
【基本の14問】SQL文の問題(基本情報技術者)

SQLではSELECT文がメインです。
表から必要なデータを抽出するからです。複数の表を繋いだり、条件に合う行だけ取り出したり、軽い集計・並び替え・グループ分けなどもできます。
色んな使い方ができるので、色んな「句」を覚えねばなりません。
小分けにしていきましょう。
令和06年06月から平成21年までの全ての試験問題を分析して、SQL問題は22問ありました。今回は基礎的な14問を取り扱います。
このNoteは、私がIP~高度(DB)まで独学合格した経験と、IT専門学校でした授業ノウハウに基づいて作っています。
それでは始めましょう!
もし自信がなければ、ITパスポートの復習からどうぞ(全5回)
【2問】SELECT文 | 2つの表の結合
データベースは、たくさんの表で構成されています。
データを抜き出す時に複数の表をつなげることは良くあります。
まずは「結合」の問題からやってみましょう。
ポイントは2点。
FROM句に結合する表を列挙する
WHERE句に結合のために紐づける項目を書く
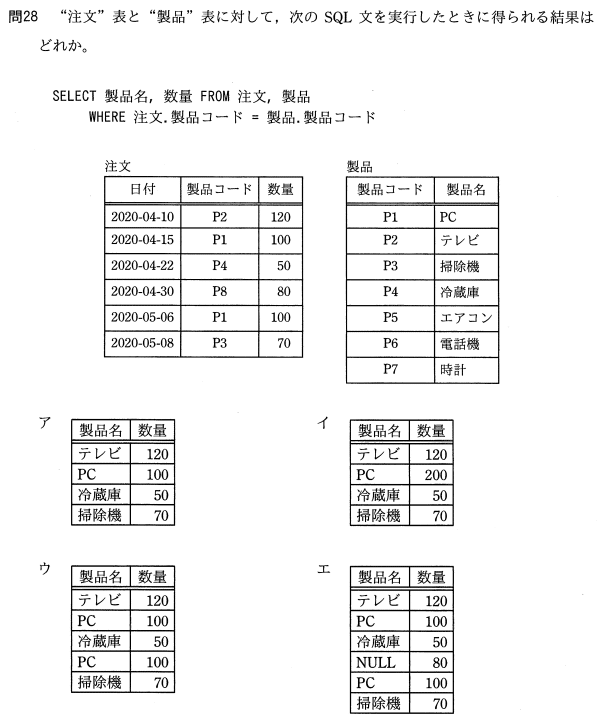
基本情報技術者試験修了試験 令和03年01月問28
正答はウ。
2つの表を製品コードで紐づけて結合し、製品名と数量が出力をさせます。
注文表のP2と製品表のP2→テレビ, 120
注文表のP1と製品表のP1→PC, 100
注文表のP4と製品表のP4→冷蔵庫, 50
注文表のP8と製品表にP8なし→結合できず
注文表のP1と製品表のP1→PC, 100
注文表のP3と製品表のP3→掃除機, 70

基本情報技術者試験修了試験 令和02年07月問28
基本情報技術者試験修了試験 令和04年01月問27
正答はウ。
学生表の所属列と学部表の学部名列を紐づけて、学部表の住所列が"新宿"の行を抜き出し、氏名を出力します。
(応用花子, 理, 新宿)と(理, 新宿)が結合、学部表の住所が新宿なので、応用花子を出力。
(高度次郎, 人文, 渋谷)と(人文, 渋谷)が結合、学部表の住所が新宿ではないので、出力されず。
(午前桜子, 工, 渋谷)と(工, 新宿)が結合、学部表の住所が新宿ではないので、出力されず。
(情報太郎, 工, 渋谷)と(工, 新宿)が結合、学部表の住所が新宿なので、情報太郎を出力。
なお、「学部.住所」は「学部表の住所列」と云う意味。
「所属 = 学部名」も「学生表.所属 = 学部表.学部名」と書いて構いませんで、使う2つの表で所属列と学部名列は、それぞれ学生表にだけ学部表にだけしかないため区別できるので省略できました。
住所列は2つの表に同じ名前であるため、「学部.住所」や「学生.住所」と記述する必要があります。
【2問】WHERE句 | 条件をつける
データベースには、たっくさんのデータがあるので、全て表示させたら大変です。
WHERE句を使うと、必要なデータだけ抽出できます。例えば「商品Aのデータ」とか「商品Aと商品Bのデータ」のように条件を付けられるんです。

正答はウ。
ア:左の(A AND B)で「2科目が平均点以上」になっているのでダメ。
イ:アと同じでダメ。
ウ:正しい。左の(A OR B)で「1科目か2科目が平均点以上」、右のNOT(A AND B)で「2科目とも平均点以上、ではない」を条件にしています。よってWHERE句全体で「1科目が平均点以上」となります。
エ:条件のWHERE句がないのでダメ。
過去問道場さんではベン図を使った説明もしてくれてますので、別アプローチもご覧になりたければどうぞ。

基本情報技術者試験修了試験 令和04年07月問28
正答はエ。
選択肢を見た感じ、以下の2条件の書き方が問われていますね。
条件1:「第1期から第4期の販売金額の平均が4000万円以上」
条件2:「どの期も3000万円以上」
アについて。条件1良し。条件2がダメ。ORなので「どれかの期が3000万円以上」になっています。そして条件1OR条件2なのでダメ。
イについて。条件1がダメ、合計になっているので「/4」が必要でした。条件2良し、条件1AND条件2で良し。
ウについて。分けの分からないことになっていますね。平均をしていないのでダメ。ORなのでダメ。それぐらいの浅さで弾いて良いです。まともに考えるより他の選択肢を考えた方が良いです。
エについて。条件1が良し、合計ですが「平均4000万円」と「合計16000万円」は同じですから。条件2良し、条件1AND条件2なので良し。
【3問】集合関数 | 軽めの集計計算
SQL文では簡単な集計ができます。
該当データの個数(行数)を数えたり、合計・平均・最大値や最小値などの計算もできます。
個数:COUNT()
合計:SUM()
平均:AVG()
最大値:MAX()
最小値:MIN()
見慣れた関数ですね。エクセルやgoogleスプレッドシートでも使うので。

基本情報技術者試験修了試験 令和03年12月問27
基本情報技術者試験修了試験 令和05年12月問20
正答はウ。
社員表と部門表を結合して、フロア2階の部署に所属する社員数を出力するSQL文です。
11011:総務:1階→カウントしない
11002:経理:2階→カウントする
11003:営業:3階→カウントしない
11004:営業:3階→カウントしない
11005:情報システム:2階→カウントする
11006:営業:3階→カウントしない
11007:企画:1階→カウントしない
12001:営業:3階→カウントしない
12002:情報システム:2階→カウントする
のようにすると、11002(経理)、11005(情シス)、12002(情シス)の3行が該当。よってCOINT()で3が出力されます。

正答はイ。
アは、2が出力されます。NP200の行を選び出し、数量の平均を計算します。(3+1)/2=2。
イでは、4が出力。出庫記録表の行数を数えます。
ウでは、3が出力。出庫記録表の数量の最大値が算出されます。
エでは、3が出力。2015-10-11の行だけを選び、数量の合計値が算出されます。1+2=3。

正答はイ。
ちょっと細かいので、何となく「イかな」「アとイで迷った」ならOKとしてくださいね。
ア:注文明細表の全行の数量の平均値が出力されます。しかし、2024/09/08 310(全体の平均数量)って表示はオカシイです。注文日を表示させなければ、適切と判断できました。イマイチはっきりしない理由ですが。
イ:注文日ごとに数量の平均値を出力します。
ウ:集合関数の中身(引数)は列名にします。AVG(SUM())はエラーになります。
エ:WHERE句で集合関数は使えません。
最悪失点しても良いです。あまり細かい仕様まで覚えても学習コスパが悪いです。
【2問】GROUP BY, ORDER BY, HAVING | 便利な機能
SQL文で集計する時に、便利な機能があります。
例えば「科目ごとの平均点を計算したい」「点数の良い順に表示させたい」「クラスの平均点が50点以上のクラスだけ表示させたい」などができます。
~ごと:GROUP BY
小さい順/大きい順:ORDER BY
グループの持っている特性:HAVING

基本情報技術者試験 平成31年春問27
基本情報技術者試験修了試験 令和02年06月問28
正答はイ。
やりたい処理の文章と、SQL文を対応付けて解きます。
クラスごと→GROUP BY クラス名
教科ごと→GROUP BY 教科名
クラス名, 教科名の昇順→ORDER BY クラス名, 教科名
確実にイに絞られます。
なお、「昇順」は小さい順、「降順」は大きい順。降順の時は「ORDER BY 列名 DESC」と書きますが、昇順の時は「ORDER BY 列名 ASC」または「ORDER BY 列名」のようにASCを省略もできます。
SQLの問題ではやりたい処理の言葉に注目して対応するSQL文を考えると良いです。「~ごと」「~別」ならGROUP BY、「~順」ならORDER BYは基本です。

正答はウ。
文章の言葉とSQL文の対応を見ます。学生ごと→GROUP BY 学生番号、GROUP BYして平均点→HAVING。これでウを選びます。
GROUPにした後の条件は、WHERE句ではなくHAVINGで行います。学生「ごと」に算出するためにGROUP BYを使い、GROUP BYした点数の平均点が80点以上を判定するためにHAVINGを使いました。
一応、各選択肢にも触れておきます。
ア:科目ごとの平均点を求めている
イ:文法上できない(後述)。できたとしても、各学生の全科目平均点を算出していない
ウ:学生ごとに平均点を求めている
エ:文法上できない(後述)。できたとしても各学生の全科目平均点を算出していない
細かいですが、句には使ってよい順番があります。WHERE, GROUP, HAVING, ORDERの順に使えます。
イとエは、GROUP BYの後にWHEREを使っているので文法的に誤りです。
【1問】LIKE | ゆるい条件
WHERE = "商品A"のように使うのが多いですが、「=」の代わりに「LIKE」を使うと、ゆるい条件を設定できます。

正答はイ。
「%」や「_」はワイルドカードと云います。Linuxでは「*」も使います。SQLでもCOUNT(*)と使います。
%:0文字以上の任意の文字
_:1文字の任意の文字
「UNIXを含む」なので探したい例は、UNIX, ○UNIX, ○○UNIX, UNIX○, UNIX○○などです。つまり前後に0文字以上の文字があるので「%UNIX%」。
もし「_UNIX_」だったら、○UNIX○だけが検索されます。AUNIXAとかAUNIXBとかZUNIXAとか。
【2問】CURSOR, FETCH | プログラムと来たら
SQLはプログラムのようにも使えます。
今までのSQL文を1つずつ入力するのは「対話型」。クライアントソフトを使ってデータベースにアクセスして出力を得てきます。いわゆるCUIですね。
一方「埋め込み型」は、プログラム言語にSQL文を書き込みます。
具体的な書き方は知らなくて良いので、2つだけ覚えてください。
CURSOR(カーソル):データベースの1行を指す目印
FETCH(フェッチ):データベースから1行取り出す処理

基本情報技術者試験修了試験 令和05年06月問20
基本情報技術者試験修了試験 令和06年06月問20
正答はア。
「プログラムときたら、CURSOR」と思って大丈夫。
イ:ORDER BY:小さい順or大きい順に並び変える。必ず覚えてください。
ウ:UNION:2つのSQL文の出力を結合します。FEでは、覚えなくて良いです。
エ:UNIQUE:一意制約する時に使います。APになったら知っても良いかもレベル。SELECT文では使いません。表を作るときに使います。
バリエーションがない問題です。旧FE午後でもAPでも「はいはいCURSORでしょどうせ」で正解できます。応用情報技術者試験(平成25年春問29)でも出るので、ここで一発押さえておきましょう。

正答はア。具体的な書き方は理解しなくて良いです。一発でCURSOR(カーソル)を選んで、次の問題に行ってください。
SQLを用いたプログラムと来たら、カーソル(CURSOR)またはFETCH(2行目)です。この2つぐらいしか問われません。
イ:スキーマ:DB設計に置いては、表や項目のこと。例えば、社員表(社員番号, 氏名, 部署コード)は、社員スキーマと呼びますね。
ウ:テーブル:表のこと。
エ:ビュー:仮想的な表のこと。
ビューについて補足します。
データベースは第三正規形を満たすように、たくさんの表(実表)で構成されています。
よくある処理にて、毎回結合すると負荷がかかってしまうので、予め結合した仮の表(ビュー)を用意しておくと負荷を軽減できます。
またセキュリティ的なメリットもあります。処理に必要な必要最低限の情報だけをビューに載せます。実表にアクセスさせないので、不必要なデータは見られませんし、不正に更新・削除もされません。
【2問】GRANT文 | データへのアクセス権限
SQL文はデータの抽出(SELECT文)だけではありません。
手始めに、よく出るGRANTだけ覚えておきましょう。データベースの表への権限を設定するSQL文です。
GRANT文では、あるユーザの、ある表に対する、SELECT(抽出), INSERT(追加), UPDATE(更新), DELETE(削除)の権限を付与したり取り消したりできます。

正答はエ。
「権限」ときたらGRANTで大丈夫。
ア:CONNECT:データベースに接続する時に使います。DBですら覚えなくて良いです。実際に使う時に覚えてください。
イ:CREATE ASSERTION:複数の表に渡る複雑な制約を作れます。具体的な使い方はAPでもDBでも覚えなくて良いです。
ウ:CREATE TABLE:表を作る命令。新FEでは不要。APから覚えても良い程度。
エ:GRANT:更新(UPDATE文)の権限を設定できます。
プログラムならCURSOR、権限ならGRANT程度で充分。応用情報技術者試験(平成31年春問27)でも出るので、ここで一発押さえておきましょう。

正答はエ。
「権限」一発で正解を引いて下さい。応用情報技術者試験(平成26年秋問25)でも出るので、ここで一発押さえておきましょう。
なお、イの「ビューの作成」は、CREATE VIEW文を使います。
FEでも出ますがAPやDBで意識し始めれば良いぐらいです。要は新しい表を作るSQL文。
まとめ
お疲れ様でした!
SELECT文の基本問題で正解できるようになったのではないでしょうか。
FROM句:データ元の表を指定
結合する時に複数の表を列挙
WHERE句:抽出条件を指定
結合に必要な条件も書ける
GROUP BY:グループ化する
「~ごと」「~別」
HAVING:グループの特性に条件を指定する
ORDER BY:小さい順(降順), 大きい順(降順)
昇順の時は「ASC」または省略
降順の時は「DESC」と必ず書く
さらに単発系を2~3個。
GRANT:データベース表への「権限」を設定
埋込みSQL:「プログラム」に書くSQL
CURSOR:処理する1行を指す目印
FETCH:1行ずつ取り出す処理
次は「難しいSQL問題(8問)」でお会いしましょう(準備中)。
p.s. 普段は >> 専門学校とIT就職のブログ << をやってます。
でわでわ(・ω・▼)ノシ
いいなと思ったら応援しよう!
