
小説同士を「計算」できる機械学習"Novel2Vec"を作ってみた

↑本モデルを簡単に触れるWebアプリを作ってみました。遊んでみてね。
僕はたまに小説を読むのですが、世の中にはたくさんの小説があります。何とかしてその大量にある小説から、僕に合った小説を効率的に探したい。そのためには、小説のことをコンピューターに機械学習させればいいのではなかろうか、と考えました。
そこで僕は、Word2Vecと全く同じですが、小説をベクトル化し、類似している小説を検索したり小説同士を計算できる機械学習モデル"Novel2Vec"を作ってみました。イメージとしては、超次元の単位球上に小説が配置される感じでしょうか。

こういう近代図書館があっても面白いかもしれませんね!
Word2Vecとは?
ここでは詳しくは触れませんが、単語を方向づけ(=ベクトル化)し、計算可能にする機械学習アルゴリズムです。例えば、
「妻」から「女」成分を引き算して、代わりに「男」成分を足し算する
→「夫」が推測される
などです。機械が言葉遊びをできるなんて、不思議ですよね。
ちなみにですが、単語や文章をベクトル化することでその言語を理解したり定量化するというアイデアは、Word2Vecに限らずとも自然言語処理系のモデルではほぼ全てに採用されています。
Word2Vecを採用した狙い
私は、このWord2Vecを小説に応用することにより、類似単語の検索を使って自分の好みの小説を探したり、演算を行える性質から次読みたいと思う小説を探したりできると考えました。
動作例
演算
『君の膵臓を食べたい』から『三日間の幸福』の成分を引き算して、代わりに『涼宮ハルヒの憂鬱』の成分を足し算する。
positive = ["君の膵臓を食べたい","涼宮ハルヒの憂鬱"]
negative = ["三日間の幸福"]
novel2vec.wv.most_similar_cosmul(
positive=positive,
negative=negative,
topn=20
)[('間の楔', 0.8572810888290405),
('グレイヴディッガー', 0.8521636724472046),
('奇貨', 0.8472990393638611),
('華麗なる探偵たち', 0.8408594131469727),
('ファウスト', 0.8313314318656921),
('朝が来る', 0.8187891244888306),
('ソドム百二十日', 0.8183324933052063),
('探偵になりたい', 0.8140184879302979),
('火喰鳥', 0.8090959787368774),
('終戦のローレライ', 0.8079931735992432),
('空中ブランコ', 0.8074293732643127),
('次郎物語', 0.8071666955947876),
('しゃばけシリーズ', 0.8060234785079956),
('ワニの町へ来たスパイ', 0.7987720370292664),
('幻想郵便局', 0.7945365905761719),
('新釈走れメロス', 0.7916215658187866),
('永い言い訳', 0.7907067537307739),
('永遠の0', 0.7860555648803711),
('破船', 0.7834833860397339),
('青春の蹉跌', 0.7829514145851135)]『空中ブランコ』などが候補に上がりました。
・・・って何を言っているのでしょうか。自分でもよくわかりません(おい)。どなたか解釈できる方がいらっしゃいましたら、私にご一報ください。
似ている小説検索
各小説はベクトルを持っています。例えば『世界から猫が消えたなら』は
novel2vec.wv.get_vector("世界から猫が消えたなら")array([-1.2590243 , 0.04318109, 0.11482742, 0.86522985, -0.7283665 ,
-0.47611585, 0.06895164, 0.12256092, -0.81474805, 0.81498724,
-0.48084846, -0.80436987, 0.42299318, -0.33910966, -0.26748407,
0.31394866, 1.249347 , -0.87575847, 0.04777403, 0.22165048,
-0.47682267, -0.62691075, -0.03210768, -0.96367013, 0.03391973,
-0.15963155, 0.8115573 , -0.53932095, -0.18761848, 0.09244851,
0.7820385 , -0.0505202 , -0.03936275, -0.12688738, 0.16127598,
-0.00822786, 0.09968314, -1.38125 , -0.20425405, -0.3827155 ,
-0.16361494, -0.4842695 , 0.2820893 , -0.50141346, 0.5834042 ,
-0.09333514, 0.3382366 , -0.06654274, -0.14748035, 0.20372497,
0.6415446 , -0.02493595, -0.46342885, -0.32231417, -0.61579 ,
0.05780239, -0.57211775, 0.13349907, -0.5365324 , -0.44372308,
1.9052724 , -0.36654872, -0.69528127, -0.40935397, -0.9121589 ,
-0.20932235, -0.590078 , 0.6147222 , -1.6410725 , 0.20152085,
-0.132651 , 0.06109683, 0.8181382 , -0.15118477, -0.05145394,
0.6072166 , 0.8721114 , 0.14139219, -0.616359 , 0.32421732,
-1.417822 , 0.13424514, -0.58967006, 0.77890974, 0.04448694,
0.4317336 , 0.69861376, 0.76428735, 0.8218267 , 0.29946548,
0.4885521 , -0.1438967 , 0.3070092 , 0.69627523, 0.38913506,
-0.63570184, 0.45269412, -0.3831728 , 0.41931432, -0.09499326],
dtype=float32)のようなベクトルを持っています。これとコサイン類似度が高い小説を探すと、
novel2vec.wv.most_similar_cosmul(
positive=["世界から猫が消えたなら"],
topn=20
)[('5', 0.739112913608551),
('死にがいを求めて生きているの', 0.7371859550476074),
('小暮写眞館', 0.7212374210357666),
('博多豚骨ラーメンズ', 0.7182766795158386),
('ままならないから私とあなた', 0.7178191542625427),
('都会のトムソーヤ', 0.7146751284599304),
('この世界にiをこめて', 0.7088941931724548),
('怪盗探偵山猫', 0.707535445690155),
('からくり夢時計', 0.7068319320678711),
('ムゲンのi', 0.7056276202201843),
('いつか、眠りにつく日', 0.7052060961723328),
('武道館', 0.7028481960296631),
('サマーランサー', 0.7003399133682251),
('氷菓シリーズ', 0.7002270817756653),
('生活維持省', 0.7001115083694458),
('階段島シリーズ', 0.7000018954277039),
('未来', 0.6984657645225525),
('トラペジウム', 0.6974828243255615),
('逆ソクラテス', 0.6934947371482849),
('かくしごと', 0.6934637427330017)]へえ・・・それぞれあらすじを見てみると、何となく似ているような気もします。今度読んでみようかな
どうやって作ったか
Word2Vecモデルは、1つの文章を単語が並んだ「コーパス」と捉え、それらを機械学習することで作られています。今回は、Twitterのハッシュタグ「名刺代わりの小説10選」でツイートされた小説リストを1つのコーパスと捉え、それらを機械学習することでNovel2Vecモデルを作りました。
ツイートのデータは以下を使用しました。ありがとうございます。
ツイート一覧を読み込む
Pandasを使ってツイート情報の一覧を読み込みます。
shosetsu_dataset_raw = pd.read_csv(directory/"shosetsu_dataset.csv")
shosetsu_dataset_raw
テキストマイニング
ツイートテキストからテキストマイニングを行うにあたり、以下のような仮定を置きました。
①以下の文字列を含む行には小説のタイトルは書かれていない。
AVOID_SIGNALS = [
'#','…', '※', '!', 'ω', 'ーー', 'タグ',
'↓', '↑', '→', '♯'
]②小説のタイトルは以下のようなパターンで書かれている。
[タイトル][スラッシュ・コロン・空白][著者]
[括弧はじめ][タイトル][括弧おわり]
[タイトル]
TITLE_RXTRACTION_RULES = [
(["/"], "(.*)/.*", 1),#タイトル/著者など
(["/"], "(.*)/.*", 1),
(["「", "」"], "「(.*?)」", 1),#「タイトル」
(["『", "』"], "『(.*?)』", 1),
(["【", "】"], "【(.*?)】", 1),
(["[", "]"], "(.*)\[.*?\]", 1),
(["(", ")"], "(.*)\(.*?\)", 1),
(["(", ")"], "(.*)(.*?)", 1),
([":"], "(.*):.*", 1),#タイトル:著者など
(["*"], "(.*)*.*", 1),
([":"], "(.*):.*", 1),
([" "], "([\S]*).*", 1),#タイトル[半角スペース]著者など
([], ".*", 0)#タイトルのみ
]③以下のような文字列は不要だ。
TITLE_JUSTIFICATION_RULES = [
("\s", ""),
("・", ""),
("\u3000", ""),
("\d\.", ""),#番号.
("[①②③④⑤⑥⑦⑧⑨]", ""),
("[■▫️▼◆◇○●⚫✧★☆☕️☑︎♢☺☾✨✵❁❇⭐︎⿻〇]", ""),
("pic\.twitter\.com", "")
]これらの仮定を元に、ツイートテキストから小説の題名のみを配列形式で出力するコードを以下のように組みました。
def justify_title(title:str)->str:
'''
抽出したタイトル内に不要な文字が混入していた場合、除去する。
params:
title:str 抽出したタイトル
returns:
title:str 不要な文字を除去したタイトル
'''
for rule in TITLE_JUSTIFICATION_RULES:
title = re.sub(rule[0], rule[1], title)
return title
def extract_title_from_rowtext(rowtext:str)->str:
'''
1行のツイートテキストから、タイトルを抽出する。
params:
rowtext:str 1行のツイートテキスト
returns:
title:str タイトル/もしもタイトルの抽出に失敗した場合はNone
'''
for keywords, pattern, index in TITLE_RXTRACTION_RULES:
try:
if all([x in rowtext for x in keywords]):
title = re.search(pattern, rowtext).group(index)
return justify_title(title)
except:
continue
return None
def any_avoid_signals(rowtext:str)->bool:
'''
そのツイートテキストの行が不要な行であるか調べる
params:
rowtext:str 1行のツイートテキスト
returns:
行が不要である場合、True
'''
for x in AVOID_SIGNALS:
if x in rowtext:
return True
return False
def extract_titles_from_tweet(tweet_text:str)->list:
'''
ツイートテキストから複数個のタイトルを抽出する。
params:
tweet_text:str ツイートテキスト
returns:
titles:list タイトルの配列
'''
titles = []
if type(tweet_text) is not str:
return titles
for rowtext in tweet_text.split('\n'):
if rowtext == '' or any_avoid_signals(rowtext):
continue
title = extract_title_from_rowtext(rowtext)
if title is not None:
titles.append(title)
if len(titles) == 10:
break
return titlesテキストマイニング例
extract_titles_from_tweet("""
#名刺代わりの小説10選
いっきまーす!!
①『10万光年彼方の星から女の子が迷い込んできたので俺ん家に泊めることにした』蓑手亘
②『女の子と体が入れ替わった3時間後の俺が俺に色々してくるんだがwww』芝谷悠仁
③『変なキノコを食べたら性染色体を制御できるようになってしまった』早馬猫八
④『新百合ヶ丘』宮橋あさひ
⑤『超絶美少女な俺の女クローンを見てくれ』祝園久作
⑥『性癖多様性時代を生きるために』松茂徳二郎
10個いかなかった...ごめんな
""")['10万光年彼方の星から女の子が迷い込んできたので俺ん家に泊めることにした',
'女の子と体が入れ替わった3時間後の俺が俺に色々してくるんだがwww',
'変なキノコを食べたら性染色体を制御できるようになってしまった',
'新百合ヶ丘',
'超絶美少女な俺の女クローンを見てくれ',
'性癖多様性時代を生きるために',
'10個いかなかった...ごめんな']こんな感じで小説の題名を抽出できます。ごくたまに題名じゃないノイズもすり抜けてきてしまいますが…。
コーパスデータを作る
先ほど作ったテキストマイニングのメソッドを、全ツイートテキストに対して行います。
titles_corpuses_all:list = []
for tweet_text in tqdm(shosetsu_dataset_raw['tweet']):
titles = extract_titles_from_tweet(tweet_text)
if len(titles) > 0:
titles_corpuses_all.append(titles)print(f'元々のツイート数:{len(shosetsu_dataset_raw)}/抽出したコーパス数:{len(titles_corpuses_all)}')元々のツイート数:8790/抽出したコーパス数:8352titles_corpuses_all[['流しの下の骨',
'デッドエンドの思い出',
'グロテスク',
'仮面の告白',
'薬指の標本',
'銀河鉄道の夜',
'六番目の小夜子',
'モダン'],
['青い虚空', '野生の呼び声', '死者との結婚', 'エノーラホームズの事件簿', '鋼鉄都市'],
['夜市',
'リリエンタールの末裔',
'本と鍵の季節',
'ななつのこ',
'深川澪通り木戸番小屋',
'ウォッチャーズ',
'夜の翼',
'墓守りのレオ',
'窓の向こうのガーシュウィン',
'ことり'],
['空の境界', '花守の竜の叙事詩', '光の帝国常野物語'],
['零崎軋識の人間ノック',
'零崎曲識の人間人間',
'零崎双識の人間試験',
'零崎人識の人間関係',
'零崎人識の人間関係',
'零崎人識の人間関係',
'零崎人識の人間関係',
'人類最強の純愛',
'人類最強のときめき',
'人類最強の初恋'],
['神様のカルテ',
'海辺のカフカ',
'TUGUMI',
'風が強く吹いている',
'猫を抱いて象と泳ぐ',
'夏への扉',
'MOMENT',
'天使の卵',
'ハリーポッターと謎のプリンス'], ...このようにして、コーパスデータが出来上がりました。
登場数の多いデータのみを抽出する
でも、抽出した題名の中には、本来不要であるはずの行やタイプミスしているようなノイズも取り切れずに混ざっているはずです。僕が先ほど挙げた例が最たるものです。ここでは、題名別にその登場数を計測し、登場数の多いデータのみを抽出することで、ノイズを除去します。
def flatten_lists(lists:list)->list:
'''
配列の中に配列が入っているという入れ子状態をほどき、全ての要素を1次元配列に並べる。
params:
lists:list 入れ子状態となっている配列
returns:
elements
'''
elements = []
for list_ in lists:
elements += list_
return elements
title_count_all = dict(Counter(flatten_lists(titles_corpuses_all)))
title_count_all{'流しの下の骨': 11,
'デッドエンドの思い出': 17,
'グロテスク': 33,
'仮面の告白': 57,
'薬指の標本': 72,
'銀河鉄道の夜': 299, ...fig, ax = subplots(1, 1)
ax.hist(list(title_count_all.values()), bins=10, range=(1,8))
ax.set_xlabel('times of appearance')
ax.set_ylabel('number of title')
show()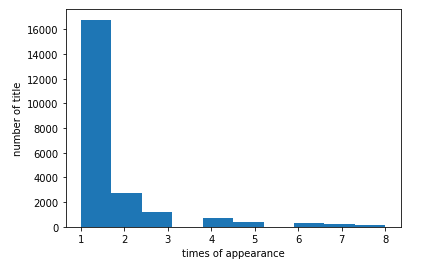
3回以上登場しているタイトルのデータのみを残します。
TITLE2COUNT:dict = {k:v for k,v in title_count_all.items() if v >= 3}
TITLE_SET:set = set(TITLE2COUNT.keys())
print(f'小説は全てで{len(TITLE_SET)}種類')
titles_corpuses = []
for titles_in_corpus in titles_corpuses_all:
titles_corpuse = list(filter(lambda x:x in TITLE_SET, titles_in_corpus))
if len(titles_corpuse) > 0:
titles_corpuses.append(titles_corpuse)
titles_corpuses小説は全てで4325種類
[['流しの下の骨', 'デッドエンドの思い出', 'グロテスク', '仮面の告白', '薬指の標本', '銀河鉄道の夜', '六番目の小夜子'],
['野生の呼び声', '鋼鉄都市'],
['夜市', '本と鍵の季節', 'ななつのこ', 'ウォッチャーズ', '窓の向こうのガーシュウィン', 'ことり'],
['空の境界', '光の帝国常野物語'],
['零崎双識の人間試験', '零崎人識の人間関係', '零崎人識の人間関係', '零崎人識の人間関係', '零崎人識の人間関係'],
['神様のカルテ',
'海辺のカフカ',
'TUGUMI',
'風が強く吹いている',
'猫を抱いて象と泳ぐ', ...こうしてできた綺麗なコーパスデータを保存します。
def save_novel_corpus_data(fp):
global titles_corpuses, TITLE2COUNT
with open(fp, 'wb') as file:
pickle.dump({
'titles_corpuses':titles_corpuses,
'TITLE2COUNT':TITLE2COUNT
},file)コーパスデータの読み出し
novel_corpus_dataという変数内に、pickleによりデシリアライズしたオブジェクトを代入していることを前提とします。
titles_corpuses:list = novel_corpus_data['titles_corpuses']
TITLE2COUNT:dict = novel_corpus_data['TITLE2COUNT']Word2Vecを起動する
さてお待ちかね、Novel2Vecモデルを作成するお時間がやってまいりました。
Novel2Vecモデルは、Word2Vecです。なので、gensim.modelsのWord2Vecを起動します。
novel2vec = Word2Vec(
window=10,
min_count=1,
sg=1,#skip-gram
)
novel2vec.build_vocab(titles_corpuses)
novel2vec.train(
corpus_iterable=titles_corpuses,
total_examples=novel2vec.corpus_count,
epochs=1000
)ここでは学習アルゴリズムとして、skip-gramを使いました。
モデルの保存
数秒で学習は終わります。出来上がったモデルを保存します。
with open(PWD / 'novel2vec_skipgram_gensim4_100dim.model', 'wb')as file:
novel2vec.save(file)モデルの読み出し
これだけで読み出しできるんですよ…すごい
novel2vec = Word2Vec.load(str(
PWD / "novel2vec_skipgram_gensim4_100dim.model"
))完成
こうして、無事にNovel2Vecを作ることができました。動作例は、冒頭で説明した通りです。
考察と今後について
このモデルを誰でも自由に動かせるように、何らかの方法で公開したいですね。→Hugging Face Spaceに公開しました。
小説の演算については、足し算や引き算が具体的にどのような意味を持つのか、よくわかりません(おい!!)。何か分かった方は、僕まで連絡お願いいたします。今のところは、Novel2Vecは類似した小説を探すためのツールとして使うのにとどまるでしょう。
実際にWord2Vecモデルを作ることにより、機械学習についてより理解を深められたと思います!