、その製品がユーザーを維持するのに十分な魅力を持っていることを
確認しなければならない。
14.関係研究を実施する際の主な落とし穴は交絡因子
交絡因子とは測定された効果だけでなく、関心のある変化への因果関係の帰属にも影響を及ぼす可能性のある予期せぬ要因の総称。
交絡因子となるものは、認識されていない共通の原因であることが多い。
例えば、ヒトの場合、手のひらの大きさは寿命と強い相関関係がある。つまり平均的に手のひらが小さいほど長生きする。しかし、手のひらの小さと寿命の長さの共通の原因は性別である。女性は手のひらが小さく、平均して長生きする(米国では約 6年) 。
予期せぬ要因がないか?は担当者が健全に疑いながら実験を進めていく。
15.押さえておきたい用語やサイト
統計学の基本用語
下記は統計学の用語。ABテストツールを
適切に活用する為に正確に定義を把握しておく。

メタアナリシス
過去に実施された複数の研究結果を集めて統合し、再度分析を行う手法。
ベイズの定理
ベイズの定理とは、観察可能なデータを使用して
観察不能なものを推定する方法を示す式。
ベイズ推定の基本概念、そのメリット、問題点はこちらを参照ください。
GoodUI. org
繰り返し勝ったUIパターンを多数まとめているサイト。
GuessTheTest.com
GuessTheTest.comは、マーケターが効果的なA/Bテストを実践できるよう、実例やテンプレート、ガイドを提供するサイト。
Evidoo.io
Evidoo.ioは、eコマースに特化したA/Bテストデータベース。テスト結果を基に、ビジネスの改善アイデアが見つかります。
ABClassRKLI
Dr. Ronny KohaviによるA/Bテストクラス(bit.ly/ABClassRKLI)は、経験豊富な講師から信頼性のあるテスト方法を学べるコースです。
Maven.com
Maven.comは、専門家と共に学ぶコホート型のオンライン学習プラットフォーム。テーマごとに多様なクラスがあり、同じ目標を持つ仲間と進めることで深い学びが期待できます。
上記のプラットフォーム上でGood UIファウンダーのJakub Linowskiさんが『Change & Measure: Designing Maximum Impact AB Tests』などの講座を提供しています。
キャッシュヒット率
キャッシュヒット率は、キャッシュヒット数をキャッシュヒット数とキャッシュミス数の合計で割ったもの であり、コンテンツに対するリクエストをキャッシュがどの程度効果的に実行しているかを表す。
パーセンタイル
パーセンタイルは、「データの何パーセントがその値を下回るか」で定義されます。例えばデータの個数を50%に分ける値のことを50パーセンタイルと呼び、中央値と同一の値になります。
ホバー
対象物にマウスカーソルを重ねると、
自動で何らかの処理が行われること。
ロバスト
ロバストとは、堅牢な、頑強な、強靭な、などの意味を持つ英単語。「ロバストネス」(robustness:堅牢性)はその名詞形。
プロシキ
プロキシとは、インターネットを接続する際のアクセスを代理で行うシステムのこと。企業のセキュリティ対策として重要な役割を担い、セキュリティを強化できることから注目が集まっています。
16.最後に
この本の中で引用されていた内容ですが、ピーター・ドラッカーは"If you can't measure it, you can't improve it" (測定できないものは改善できない) という言葉を残しています。
改めて計測がマーケティングの肝であること、
そして奥が深くて面白い分野であることが分かりました。
読書後にリクルート新人研修の講義資料が本書を
要約した内容になっており、補完的に活用できると思いました。
担当サービスをさらに最適化できるように本の内容を活かしていこうと思います。
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?