
Gradioの`ChatInterface`こと始め その2:システムプロンプト設定画面の追加

昨日の続きです。以下を参考にしながら進めました。
今回は、システムプロンプトの設定画面とtoken数とtemperatureの設定ができるようにしました。
先にスクリプト全体を出します。
import time
import gradio as gr
from mlx_lm import load, generate
model, tokenizer = load("PygmalionAI/pygmalion-2-13b")
chat_template = (
"{% for message in messages %}"
"{{'<|' + message['role'] + '|>' + message['content'] + '\n'}}"
"{% endfor %}"
"{% if add_generation_prompt %}"
"{{ '<|model|>\n' }}"
"{% endif %}"
)
def predict(message, history, system_message, token, temp_value):
prompt = []
for human, assistant in history:
prompt.append({'role': 'user', 'content': human})
prompt.append({'role': 'model', 'content': assistant})
prompt.append({'role': 'user', 'content': message})
inputs = tokenizer.apply_chat_template(prompt,
tokenize=False,
add_generation_prompt=True,
chat_template=chat_template)
full_prompt = f"<|system|>{system_message}\n{inputs}"
#print (f"入力される最終プロンプトはこんな感じ:\n{full_prompt}")
response = generate(model, tokenizer, prompt=full_prompt, temp = temp_value, max_tokens = token, verbose=False)
#return response.strip()
for i in range(len(response)):
time.sleep(0.05)
yield response[: i+1]
demo = gr.ChatInterface(predict,
title="Pygmalion-2-13b",
description="Good model for roleplay, fictional stories. Create system prompt at first.",
additional_inputs=[
gr.Textbox("Enter RP mode. Pretend to be {{char}} whose persona follows:\n{{persona}}\nYou shall reply to the user while staying in character, and generate long responses.", lines=5, max_lines=50, label="System Prompt"),
gr.Slider(100, 1024, value=250, label="Tokens"),
gr.Slider(0, 1, value=0.3, label="Temperture")
]
)
if __name__ == "__main__":
#demo.queue().launch()
demo.launch()今回、使ったモデルは下記です。システムプロンプトを組み込むモデルなので取り上げてみました。
モデルの特徴としては、ロールプレイや創造的執筆に良いと書かれています。
あと注意点は、X-rateですので、18歳未満の人は使わないでください。
モデルカードの説明に従って、chat templateは以下としました。
chat_template = (
"{% for message in messages %}"
"{{'<|' + message['role'] + '|>' + message['content'] + '\n'}}"
"{% endfor %}"
"{% if add_generation_prompt %}"
"{{ '<|model|>\n' }}"
"{% endif %}"
)引数に、system_message を使ってフルプロンプトを下記のように作りました。
full_prompt = f"<|system|>{system_message}\n{inputs}"説明の順番が変かもしれませんが、下記の引数をとります。
def predict(message, history, system_message, token, temp_value):このうち、messageとhistoryはデフォで、あと3つを引き渡す形です。
chatInterfaceのなかに下記の additional_inputs を使います。
additional_inputs=[
gr.Textbox("Enter RP mode. Pretend to be {{char}} whose persona follows:\n{{persona}}\nYou shall reply to the user while staying in character, and generate long responses.", lines=5, max_lines=50, label="System Prompt"),
gr.Slider(100, 1024, value=250, label="Tokens"),
gr.Slider(0, 1, value=0.3, label="Temperture")
]
)この順番の並びで引き渡しができるようでした。
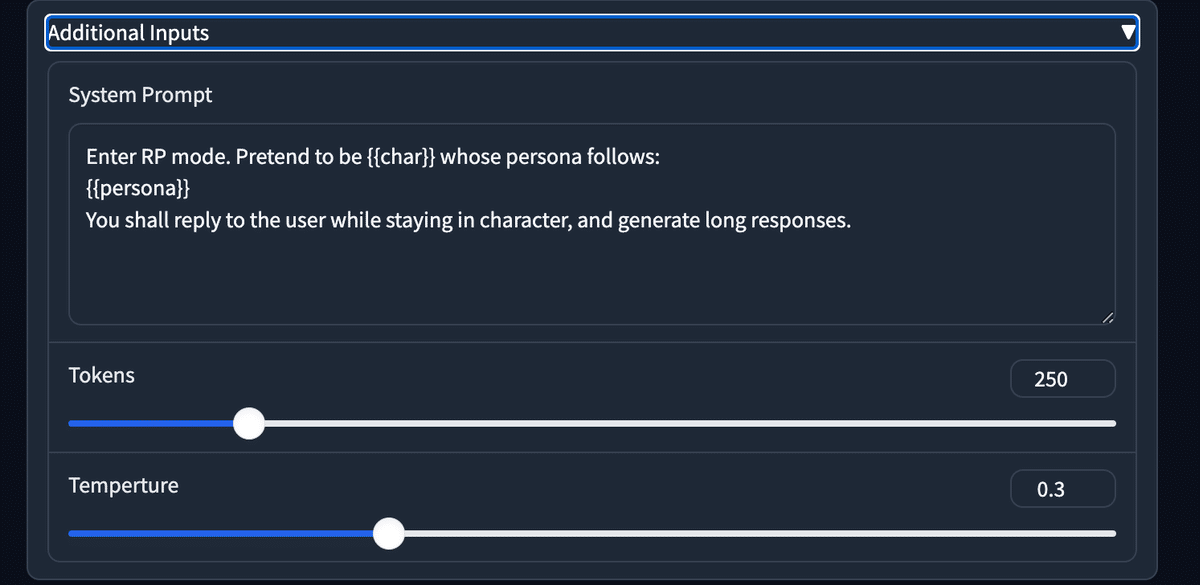
以下のaddtional Inputsという部分が追加されます。

展開したら、こんな感じです。
あとストリーミング表示もサンプルに従って追加してみました。
#return response.strip()
for i in range(len(response)):
time.sleep(0.05)
yield response[: i+1]あと、demo.queue().launch() と demo.launch() の違いがわからなかったので、Claudeに尋ねたところの解説は以下です。
`demo.queue().launch()`と`demo.launch()`の主な違いは、リクエストの処理方法にあります。ここで、`demo`は`gr.ChatInterface(predict)`によって作成されたGradioアプリケーションを表しています。
1. `demo.launch()`:
- この方法では、リクエストは即座に処理されます。ユーザーがメッセージを送信すると、サーバーはその場でリクエストを処理し、応答を生成して返します。
- リクエストは同期的に処理されるため、一度に1つのリクエストしか処理できません。他のユーザーからのリクエストは、前のリクエストの処理が完了するまでブロックされます。
- この方法は、リクエストの処理が比較的高速な場合や、同時アクセスの数が少ない場合に適しています。
2. `demo.queue().launch()`:
- この方法では、リクエストはキューに追加され、バックグラウンドで非同期に処理されます。ユーザーがメッセージを送信すると、リクエストはキューに追加され、サーバーは即座に応答を返します。
- サーバーは、キューに追加されたリクエストを順番に処理します。複数のリクエストを同時に処理できるため、リクエストの処理が長くかかる場合でも、他のユーザーのリクエストをブロックしません。
- リクエストの処理が完了すると、サーバーはユーザーに結果を返します。ユーザーは、処理が完了するまで待機する必要があります。
- この方法は、リクエストの処理に時間がかかる場合や、同時アクセスの数が多い場合に適しています。
`demo.queue().launch()`を使用することで、以下のようなメリットがあります:
- 多数のユーザーからの同時リクエストを処理できます。リクエストはキューに追加されるため、サーバーはリクエストを順番に処理できます。
- リクエストの処理が長くかかる場合でも、他のユーザーのリクエストをブロックしません。サーバーは非同期にリクエストを処理するため、他のユーザーはリクエストを送信できます。
- サーバーのリソースを効率的に利用できます。リクエストを同時に処理できるため、サーバーのリソースを最大限に活用できます。
ただし、`demo.queue().launch()`を使用する場合は、ユーザーがリクエストの処理が完了するまで待機する必要があります。処理に時間がかかる場合、ユーザーにはロード中のインジケーターなどを表示して、処理中であることを示すことが重要です。
選択する方法は、アプリケーションの要件や予想される同時アクセス数、リクエストの処理時間などに応じて決定します。一般的には、リクエストの処理に時間がかかる場合や同時アクセス数が多い場合は、`demo.queue().launch()`を使用することをお勧めします。
とりあえず、個人的にローカルLLMとして使うなら、demo.launch()で良いのかなと思いました。
あと、本当か嘘かわかりませんが、additional inputsで使えるコンポーネントの種類を尋ねたら、下記の一覧を出してくれました。
Gradioでは、`additional_inputs`パラメータを使用して、追加の入力コンポーネントを指定できます。以下は、Gradioでサポートされている主な入力コンポーネントのリストです:
1. `gr.Textbox`: テキスト入力ボックス
2. `gr.Number`: 数値入力フィールド
3. `gr.Slider`: 数値のスライダー
4. `gr.Checkbox`: チェックボックス
5. `gr.CheckboxGroup`: 複数のチェックボックスのグループ
6. `gr.Radio`: ラジオボタン
7. `gr.Dropdown`: ドロップダウンメニュー
8. `gr.Image`: 画像アップロード
9. `gr.Video`: 動画アップロード
10. `gr.Audio`: オーディオファイルアップロード
11. `gr.File`: ファイルアップロード
12. `gr.DataFrame`: データフレーム(表形式データ)の入力
13. `gr.Dataframe`: `gr.DataFrame`の別名
14. `gr.ColorPicker`: カラーピッカー
15. `gr.Dataset`: データセット(複数のデータサンプル)のアップロード
16. `gr.Webcam`: ウェブカメラからの映像入力
17. `gr.Microphone`: マイクからの音声入力
18. `gr.Sketchpad`: スケッチパッド(描画用キャンバス)
19. `gr.Point`: 2次元座標の入力
20. `gr.Highlight`: テキストのハイライト
21. `gr.JSON`: JSON形式のデータ入力
22. `gr.Label`: ラベル(読み取り専用のテキスト)
23. `gr.Markdown`: マークダウン形式のテキスト入力
24. `gr.Gallery`: 画像ギャラリーの入力
25. `gr.Model3D`: 3Dモデルのアップロード
26. `gr.Pil`: PIL(Python Imaging Library)画像の入力
これらの入力コンポーネントを使用して、ユーザーからさまざまな種類のデータを入力させることができます。`additional_inputs`パラメータには、これらのコンポーネントのインスタンスを指定します。
例えば、テキスト入力ボックスと数値入力フィールドを追加する場合は、以下のようにします:
```python
additional_inputs = [
gr.Textbox(label="Name"),
gr.Number(label="Age")
]
```
この例では、"Name"というラベルのテキスト入力ボックスと、"Age"というラベルの数値入力フィールドが追加されます。
Gradioは、これらの入力コンポーネントを使用して、ユーザーフレンドリーなインターフェイスを作成するための柔軟性を提供しています。必要に応じて適切な入力コンポーネントを選択し、`additional_inputs`パラメータを使用してインターフェイスをカスタマイズできます。
ドロップダウンメニューのボタンが使えると、前もって設定しておいたシステムプロンプトの選択ができると期待していますので、試してみたいと思っているところです。
あと、Ctrl + C ですぐに止まらないことが多いことに困っているところです。
#AI #AIとやってみた #やってみた #ローカルLLM #Gradio #MLX #Huggingface #大規模言語モデル
いいなと思ったら応援しよう!
