
Gradio こと始め その10:Gradio版MLX-VOICE-Chat をつくってみた

昨日は、MacのSiri音声でLLMの生成文を出力するのをつくってみましたが、そうなると音声入力もしたくなりました。
気がつくと、mlx-whisperがpipでインストールできるようになっていましたので、ちょっと頑張ってみました。
つまずいた点は、gr.Audio(sources="microphone") の部分です。
gr.Audio(sources=["microphone"], type="filepath") とすることで、mlx-whisperにオーディオを渡すことができました。
とりあえず、実行環境上に mlx-whisperを取り込みます。
Setup
Install ffmpeg:
# on macOS using Homebrew (https://brew.sh/)
brew install ffmpeg
Install the mlx-whisper package with:
pip install mlx-whisper
llmは前回同様、mlx-community/Llama-3.1-Swallow-8B-Instruct-v0.1-8bit を使いました。
whisperのモデルは、mlx-community/whisper-large-v3-turbo も試しましたが、kaiinui/kotoba-whisper-v2.0-mlx の方が軽くていい感じです。
あと前回同様、パラメータは自分好みでスクリプトの中で設定してもらえばと思います。
スクリプト本体
import os
os.environ["TOKENIZERS_PARALLELISM"] = "false" # ここで設定
import gradio as gr
import subprocess
import mlx_whisper
from mlx_lm import load, generate
system_message = "あなたは優秀な日本人AIアシスタントです。"
model, tokenizer = load("mlx-community/Llama-3.1-Swallow-8B-Instruct-v0.1-8bit")
generation_args = {
"max_tokens": 1200,
"temp": 0.7,
"repetition_penalty": 1.2,
"repetition_context_size": 20,
"top_p": 0.95,
}
history = []
history.insert(0, {'role': 'system', 'content': system_message})
def speak_process(text, voice="Kyoko", rate=205): #rateは話すスピード defalutは200らしい
subprocess.run(["say", "-v", voice,"-r", str(rate), text])
def transcribe(audio_file):
#result = mlx_whisper.transcribe(audio_file,language="ja", path_or_hf_repo="mlx-community/whisper-large-v3-turbo")["text"]
result = mlx_whisper.transcribe(audio_file,language="ja", path_or_hf_repo="kaiinui/kotoba-whisper-v2.0-mlx")["text"]
history.append({'role': 'user', 'content': result})
prompt = tokenizer.apply_chat_template(history, tokenize=False, add_generation_prompt=True)
response = generate(model, tokenizer, prompt=prompt, **generation_args)
speak_process(response)
history.append({'role': 'assistant', 'content': response})
return response
# Gradio インターフェースを設定
demo = gr.Interface(
transcribe,
gr.Audio(sources=["microphone"], type="filepath"), # マイクからの入力を受け取る
"text", # 出力はテキスト形式
)
# アプリケーションを起動
demo.launch()
私は、voice_chat.pyという名前でファイルを保存しました。
python voice_chat.py で、指定されたhttp://127.0.0.1:7860をブラウザで開けると、以下のような画面がでてきます。(MICの利用許可が求められますので許可してください。)

左の赤い「Record」を押してから、喋ってから、同じ場所のストップを押してください。それから、「Submit」を押すと、mlx-whisperが文字起こしをした入力文が、llmに渡されて、応答がSiriの音声で喋ります。また応答文章は以下の画面の右側のように文字でも表示されます。
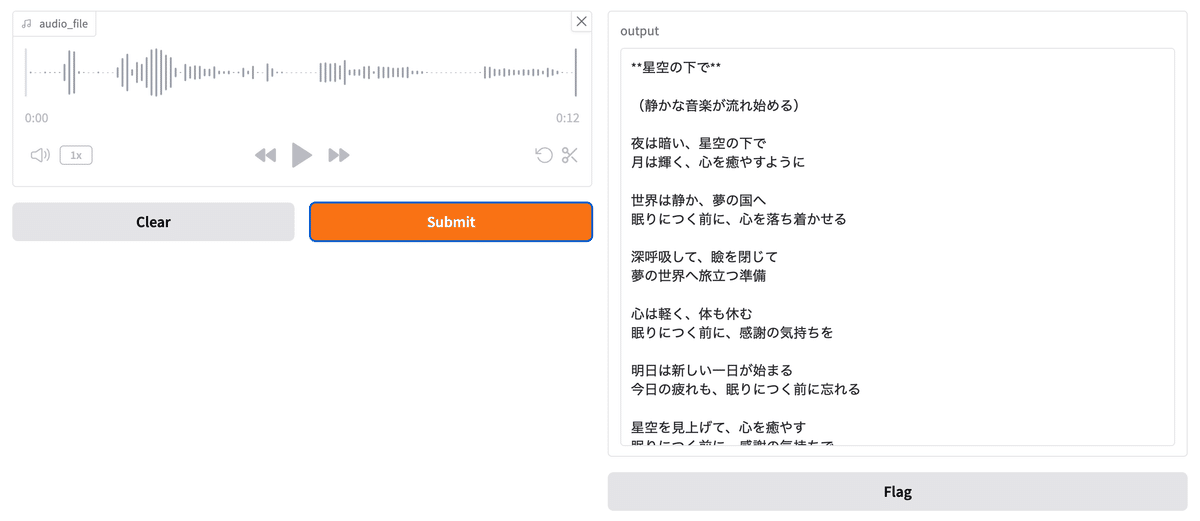
不勉強でわかりませんが、右下の Flag はなんのボタンかはわかりません。
自分が喋った言葉はそのまま左側に録音されて残っていますので、次の言葉を喋る時には、「Clear」を押してから再度「録音」してという手続きになります。
ちょっと面倒なので、この辺りはまた考えたいと思っています。
いいなと思ったら応援しよう!
