
Filemakerで蔵書管理アプリを自作した話(その2)

Filemakerで蔵書管理アプリを自作した話、今回はネットから書籍に関する情報を拾い上げる方法についてです。
2024年1月25日更新
NDLサーチの仕様が変更されたのに伴い、修正対応しました。
書籍データのオンラインデータベース
書籍に限らず、なにか商品情報を調べようとした時にアクセスしやすいのはAmazonで、膨大なデータベースがあります。最初に利用できるデータベースを探していた2014年頃、なんとかして利用できないのか、と試行錯誤したのですが、膨大さゆえに扱いづらさを感じたことを覚えてます。
書籍のデータベースとして利用できるのは知っている範囲では
国立国会図書館
楽天Books
版元ドットコム
このうち前回でも利用した版元ドットコムは、とても使いやすそうなのですが、最初に作成した当時は知らなかったのか今の形ではなかったのか、候補に上がりませんでした。今見るととても使いやすそうなので今度やってみようと思います。
国立国会図書館のサーチ機能にアクセスしてみる
国立国会図書館の検索ページはこちらです。「詳細検索」ではいろんな条件で検索できます。商業ベースではなく、国内の出版物はほぼ全て網羅しているその信頼感は随一です。
サイト内に、「 APIのご利用について」というページがあり、そこに仕様の概要がまとめられています。API仕様は細かく記載されているPDFもあり、ダウンロードできます。
一般的に、インターネット検索時に起きているのは基本的に、検索条件をURLの文字列として送信(リクエスト)して、その結果として送られてくるXMLを受信し、体裁を整えたものをブラウザで表示するということです。細かいことは私もそこまで詳しくないので省きますが、今回行おうとしているのは、「指定したISBNで検索し、結果として送られてくるヒット件数1のXMLから必要なデータを抜き出す」ことです。
とにかくまず、使用してるURLを見てみます。
https://ndlsearch.ndl.go.jp/api/sru?operation=searchRetrieve&recordSchema=dcndl&query=isbn=[ISBN]&maximumRecords=1
”&query=isbn" の部分でISBNによる検索であることを示し、その後ろに[ISBN]フィールドに格納されてる13桁コードを繋げ、検索結果の最大件数を1に指定します。
"recordSchema"は返ってくるデータの記述形式ですが、ここでは省略します。
こうやって作成されたURLは以下の通り。実際にを開いてみてください。今回も「バカの壁」です。
https://ndlsearch.ndl.go.jp/api/sru?operation=searchRetrieve&recordSchema=dcndl&query=isbn=9784106100031&maximumRecords=1リクエストに対してこのようなデータが返され、テキストで表示されます。

画面がテキストで埋め尽くされて面食らいますが、よくよくみてみると、真ん中あたりに書籍の情報が箇条書きのように並んでいるのが見つかります。ISBNを元に作ったURLを送信して返ってくるこのテキストを読み込んで、テキストの中から必要な情報をピックアップする処理を行います。
Filemaker内にテキストを表示させる
上に示したURLのうち、13桁コードの部分を格納しているフィールド名にした計算フィールドと、検索結果を格納するテキストフィールドを作成し、レイアウトします。
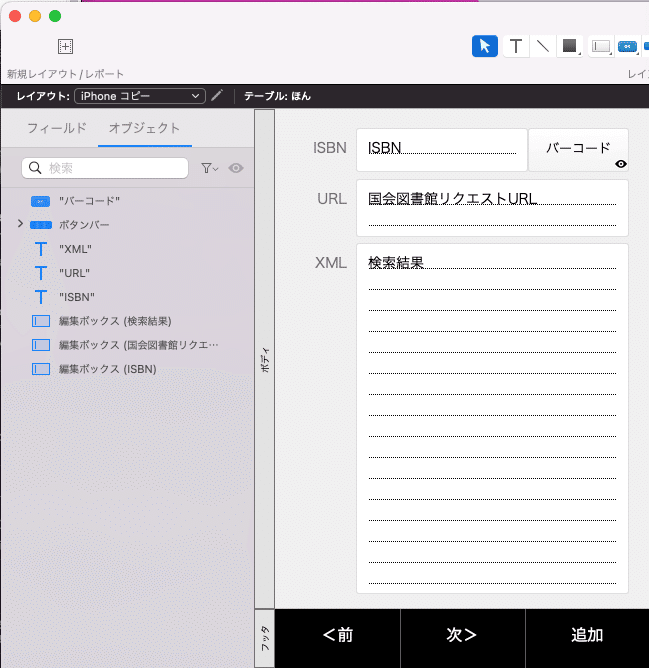
「検索結果」フィールドにURLの内容を流し込むスクリプトを作成し、ボタンで動作するようにします。前回同様、流し込む前に一度空欄にするステップを入れておきます。

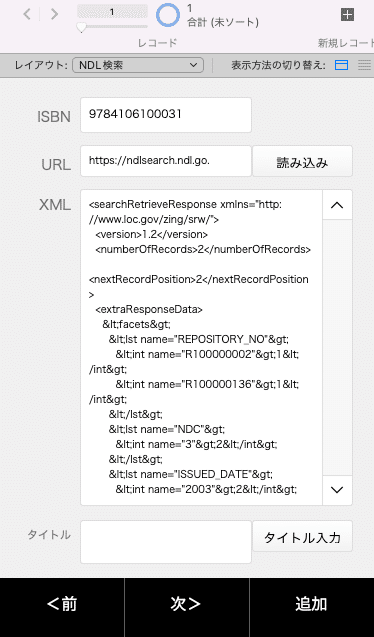
これで読み込んだ結果が以下の通りです。ウィンドウが小さいので途切れてますが、リクエストURLも戻ってきたXMLも全て格納されています。
表示されたテキストから必要な情報を抽出する
ここで改めて、XMLの記述を見てみましょう。真ん中あたりには書籍情報はこのように記述されています。見やすいように改行を入れています。
<dcterms:title>バカの壁</dcterms:title>
<dc:title>
<rdf:Description> <rdf:value>バカの壁</rdf:value>
<dcndl:transcription>バカ ノ カベ</dcndl:transcription>
</rdf:Description>
</dc:title>
<dcterms:creator>
<foaf:Agent> <foaf:name>養老, 孟司</foaf:name>
<dcndl:transcription>ヨウロウ, タケシ</dcndl:transcription>
</foaf:Agent>
</dcterms:creator>
<dc:creator>養老孟司著</dc:creator>
<dcterms:publisher>
<foaf:Agent> <foaf:name>新潮社</foaf:name> </foaf:Agent> </dcterms:publisher>
<dcndl:publicationPlace rdf:datatype="http://purl.org/dc/terms/ISO3166">ja</dcndl:publicationPlace>
<dcterms:date>2003.4</dcterms:date>
<dcterms:issued rdf:datatype="http://purl.org/dc/terms/W3CDTF">2003</dcterms:issued>
<dcterms:subject rdf:resource="http://id.ndl.go.jp/class/ndc9/304"/> <dc:subject rdf:datatype="http://ndl.go.jp/dcndl/terms/NDC8">304</dc:subject>
<dcterms:language rdf:datatype="http://purl.org/dc/terms/ISO639-2">ja</dcterms:language>
<dcterms:extent>18cm</dcterms:extent>
<dcndl:materialType rdf:resource="http://ndl.go.jp/ndltype/Book" rdfs:label="図書"/>
<dcterms:audience>一般</dcterms:audience>
例えばタイトルは<dcterms:title>、著者名は<dc:creator>というように、属性を示す符号とともに記述されています。書籍のクレジットは複雑なものもあるので、対応するために入れ子構造にしたりしていますが、テキスト関数を使って、これらの符号の位置を頼りに必要情報を拾い上げます。
Position
目的
テキスト内で検索テキストを検索し、指定された回数目の先頭文字位置を返します。
構文
Position ( テキスト ; 検索テキスト ; 先頭文字位置 ; 回数 )
Middle
目的
テキストの先頭文字位置で指定された文字から、文字数で指定された文字数分のテキストを抽出します。
構文
Middle ( テキスト ; 先頭文字位置 ; 文字数 )
この2つの関数を使ってタイトルを抜き出す関数を作ると次のようになります。
Middle ( 検索結果 ; Position ( 検索結果 ; "<dcterms:title>" ; 1 ; 1 ) + 15 ; Position ( 検索結果 ; "</dcterms:title>" ; 1 ; 1 ) -Position ( 検索結果 ; "<dcterms:title>" ; 1 ; 1 ) - 15 )
<dcterms:title>の位置を検索し、その位置から15文字("<dcterms:title>"の長さ)後ろから文字列を抽出する。
文字列の長さは</dcterms:title>の位置から<dcterms:title>の位置を引き、さらに15文字引いた分
FileMaker内では"<"は”<"として、">"は">"として処理されますので、それぞれ置き換え、抜き出す文字列の長さもそれに合わせて変更します。
Middle ( ほん::検索結果 ; Position (ほん::検索結果 ; "<dcterms:title>" ; 1 ; 1 ) + 21 ; Position ( ほん::検索結果 ; "</dcterms:title>" ; 1 ; 1 ) -Position ( ほん::検索結果 ; "<dcterms:title>" ; 1 ; 1 ) - 21 )
この処理をタイトル以外の必要な属性全てについて行いますが、ここではタイトルのみを入力するスクリプトを作り、ボタンで抽出して入力できるようにしておきます。

ひとまずこれで、バーコードを読み込んで国会図書館検索し、タイトルを入力するまでの操作がキーボードを使わずにできるようになりました。
3つのスクリプトをまとめてしまえば、バーコードを読んでからタイトル入力まで自動で処理されますが、現段階では1ステップずつ処理しています。
今回も作成したファイルを置いておきます。iPhoneで遊んでみてください。

この記事が気に入ったらチップで応援してみませんか?